Redis追本溯源(四)集群:主从模式、哨兵模式、cluster模式
文章目录
- 一、主从模式
-
- 1.主从复制——全量复制
- 2.主从复制——增量复制
- 二、哨兵模式
-
- 1.实时监控与故障转移
- 2.Sentinel选举领导者
- 三、cluster模式
-
- 1.三种分片方案
- 2.cluster模式
Redis 有多种集群搭建方式,比如,主从模式、哨兵模式、Cluster 模式。
一、主从模式
Redis 主从模式还解决了单点的问题。Redis 主库在进行修改操作的时候,会把相应的写入命令近乎实时地同步给从库,从库回放这些命令,就可以保证自己的数据与主库保持一致。那么,当主库发生宕机的时候,我们就可以将一个从库升级为主库继续提供服务;当一个从库宕机的时候,主库依旧可以处理写请求,其他从库依旧可以支持读请求,所以并不会影响整个 Redis 服务的读写。所以说,Redis 主从模式解决了 Redis 单点的问题。
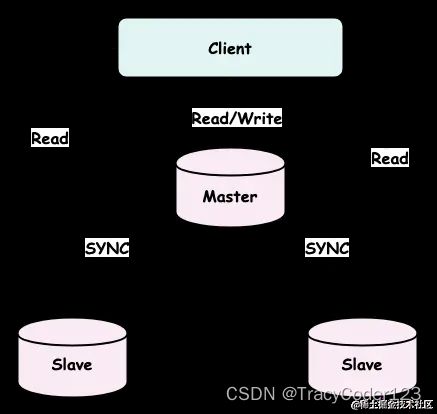
1.主从复制——全量复制

2.主从复制——增量复制
主从复制的增量复制底层实现原理如下:
主节点的命令传播: 当主节点接收到客户端的写入命令(如SET、DEL等)时,会将这些命令先记录在自己的AOF文件和内存中,然后将这些命令逐个发送给所有连接的从节点。
命令传输到从节点: 主节点通过网络将写入命令发送给从节点,从节点收到命令后先保存在自己的缓冲区中。
从节点的执行: 从节点在空闲时,会从缓冲区中取出保存的命令,并按照主节点发送的顺序逐个执行这些命令。这样,从节点的数据状态会逐步与主节点保持一致。
初始复制和部分复制: 当从节点刚刚与主节点建立连接时,会进行初始复制,主节点会将自己的整个数据集发送给从节点。在初始复制完成后,从节点会继续接收主节点的增量命令,进行部分复制。
心跳检测: 主节点会周期性地向从节点发送心跳消息,以检测从节点的状态。如果从节点在一定时间内没有回应心跳消息,主节点会认为从节点下线,并将其标记为断线状态。
断线重连: 当从节点重新连接主节点时,主节点会根据从节点断线前的复制偏移量,发送增量命令给从节点,以确保数据的连续性。
通过增量复制,主节点只需要传输写入命令而不是整个数据集,大大减少了复制过程中的网络传输开销。从节点通过执行主节点的写入命令来更新自己的数据,实现了数据的同步和一致性。主从复制的增量复制是一种异步复制方式,所以主节点和从节点之间可能会存在一定的数据延迟,但它提供了高可用性和横向扩展的能力。
二、哨兵模式
一个 Sentinel 服务进程其实本身就是 Redis 实例,只不过这个 Redis 服务实例是以 Sentinel 模式运行的,它不对外提供读写键值对的服务,而是监控其他 Redis 服务实例是否运行正常,有点类似现实生活中监工的感觉。
为了防止 Sentinel 本身出现单点问题,一般会将多个 Sentinel 实例组成一个 Sentinel 集群。Sentinel 核心功能是监控线上 Redis 实例的状态,当发现某个主库故障的时候,Sentinel 会自动将故障的主库下线,然后从剩余的从库中选出一个合适的从库,提升为新一任主库,继续对外提供服务。
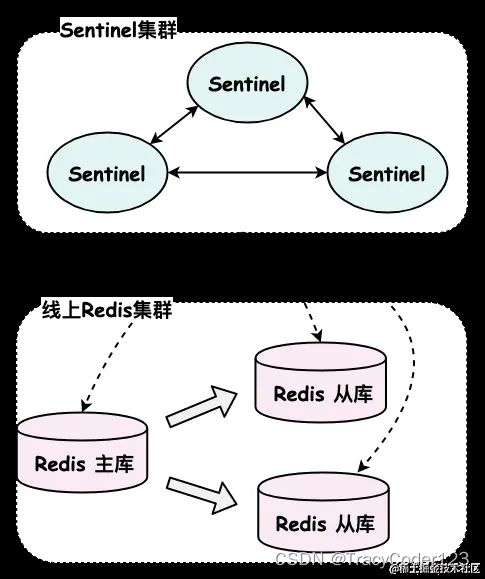
Sentinel 有选举的操作,所以一般推荐 Sentinel 集群的实例个数为奇数。
一个 Sentinel 集群可以监控多个 Redis 主从集群。
1.实时监控与故障转移
Redis Sentinel实现实时监控与故障转移的底层原理如下:
-
1. 实时监控:
- 定期检查:每个Redis Sentinel节点定期向被监控的Redis主从节点发送PING命令,以检查节点是否在线。同时,Sentinel还会使用INFO命令获取节点的运行状态信息,包括主节点的复制偏移量、从节点复制状态等。
- 主观下线:如果一个Sentinel节点在多次检查中无法连接到主节点或从节点,它会将该节点标记为“主观下线”。这表示该Sentinel认为节点可能出现了故障,但并不是确定性的。
- 共识达成:Sentinel集群中的多个Sentinel会进行共识达成,即判断节点是否真正宕机。当超过半数Sentinel认为某个节点处于主观下线状态时,该节点会被标记为“客观下线”。
-
2. 故障转移:
- 客观下线:一旦一个主节点被标记为“客观下线”,说明多数Sentinel都认为该主节点处于故障状态,故障转移过程会开始。
- 领导者选举:在Sentinel集群中,会通过选举机制选出一个Sentinel领导者。领导者负责协调整个Sentinel集群的监控工作和故障转移过程。
- 选举新的主节点:当主节点被标记为“客观下线”时,Sentinel集群会重新选举一个从节点作为新的主节点。这个过程是通过选举机制和投票来实现的,最终选出一个从节点作为新的主节点。
- 切换从节点:一旦新的主节点选出,其他从节点会切换到新的主节点上,使得整个Redis集群恢复到正常的主从复制状态。
通过实时监控和故障转移,Redis Sentinel实现了高可用性,即使主节点出现故障,也能够快速选举新的主节点并恢复服务,保证了Redis集群的可用性和稳定性。这种机制允许Redis Sentinel对节点的状态进行实时监控,并自动进行故障转移,无需人工干预,提高了系统的自动化和可靠性。
2.Sentinel选举领导者
Redis Sentinel中领导者的选举是通过Raft算法实现的。Raft是一种一致性算法,用于在分布式系统中选举领导者,并确保所有节点达成一致的共识。在Redis Sentinel中,通过Raft算法选举领导者来实现Sentinel集群的协调和故障转移。
Redis Sentinel的领导者选举过程如下:
-
候选者(Candidate)状态:在Sentinel集群中,所有Sentinel节点都可以成为候选者。当一个节点启动时,它会进入候选者状态,并向其他节点发送选举请求。
-
提名和投票:候选者向其他节点发送选举请求,并提名自己作为领导者。收到选举请求的节点可以投票赞成候选者,也可以拒绝投票。每个节点只能投一票,并在收到多数节点的赞成票后成为领导者。
-
选举过程:当一个节点成为候选者后,它会等待其他节点的投票响应。如果候选者收到多数节点的赞成票,它就会成为领导者。否则,如果候选者在一定时间内没有收到足够的赞成票,它会放弃选举,重新进入候选者状态。
-
防止分裂:为了防止在网络分区等情况下出现多个领导者,Redis Sentinel使用了Raft算法的领导者选举机制。在选举过程中,如果出现多个候选者同时成为领导者,它们会通过心跳机制来进行竞争,最终只有一个领导者能够稳定下来。
心跳机制是Raft算法中用于维持领导者与跟随者之间联系和状态同步的机制。一旦某个候选者成为领导者后,它会周期性地发送心跳消息给其他节点,其他节点会收到心跳消息后回复确认消息,表示它们承认该候选者为领导者。如果其他候选者没有得到多数节点的赞成票或在选举过程中没有成为领导者,它们会继续参与领导者的心跳竞争,但由于没有得到多数节点的确认,它们最终不会稳定地成为领导者。
-
领导者维持:一旦选举产生领导者,该领导者负责协调整个Sentinel集群的监控和故障转移工作。如果领导者节点宕机或离线,其他节点会重新进行领导者选举,选出新的领导者来代替。
通过Raft算法的领导者选举机制,Redis Sentinel确保了在分布式环境中选举出稳定的领导者,从而保证了Sentinel集群的协调和故障转移的可靠性和一致性。
三、cluster模式
Redis 主从复制可以实现读写分离,Redis Sentinel 模式可以实现自动故障转移,解决了 Redis 主从复制模式的高可用问题,看起来是个非常美好的方案。但 Sentinel 还是存在一个问题,那就是横向扩展问题。

在面对海量数据的时候,我们无法使用一个 Redis Master 存储全部数据,此时就需要一套分布式存储方案将数据进行切分,每个 Redis 主从复制组只存储一部分数据,这样就可以通过增加机器的方式增加 Redis 服务的整体存储能力。
1.三种分片方案
客户端分片、代理层分片以及 Redis Cluster 都是用于实现 Redis 数据分片(Sharding)的方法。
-
客户端分片:
- 原理:在客户端分片中,应用程序自行实现数据分片逻辑。客户端根据某种规则(如哈希函数、范围等)将数据分散到不同的 Redis 节点。客户端需要维护一张分片映射表,来决定每个键应该存储在哪个 Redis 节点上。
- 优点:实现简单,应用程序可以根据业务需求定制化分片逻辑。
- 缺点:增加了客户端的开发和维护复杂性,对于节点动态增减等情况需要手动处理数据迁移。
-
代理层分片:
- 原理:在代理层分片中,应用程序通过使用分片代理作为中间层,将数据的读写请求转发给不同的 Redis 节点。代理层维护了分片映射表,根据键的哈希值或范围来路由请求到相应的 Redis 节点。
- 优点:客户端无需关心分片逻辑,简化了应用程序的实现,代理层处理了数据路由和节点动态增减的问题。
- 缺点:引入了额外的网络开销和代理层的维护成本。
-
Redis Cluster:
- 原理:Redis Cluster 是 Redis 官方提供的分布式解决方案,基于一致性哈希算法进行数据分片。Redis Cluster 使用一致性哈希分片的方式将数据分布到不同的 Redis 节点上,并通过 Gossip 协议实现节点之间的信息交换和故障检测。
- 优点:实现简单,自动处理数据迁移和节点动态增减,支持高可用性,可以容忍部分节点的故障。
- 缺点:某些特殊场景下可能存在数据热点问题,对于大规模的集群可能需要引入虚拟节点技术。
Redis Cluster 是推荐的 Redis 分片解决方案,它提供了较好的性能、可靠性和扩展性,同时简化了开发和维护工作。客户端分片和代理层分片则更适用于一些特殊场景或自定义需求。
2.cluster模式
Redis Cluster 是 Redis 官方提供的分布式解决方案,用于将数据分布在多个节点上,实现数据的高可用性和横向扩展。其底层原理主要包括以下几个方面:
-
一致性哈希分片:
- Redis Cluster 使用一致性哈希算法将键(Key)映射到一个固定大小的哈希槽(slot)上。Redis Cluster 中一共有 16384 个哈希槽,每个节点负责一部分槽的数据。根据键的哈希值,集群中的每个节点都能确定应该接管哪些槽的数据。
-
节点通信与故障检测:
- Redis Cluster 中的每个节点都与其他节点保持持续的通信,使用 Gossip 协议进行信息交换。节点之间通过发送 PING、PONG 消息来检测对方是否在线,从而实现故障检测。
- 当一个节点发现另一个节点不可用(无法收到 PING 回复),它会将该节点标记为下线,然后通过集群中其他节点来确认故障。一旦多个节点都确认某个节点下线,Redis Cluster 就会进行故障转移,选举一个新的主节点来接管失效节点的哈希槽。
-
主从复制:
- Redis Cluster 中的每个主节点都可以有多个从节点。主从复制机制用于保障数据的冗余和高可用性。
- 当一个主节点下线时,它的一个从节点会被晋升为新的主节点,继续处理客户端请求。这样可以确保数据的持久性和高可用性。
-
数据迁移:
- Redis Cluster 允许节点动态增减。当新增节点加入集群时,其他节点会将一部分哈希槽的数据迁移到新节点上,以平衡负载。
- 数据迁移通过异步传输(开启一个子线程),源节点将数据发送给目标节点,并在数据迁移完成后,确认数据同步成功。在数据迁移过程中,不会停止处理客户端请求。
-
客户端路由:
- 客户端通过连接到任意一个节点来访问整个 Redis Cluster。当客户端发送请求时,节点会根据键的哈希值来路由请求到相应的节点,从而保证数据的一致性。
Redis Cluster 的底层原理主要依赖于一致性哈希分片和节点之间的通信与协作。它通过集群中多个节点的协作来实现数据的高可用性和分布式存储。在集群中节点的动态增减、数据迁移和故障转移等过程都是自动化的,使得 Redis Cluster 成为一个高性能、高可用性的分布式数据库解决方案。