尚硅谷大数据项目《在线教育之采集系统》笔记003
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili
目录
P036
P037
P038
P039
P041
P042
P043
P044
P045
P046
P036
先启动zookeeper,在启动kafka,启动hadoop中的hdfs
node003启动flume,node001启动flume,node001启动mock.sh。
P037
数据漂移
数据传输流程:生成数据——>flume——>kafka——>flume——>hdfs。
hdfs落盘默认使用header头的默认时间戳timesamp,修改header头就能修改时间戳。
P038
TimestampInterceptor:解决时间戳问题的拦截器。
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimestampInterceptor$Builder
## 1、定义组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
## 2、配置sources
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = node001:9092,node002:9092,node003:9092
a1.sources.r1.kafka.consumer.group.id = topic_log
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.batchSize = 1000
a1.sources.r1.batchDurationMillis = 1000
a1.sources.r1.useFlumeEventFormat = false
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimestampInterceptor$Builder
## 3、配置channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/flume-1.9.0/checkpoint/behavior1
a1.channels.c1.useDualCheckpoints = false
a1.channels.c1.dataDirs = /opt/module/flume/flume-1.9.0/data/behavior1/
a1.channels.c1.capacity = 1000000
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.keep-alive = 3
## 4、配置sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/edu/log/edu_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 5、组装 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic topic_log
P039
/home/atguigu/bin
-----------------------------------------------------------
#! /bin/bash
case $1 in
"start") {
echo " --------消费flume启动-------"
ssh node003 "nohup /opt/module/flume/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume/flume-1.9.0/conf/ -f /opt/module/flume/flume-1.9.0/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
};;
"stop") {
echo " --------消费flume关闭-------"
ssh node003 "ps -ef | grep kafka_to_hdfs_log | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
};;
esac
P041
P042
本项目中,全量同步采用DataX,增量同步采用Maxwell。
P043
- https://github.com/alibaba/DataX
- https://github.com/alibaba/DataX/blob/master/introduction.md
P044
[atguigu@node001 datax]$ cd /opt/module/datax/
[atguigu@node001 datax]$ python bin/datax.py -r mysqlreader -w hdfswriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the mysqlreader document:
https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md
Please refer to the hdfswriter document:
https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
[atguigu@node001 datax]$ P045
/opt/module/datax/job/base_province.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"region_id",
"area_code",
"iso_code",
"iso_3166_2"
],
"where": "id>=3",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://node001:3306/edu2077"
],
"table": [
"base_province"
]
}
],
"password": "000000",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://node001:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
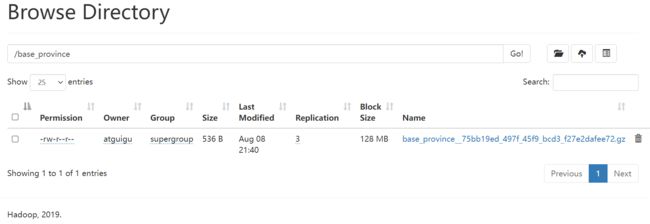
"path": "/base_province",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
2023-08-08 21:40:16.749 [job-0] INFO JobContainer -
任务启动时刻 : 2023-08-08 21:39:59
任务结束时刻 : 2023-08-08 21:40:16
任务总计耗时 : 17s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0
[atguigu@node001 datax]$ hadoop fs -cat /base_province/base_province__75bb19ed_497f_45f9_bcd3_f27e2dafee72.gz | zcat
2023-08-08 21:42:28,250 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
3 山西 1 140000 CN-14 CN-SX
4 内蒙古 1 150000 CN-15 CN-NM
5 河北 1 130000 CN-13 CN-HE
6 上海 2 310000 CN-31 CN-SH
7 江苏 2 320000 CN-32 CN-JS
8 浙江 2 330000 CN-33 CN-ZJ
9 安徽 2 340000 CN-34 CN-AH
10 福建 2 350000 CN-35 CN-FJ
11 江西 2 360000 CN-36 CN-JX
12 山东 2 370000 CN-37 CN-SD
13 重庆 6 500000 CN-50 CN-CQ
14 台湾 2 710000 CN-71 CN-TW
15 黑龙江 3 230000 CN-23 CN-HL
16 吉林 3 220000 CN-22 CN-JL
17 辽宁 3 210000 CN-21 CN-LN
18 陕西 7 610000 CN-61 CN-SN
19 甘肃 7 620000 CN-62 CN-GS
20 青海 7 630000 CN-63 CN-QH
21 宁夏 7 640000 CN-64 CN-NX
22 新疆 7 650000 CN-65 CN-XJ
23 河南 4 410000 CN-41 CN-HA
24 湖北 4 420000 CN-42 CN-HB
25 湖南 4 430000 CN-43 CN-HN
26 广东 5 440000 CN-44 CN-GD
27 广西 5 450000 CN-45 CN-GX
28 海南 5 460000 CN-46 CN-HI
29 香港 5 810000 CN-91 CN-HK
30 澳门 5 820000 CN-92 CN-MO
31 四川 6 510000 CN-51 CN-SC
32 贵州 6 520000 CN-52 CN-GZ
33 云南 6 530000 CN-53 CN-YN
34 西藏 6 540000 CN-54 CN-XZ
[atguigu@node001 datax]$
P046
/opt/module/datax/job/base_province_sql.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/edu2077"
],
"querySql": [
"select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"
]
}
],
"password": "000000",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
"path": "/base_province",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}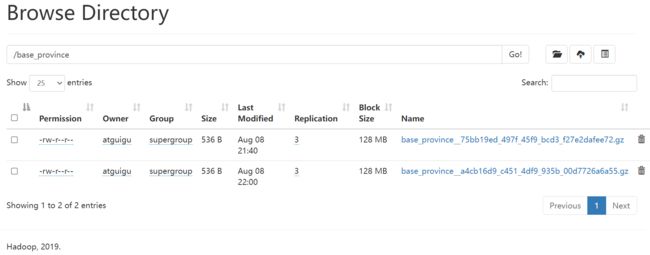
[atguigu@node001 datax]$ bin/datax.py job/base_province_sql.json
2023-08-08 22:00:47.596 [job-0] INFO JobContainer - PerfTrace not enable!
2023-08-08 22:00:47.597 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.001s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-08-08 22:00:47.600 [job-0] INFO JobContainer -
任务启动时刻 : 2023-08-08 22:00:33
任务结束时刻 : 2023-08-08 22:00:47
任务总计耗时 : 14s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0
[atguigu@node001 datax]$