彻底搞明白YARN资源分配
彻底搞明白YARN资源分配
本篇要解决的问题是:
- Container是以什么形式运行的?是单独的JVM进程吗?
- YARN的vcore和本机的CPU核数关系?
- 每个Container能够使用的物理内存和虚拟内存是多少?
- 一个NodeManager可以分配多少个Container?
- 一个Container可以分配的最小内存是多少?最大内存内存是多少?以及最小、最大的VCore是多少?
- 当将Spark程序部署在YARN上, AM与Driver的关系是什么?
- Spark on YARN,一个Container可以运行几个executor?executor设置的内存和container的关系是什么?
YARN资源管理简述
分布式应用在YARN中的执行流程
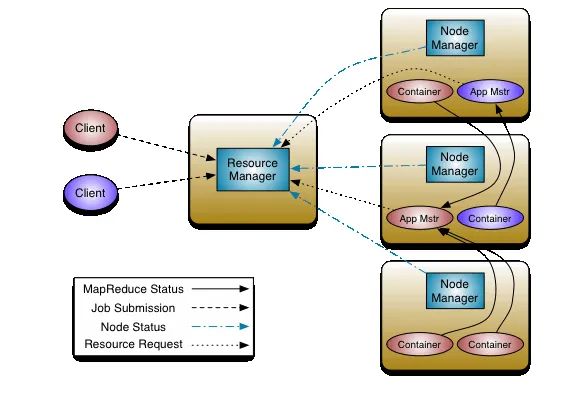
这张图是YARN的经典任务执行流程图。可以发现上图中有5类角色:
- Client
- Resource Manager
- Node Manager
- Application Master
- Container
先简单来梳理提交任务的流程。
- 要将应用程序(MapReduce/Spark/Flink)程序运行在YARN集群上,先得有一个用于将任务提交到作业的客户端,也就是client。它向Resource Manager(RM)发起请求,RM会为提交的作业生成一个JOB ID。此时,JOB的状态是:NEW
- 客户端继续将JOB的详细信息提交给RM,RM将作业的详细信息保存。此时,JOB的状态是:SUBMIT
- RM继续将作业信息提交给scheduler(调度器),调度器会检查client的权限,并检查要运行Application Master(AM)对应的queue(默认:default queue)是否有足够的资源。此时,JOB的状态是ACCEPT。
- 接下来RM开始为要运行AM的Container资源,并在Container上启动AM。此时,JOB的状态是RUNNING
- AM启动成功后,开始与RM协调,并向RM申请要运行程序的资源,并定期检查状态。
- 如果JOB按照预期完成。此时,JOB的状态为FINISHED。如果运行过程中出现故障,此时,JOB的状态为FAILED。如果客户端主动kill掉作业,此时,JOB的状态为KILLED。
YARN集群资源管理
集群总计资源
要想知道YARN集群上一共有多少资源很容易,我们通过YARN的web ui就可以直接查看到。

通过查看Cluster Metrics,可以看到总共的内存为24GB、虚拟CPU核为24个。我们也可以看到每个NodeManager的资源。很明显,YARN集群中总共能使用的内存就是每个NodeManager的可用内存加载一起,VCORE也是一样。
NodeManager总计资源
NodeManager的可用内存、可用CPU分别是8G、和8Core。这个资源和Linux系统是不一致的。我们通过free -g来查看下Linux操作系统的总计内存、和CPU核。
第一个节点(总计内存是10G,空闲的是8G)
[root@node1 hadoop]# free -h total used free shared buff/cache availableMem: 9.6G 1.6G 7.6G 12M 444M 7.8GSwap: 2.0G 0B 2.0G
第二个节点(总计内存是7G,空闲是不到6G)
[root@node2 hadoop]# free -h total used free shared buff/cache availableMem: 6.6G 700M 5.6G 12M 383M 5.7GSwap: 2.0G 0B 2.0G
第三个节点(和第二个节点一样)
[root@node3 logs]# free -h total used free shared buff/cache availableMem: 6.6G 698M 5.6G 12M 386M 5.7GSwap: 2.0G 0B 2.0G
这说明了,NodeManager的可用内存和操作系统总计内存是没有直接关系的!
那NodeManager的可用内存是如何确定的呢?
在yarn-default.xml中有一项配置为:yarn.nodemanager.resource.memory-mb,它的默认值为:-1(hadoop 3.1.4)。我们来看下Hadoop官方解释:
Amount of physical memory, in MB, that can be allocated for containers. If set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically calculated(in case of Windows and Linux). In other cases, the default is 8192MB.
这个配置是表示NodeManager总共能够使用的物理内存,这也是可以给container使用的物理内存。如果配置为-1,且yarn.nodemanager.resource.detect-hardware-capabilities配置为true,那么它会根据操作的物理内存自动计算。而yarn.nodemanager.resource.detect-hardware-capabilities默认为false,所以,此处默认NodeManager就是8G。这就是解释了为什么每个NM的可用内存是8G。
还有一个重要的配置:yarn.nodemanager.vmem-pmem-ratio,它的默认配置是2.1
Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.
这个配置是针对NodeManager上的container,如果说某个Container的物理内存不足时,可以使用虚拟内存,能够使用的虚拟内存默认为物理内存的2.1倍。
针对虚拟CPU核数,也有一个配置yarn.nodemanager.resource.cpu-vcores配置,它的默认配置也为-1。看一下Hadoop官方的解释:
Number of vcores that can be allocated for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of CPUs used by YARN containers. If it is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically determined from the hardware in case of Windows and Linux. In other cases, number of vcores is 8 by default.
与内存类似,它也有一个默认值:就是8。
这就解释了为什么每个NodeManager的总计资源是8G和8个虚拟CPU核了。
scheduler调度资源
通过YARN的webui,点击scheduler,我们可以看到的调度策略、最小和最大资源分配。

通过web ui,我们可以看到当前YARN的调度策略为容量调度。调度资源的单位是基于MB的内存、和Vcore(虚拟CPU核)。最小的一次资源分配是:1024M(1G)和1个VCORE。最大的一次分配是:4096M(4G)和4个VCORE。注意:内存资源和VCORE都是以Container承载的。
我们来看一下yarn-default.xml的配置。
| 配置项 | 默认 | 说明 |
|---|---|---|
| yarn.scheduler.minimum-allocation-mb | 1024 | 该配置表示每个容器的最小分配。因为RM是使用scheduler来进行资源调度的,如果请求的资源小于1G,也会设置为1G。这表示,如果我们请求一个256M的container,也会分配1G。 |
| yarn.scheduler.maximum-allocation-mb | 8192 | 最大分配的内存,如果比这个内存高,就会抛出InvalidResourceRequestException异常。这里也就意味着,最大请求的内存不要超过8G。上述截图显示是4G,是因为我在yarn-site.xml中配置了最大分配4G。 |
| yarn.scheduler.minimum-allocation-vcores | 1 | 同内存的最小分配 |
| yarn.scheduler.maximum-allocation-vcores | 4 | 同内存的最大分配 |
Container总计资源
在YARN中,资源都是通过Container来进行调度的,程序也是运行在Container中。Container能够使用的最大资源,是由scheduler决定的。如果按照Hadoop默认配置,一个container最多能够申请8G的内存、4个虚拟核。例如:我们请求一个Container,内存为3G、VCORE为2,是OK的。考虑一个问题:如果当前NM机器上剩余可用内存不到3G,怎么办?此时,就会使用虚拟内存。不过,虚拟内存,最多为内存的2.1倍,如果物理内存 + 虚拟内存仍然不足3G,将会给container分配资源失败。
根据上述分析,如果我们申请的container内存为1G、1个VCORE。那么NodeManager最多可以运行8个Container。如果我们申请的container内存为4G、4个vcore,那么NodeManager最多可以运行2个Container。
Container是一个JVM进程吗
这个问题估计有很多天天在使用Hadoop的人都不一定知道。当向RM请求资源后,会在NodeManager上创建Container。问题是:Container是不是有自己独立运行的JVM进程呢?还是说,NodeManager上可以运行多个Container?Container和JVM的关系是什么?
此处,明确一下,每一个Container就是一个独立的JVM实例。(此处,咱们不讨论Uber模式)。每一个任务都是在Container中独立运行,例如:MapTask、ReduceTask。当scheduler调度时,它会根据任务运行需要来申请Container,而每个任务其实就是一个独立的JVM。
为了验证此观点,我们来跑一个MapReduce程序。然后我们在一个NodeManager上使用JPS查看一下进程:(这是我处理过的,不然太长了,我们主要是看一下内存使用量就可以了)
[root@node1 ~]# jps -v22560 YarnChild -Xmx820m 22667 YarnChild -Xmx820m[root@node2 hadoop]# jps -v10224 MRAppMaster -Xmx1024m[root@node3 logs]# jps -v10305 YarnChild -Xmx820m
我们看到了有MRAppMaster、YarnChild这样的一些Java进程。这就表示,每一个Container都是一个独立运行的JVM,它们彼此之间是独立的。
Spark on YARN资源管理
通常,生产环境中,我们是把Spark程序在YARN中执行。而Spark程序在YARN中运行有两种模式,一种是Cluster模式、一种是Client模式。这两种模式的关键区别就在于Spark的driver是运行在什么地方。如果运行模式是Cluster模式,Driver运行在Application Master里面的。如果是Client模式,Driver就运行在提交spark程序的地方。Spark Driver是需要不断与任务运行的Container交互的,所以运行Driver的client是必须在网络中可用的,知道应用程序结束。
这两幅图描述得很清楚。
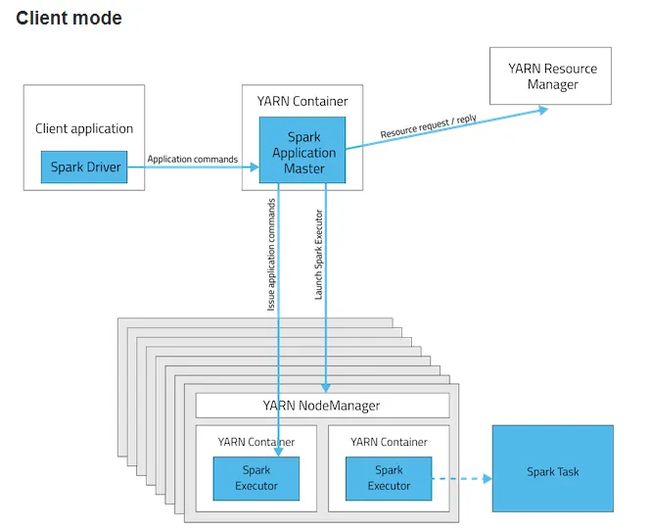
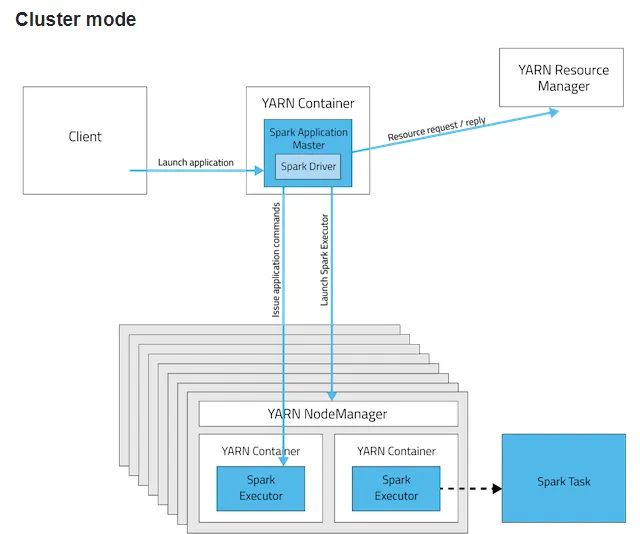
留意一下Driver的位置。
通过上面的分析,我们可以明确,如果是Client模式,Driver和ApplicationMaster运行在不同的地方。ApplicationMaster运行在Container中,而Driver运行在提交任务的client所在的机器上。
因为如果是Standalone集群,整个资源管理、任务执行是由Master和Worker来完成的。而当运行在YARN的时候,就没有这两个概念了。资源管理遵循YARN的资源调度方式。之前在Standalone集群种类,一个worker上可以运行多个executor,现在对应的就是一个NodeManager上可以运行多个container,executor的数量跟container是一致的。可以直接把executor理解为container。
我们再来看看spark-submit的一些参数配置。
[root@c5836fa7593c /]# spark-submit --help
Usage: spark-submit [options] | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
配置选项中,有一个是公共配置,还有一些针对spark-submit运行在不同的集群,参数是不一样的。
公共的配置:
–driver-memory、–executor-memory,这是我们可以指定spark driver以及executor运行所需的配置。executor其实就是指定container的内存,而driver如果是cluster模式,就是application master的内置,否则就是client运行的那台机器上申请的内存。
如果运行在Cluster模式,可以指定driver所需的cpu core。
如果运行在Spark Standalone,–total-executor-cores表示一共要运行多少个executor。
如果运行在Standalone集群或者YARN集群,–executor-cores表示每个executor所需的cpu core。
如果运行在yum上,–num-executors表示要启动多少个executor,其实就是要启动多少个container。
Flink on YARN资源管理

Flink在YARN上也有两种模式:一种是yarn-session、还有一个是yarn-per-job。
YARN session模式比较有意思,相当于在YARN集群中基于Container运行一套Flink集群。Container有JobManager角色、还有TaskManager角色。然后客户端可以不断地往这套运行在YARN上的Flink Cluster提交作业。
./yarn-session.sh -n 4 -s 8 -jm 3072 -tm 32768
上面这个命令表示,在YARN上分配4个Container,每个Container上运行TaskManager,每个TaskManager对应8个vcore,每个TaskManager 32个G。这就要求YARN上scheduler分配Container最大内存要很大,否则根本无法分配这么大的内存。这种模式比较适合做一些交互性地测试。
第二种模式yarn-per-job,相当于就是单个JOB提交的模式。同样,在YARN中也有JobManager和TaskManager的概念,只不过当前是针对一个JOB,启动则两个角色。JobManager运行在Application Master上,负责资源的申请。
flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 3072 -ys 3 -ynm yarn-cluster-1 -yqu root.default -c com.kn.rt.Test01 ~/jar/dw-1.0-SNAPSHOT.jar
上述命令表示,运行两个TaskManager(即2个Container),job manager所在的container是1G内存、Task Manager所在的Container是3G内存、每个TaskManager使用3个vcore。
总结
如果你认真看完了,很轻易地就能回答下面的问题:
- Container是以什么形式运行的?是单独的JVM进程吗?
是的,每一个Container就是一个单独的JVM进程。
- YARN的vcore和本机的CPU核数关系?
没关系。默认都是手动在yarn-default.xml中配置的,默认每个NodeManager是8个vcore,所有的NodeManager上的vcore加在一起就是整个YARN所有的vcore。
- 每个Container能够使用的物理内存和虚拟内存是多少?
scheduler分配给container多少内存就是最大能够使用的物理内存,但如果超出该物理内存,可以使用虚拟内存。虚拟内存默认是物理内存的2.1倍。
- 一个NodeManager可以分配多少个Container?
这个得看Container的内存大小和vcore数量。用NM上最大的可用Mem和Vcore相除就知道了。
- 一个Container可以分配的最小内存是多少?最大内存内存是多少?以及最小、最大的VCore是多少?
根据scheduler分配的最小/最大内存、最小/最大vcore来定。
- 当将Spark程序部署在YARN上, AM与Driver的关系是什么?
有两种模式,cluster模式,Driver就运行在AM上。如果是client模式,没关系。
- Spark on YARN,一个Container可以运行几个executor?executor设置的内存和container的关系是什么?
一个container对应一个executor。executor设置的内存就是AM申请的container内存,如果container最小分配单位是1G,而executor设置的内置是512M,按照container最小单位分配。

不管开发Hive、Spark还是Flink,都必须会的YARN调度
目前,YARN调度几乎成为大数据平台资源管理的标配,不管你跑的是Hive、跑的是Spark或者是Flink,基本都会选择YARN。Hadoop默认是使用FIFO的方式,在一个Queue中进行调度,这种方式对于粗粒度的资源管控、或者是小规模用户来说可能适用,但对于规模稍微大一点的集群肯定是不可取的。大家可以去网上随便搜索YARN调度的教程,大家都在讲概念,例如:弹性资源、抢占。但能够真正带大家去测试一下的教程几乎没有。我所面试的候选人,面试10个有8个基本上这一块都是模棱两可,背概念可以,但一问生产环境的调配,基本上都说不上来。
所以,今天我手把手带大家来聊聊调度,并直接调参跑作业给大家演示两种调度器弹性扩展、资源抢占、优先级权重等。
-
FIFO调度
-
Capacity Scheduler
-
- 简介
- 容量调度配置文件
- root队列
- 配置更多的队列
- Queue Properties
- 应用程序优先级
- Capacity Scheduler容器抢占
- 需求及实现
-
FAIR Scheduler
-
- 简介
- 可插拔的分层队列
- 队列调度策略
- 自动分发作业到队列
- 配置使用Fair Scheduler
- 配置选项
- 需求及实现
-
对比两种资源调度策略
FIFO调度
FIFO(‘faifəu,不要念错啦!)代表的是First In First Out,即先进先出。Job Scheduler首先会从队列中找到最早提交的作业,不考虑优先级、以及资源的大小,按照FIFO顺序运行作业。
这种调度策略比较简单,但它有比较明显的缺点:调度大作业尚可,但如果集群中有一些小作业,响应时间会很差。另外,如果针对组织机构比较复杂的用户,这种方式对资源的控制粗狂型的,不利于更细粒度的资源管控。
基于此,我们要来聊一聊另外一种非常流行、使用广泛的Capacity Scheduler,即容量调度。
Capacity Scheduler
简介
YARN默认的调度器为 Capacity Scheduler,也就是容量调度器。可以通过yarn-default.xml中看到。

CapacityScheduler提供的主要抽象是队列。队列通常由管理员提前配置好。CapacityScheduler还支持分层队列,可以做更细粒度的资源划分。
Capacity Scheduler支持以下功能:
-
分层队列
-
- 允许在不同队列中共享计算资源
-
容量保证
-
- YARN的计算资源使用队列进行网格化,管理员可以为每个队列指定容量限制(支持软限制和硬限制)
-
安全访问
-
- 每个队列都有严格的ACL,以此来控制哪些用户可以提交应用到队列
- 可以做到不同的用户队列隔离,A用户是不能看到或者修改B用户的应用程序的
- 还可以为每个队列配置管理员
-
弹性扩展
-
- 如果某些队列超出其容量了,可以弹性地分配其他可用的资源给它们。而如果资源已经使用完了(例如:Spark程序执行完了),可以继续分配给其他容量不足的队列
-
多租户
-
- 提供完整的限制,避免某个应用程序把集群资源占满
-
维护方便
-
- 支持运行时配置:管理员可以在运行时更改队列配置(包括容量、ACL),注意,除非队列停止或者没有运行着的应用程序,否则无法在运行时删除队列
- 优雅停止调度:管理员可在运行时停止队列,可以确保当前的应用运行完毕后停止,期间不能提交新的应用程序。
- 基于资源的调度:支持资源密集型应用,应用程序可以指定比默认值更高的资源请求,适应不同资源要求的应用程序。
- 支持自定义队列映射规则:用户可以根据默认配置将作业映射到指定队列。例如:基于用户、或者基于组、或者应用程序的名称。当然,用户也可以自己来定义映射规则。
-
可配置优先级
-
- 可以以不同的优先级提交、调度作业。整数值越大,表示应用程序的优先级越高。目前,只有FIFO排序策略支持优先级。
-
绝对资源配置
-
- 可以为队列配置绝对资源,而不是配置百分比。
-
自动创建和管理Leaf Queue
-
- Queue Mapping当前支持基于用户-组Mapping Policy。
容量调度配置文件
# CapacityScheduler的配置文件为:
${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml
配置文件内容如下:
yarn.scheduler.capacity.maximum-applications
10000
能够调度的最大应用程序数量(包含pending的running的应用)
yarn.scheduler.capacity.maximum-am-resource-percent
0.1
AM最大能够使用的资源大小。为整个集群资源的百分比
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
资源计算器,DefaultResourceCalculator只基于内存进行资源计算
yarn.scheduler.capacity.root.queues
default
配置root queue
yarn.scheduler.capacity.root.default.capacity
100
配置Queue能够使用的容量(百分比)
yarn.scheduler.capacity.root.default.user-limit-factor
1
队列的限制因子(0.0-1.0)
yarn.scheduler.capacity.root.default.maximum-capacity
100
default queue的最大容量
yarn.scheduler.capacity.root.default.state
RUNNING
队列的状态(要么是RUNNING、要么是STOPPED)
yarn.scheduler.capacity.root.default.acl_submit_applications
*
default queue提交作业配置
yarn.scheduler.capacity.root.default.acl_administer_queue
*
default queue管理员配置
yarn.scheduler.capacity.root.default.acl_application_max_priority
*
提交带优先级作业配置
yarn.scheduler.capacity.root.default.maximum-application-lifetime
-1
提交作业到queue的最大时间,-1或者0表示不启用。单位为秒,如果配置的是正数,超过这个数值JOB将会被kill掉。用户也可以在提交作业时指定lifetime。
yarn.scheduler.capacity.root.default.default-application-lifetime
-1
默认lifetime
yarn.scheduler.capacity.node-locality-delay
40
调度器会优先调度同一个机架上的资源。如果配置为-1,表示不进行延迟调度。此处配置为40,表示如果scheduler错过40次机会后尝试在其他机架上调度。
yarn.scheduler.capacity.rack-locality-additional-delay
-1
机架额外的延迟调度等待。超过配置的数量,Scheduler将会尝试非统一交换机上的容器资源
yarn.scheduler.capacity.queue-mappings
队列映射,可以将某个用户提交的JOB映射到指定队列
yarn.scheduler.capacity.queue-mappings-override.enable
false
如果指定了Queue Mapping,是否允许用户指定配置。
yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments
1
增加该值可以提升OFF_SWICH容器的调度速度
yarn.scheduler.capacity.application.fail-fast
false
如果之前应用程序的Queue不再有效,RM是否在恢复时失败
root队列
Capacity Scheduler有一个已经创建好的root队列。YARN中配置的所有队列都是root队列的子队列。
配置更多的队列
在yarn.scheduler.capacity.root.queues节点中可以配置更多的队列。
yarn.scheduler.capacity.root.queues
default
分层队列
Capacity Scheduler使用Queue Path来配置队列的层次结构。Queue Path是Queue层次结构的完整路径,从root开始,以.作为分隔符。例如:
yarn.scheduler.capacity..queues
看一个配置:
yarn.scheduler.capacity.root.queues
a,b,c
yarn.scheduler.capacity.root.a.queues
a1,a2
yarn.scheduler.capacity.root.b.queues
b1,b2,b3

注意
- Leaf Queue名称必须唯一
更新Queue配置
当修改了capacity-scheduler.xml后,无需重启yarn集群,直接使用:
yarn rmadmin -refreshQueues
即可。
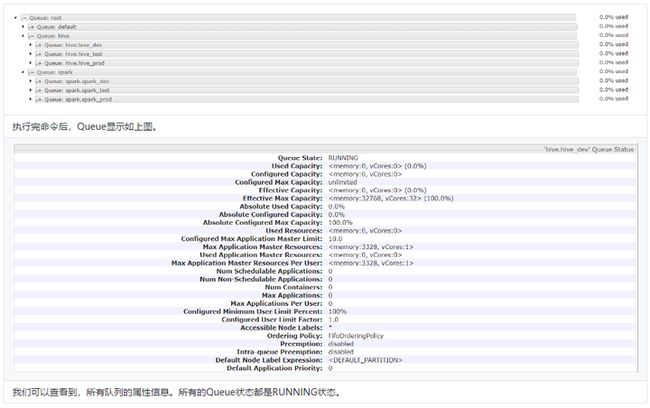
假设我们当前要添加以下几个Queue:
+-root
|-default
|-hive
|-hive_dev
|-hive_test
|-hive_prod
|-spark
|-spark_dev
|-spark_test
|-spark_prod
修改capacity-scheduler.xml配置文件:
yarn.scheduler.capacity.root.queues
default,hive,spark
yarn.scheduler.capacity.root.hive.queues
hive_dev,hive_test,hive_prod
yarn.scheduler.capacity.root.spark.queues
spark_dev,spark_test,spark_prod
修改完配置后,执行
yarn rmadmin -refreshQueues
停止使用队列
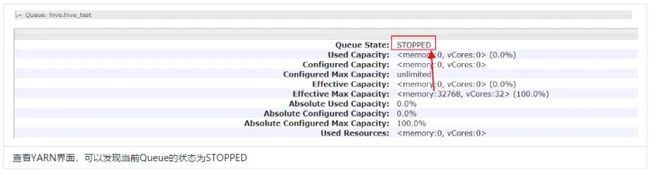
假如某个队列已经不需要使用了,也可以删除它。但在删除队列之前,Leaf Queue中应该没有pending或者running的应用程序。然后修改以下配置:
yarn.scheduler.capacity..state
STOPPED
例如:我们想要删除 hive_test 和 spark_test 两个Leaf Queue。可以配置如下:
yarn.scheduler.capacity.root.hive.hive_test.state
STOPPED
yarn.scheduler.capacity.root.spark.spark_test.state
STOPPED
更新配置。
yarn rmadmin -refreshQueues
Queue Properties
Capacity Scheduler有很多的属性可以配置,默认的配置文件中也可以看到一些。但大体可以分为以下几类:
- 资源分配
- 使用绝对资源分配
- 运行和等待应用程序限制
- Queue管理和权限控制
- 基于user-group、应用程序名称、用户自定义规则(UDR)方式的Queue Mapping
- Queue应用程序Lifetime
资源分配

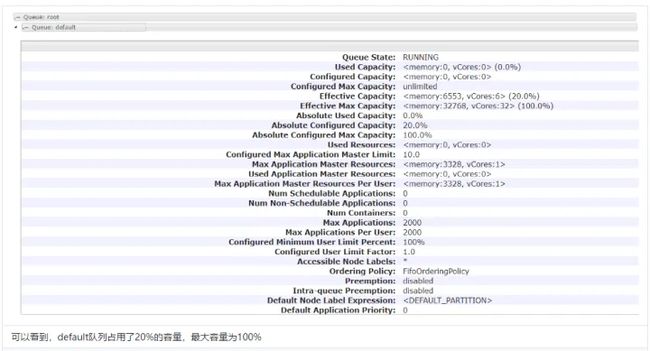
接下来,我们来试验配置下队列容量。
yarn.scheduler.capacity.root.default.capacity
20
yarn.scheduler.capacity.root.default.maximum-capacity
20
yarn.scheduler.capacity.root.hive.capacity
40
yarn.scheduler.capacity.root.spark.capacity
40
yarn.scheduler.capacity.root.hive.hive_dev.capacity
20
yarn.scheduler.capacity.root.hive.hive_prod.capacity
80
yarn.scheduler.capacity.root.spark.spark_dev.capacity
20
yarn.scheduler.capacity.root.spark.spark_dev.maximum-allocation-mb
8192
yarn.scheduler.capacity.root.spark.spark_prod.capacity
80
yarn.scheduler.capacity.root.spark.spark_prod.maximum-allocation-mb
8192
刷新YARN队列。
yarn rmadmin -refreshQueues


绝对资源分配
yarn.scheduler.capacity..capacity
memory = 10240,vcores = 12
yarn.scheduler.capacity..max-capacity
memory = 102400,vcores = 60
运行和等待应用程序限制
以下参数可以控制运行和等待的应用程序。

配置最大AM的资源占比为0.3:
yarn.scheduler.capacity.maximum-am-resource-percent
0.3
yarn.scheduler.capacity.maximum-applications
50000
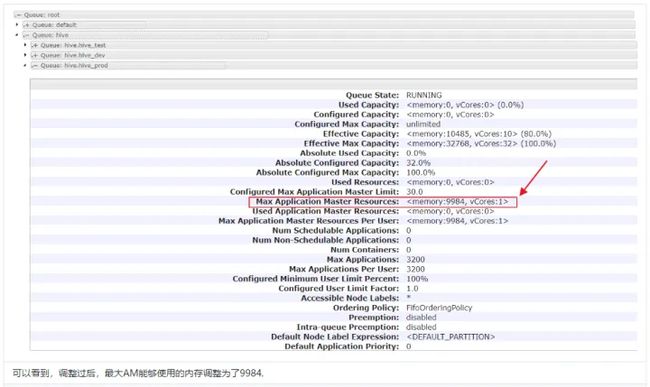

注意
-
最大RUNNING和PENDING的应用数量也会按照队列容量占比划分,例如:
-
- 最大应用数量整体配置为1W
- default容量占比20%,那么default队列最大能够提交2000个应用
- spark和hive队列各占40%,那么最大能够提交4000个应用
- spark_dev和spark_prod各占20%和80%,所以dev队列能够提交800个,prod队列能够提交3200个
Queue管理和权限控制
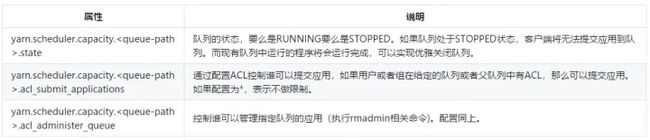
配置ACL可以参考以下:
[user={name} group={name} max_priority={priority} default_priority={priority}]
如果配置为*,表示所有人都具备权限,配置为空格,表示所有人都无权限。
要配置YARN的资源管理,首先需要开启YARN的ACL,默认该配置是禁用的。
yarn.acl.enable
true
yarn.scheduler.capacity.root.acl_submit_applications
yarn.scheduler.capacity.root.acl_administer_queue
yarn.scheduler.capacity.root.hive.acl_submit_applications
*
yarn.scheduler.capacity.root.hive.acl_administer_queue
user=yarn,user=hive
yarn.scheduler.capacity.root.spark.acl_submit_applications
*
yarn.scheduler.capacity.root.spark.acl_administer_queue
user=yarn,user=spark
上述配置,配置了:
1. 所有人都提交提交hive、spark作业
2. hive queue由yarn、hive用户管理
3. spark queue由yarn、spark用户管理
注意
- 配置ACL时,如果value中配置为空格,表示任何人都不能往队列中提交应用
- ACL是具备有继承性的
测试提交作业到指定queue
在提交作业时,可以指定Queue的名字。
-Dmapred.job.queue.name=hive_dev
执行下测试:
cd /opt/hadoop-3.2.1/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=hive_dev 3 1

尝试用spark用户去kill hdfs用户提交的mr作业,将会报错如下:
yarn app -kill application_1613715844272_0005
Caused by: java.security.AccessControlException: User spark cannot perform operation MODIFY_APP on application_1613715844272_0005
Queue Mapping
前面,我们在执行YARN提交作业时,通过-Dmapred.job.queue.name=hive_dev指定将作业提交到指定队列。但每次提交都手动指定很麻烦,而通过Queue Mapping可以实现根据用户、组、应用程序名称自动映射到Queue上,用户还可以自己来定义映射规则。

配置以下映射:
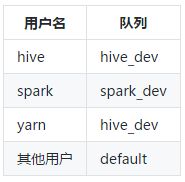
配置以下参数:
yarn.scheduler.capacity.queue-mappings
u:hive:hive_dev,u:spark:spark_dev,u:yarn:hive_dev,u:%user:default
重新提交作业:
cd /opt/hadoop-3.2.1/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi 3 1

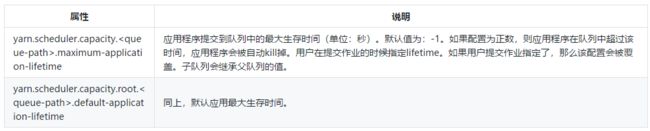
Queue应用程序Life time
应用程序优先级
当前YARN的应用程序优先级仅支持FIFO。提交的应用程序默认为cluster级别和queue级别。
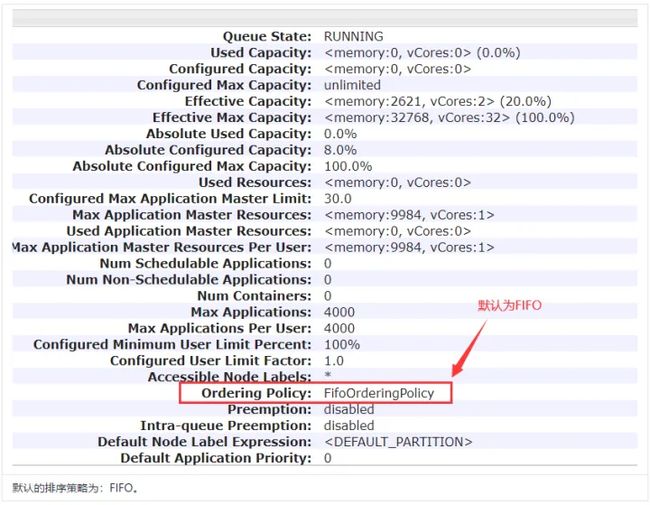
Cluster优先级
一个应用如果提交的优先级如果高于Cluster的最大优先级会被自动设置为最大优先级。通过yarn-site.xml可以指定集群应用的最大优先级。
yarn.cluster.max-application-priority
0
Queue优先级
管理员可以给Leaf Queue指定默认优先级。这样,提交到该队列的应用都会被指定一个优先级。可以通过capacity-scheduler.xml来配置优先级:
yarn.scheduler.capacity.root..default-application-priority
-10
检查FifoOrderingPolicy实现
FifoOrderingPolicy实现代码:
public FifoOrderingPolicy() {
List> comparators =
new ArrayList>();
// 优先级比较器
comparators.add(new PriorityComparator());
// 按进入到Queue的向后顺序比较
comparators.add(new FifoComparator());
this.comparator = new CompoundComparator(comparators);
this.schedulableEntities = new ConcurrentSkipListSet(comparator);
}
优先级比较器实现:
@Override
public int compare(SchedulableEntity se1, SchedulableEntity se2) {
Priority p1 = se1.getPriority();
Priority p2 = se2.getPriority();
if (p1 == null && p2 == null) {
return 0;
} else if (p1 == null) {
return -1;
} else if (p2 == null) {
return 1;
}
return p1.compareTo(p2);
}
}
Fifo比较器实现:
@Override
public int compareInputOrderTo(SchedulableEntity other) {
if (other instanceof SchedulerApplicationAttempt) {
return getApplicationId().compareTo(
((SchedulerApplicationAttempt)other).getApplicationId());
}
return 1;//let other types go before this, if any
}
可以看到,Fifo是直接按照Application ID进行比较。
也就是说,当分配资源时,先分配优先级高的,如果优先级一样,看谁先进入到Queue中。
Capacity Scheduler容器抢占
CapacityScheduler支持从Queue中抢占容器,开启抢占后,优先级高的应用程序会抢占优先级低的应用程序。Capacity Scheduler会杀掉其他队列优先级低的container以释放资源。以下是可以在yarn-site.xml中配置的,关于抢占容器的配置:

以下为针对容量调度器的监视器策略配置:
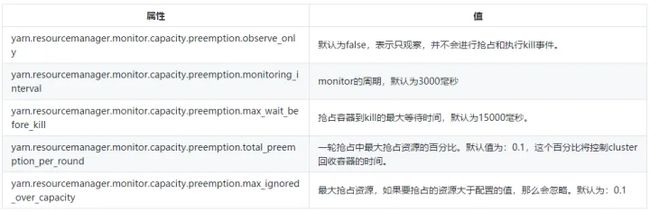
以下为控制提交到Queue中的应用抢占容器,配置添加在capacity-scheduler.xml:

需求及实现
需求
考虑当前使用YARN集群资源有三个部门,分别是A、B、C。
- A部门是经常跑ETL的部门,我们最多提交的是T+1的跑批任务,而且需要消耗大量资源。但白天的时候,这部门资源使用是比较少的。
- B部门是经常跑AdHoc的部门1,它们集中在白天使用,会有大量用户往YARN集群中提交大量作业,包含了大作业、以及小作业。白天的时候需要保证B部门的资源使用。
- C部门与B部门类似,是AdHoc的部门2。
需求分析
- 因为不同部门会有不同的资源需求,我们需要为不同的部门建立不同的队列。
- A部门跑批的数据是AdHoc的基础,所以在凌晨执行ETL任务时,必须要保证其资源的使用。所以该队列的优先级是高的。A部门的作业数量比较多,且大作业数量也比较多。所以,我们希望当A部门在夜间跑批时,能够抢占到集群的所有资源使用。
- B、C部门在白天提交AdHoc作业,所以,我们希望B、C部门能够抢占到更多的A部门的资源。
规划
- A部门最大的资源使用为100%,也就是A部门对应的Queue最大能够使用整个集群的资源。而且A部门对应资源的优先级比较高,可以配置为20,支持抢占。
- B、C部门最大的资源使用为80%,它们的优先级都是一样的,但要比A部门资源要低,可以设置为10。支持抢占。
- 其他部门提交的作业统统放在default queue中,不支持抢占,优先级也是最低的,配置为1。
配置
yarn.scheduler.capacity.maximum-applications
20000
yarn.scheduler.capacity.maximum-am-resource-percent
0.5
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
yarn.scheduler.capacity.root.queues
default,a,b,c
yarn.scheduler.capacity.root.default.state
RUNNING
yarn.scheduler.capacity.root.a.state
RUNNING
yarn.scheduler.capacity.root.b.state
RUNNING
yarn.scheduler.capacity.root.c.state
RUNNING
yarn.scheduler.capacity.root.default.capacity
10
yarn.scheduler.capacity.root.a.capacity
50
yarn.scheduler.capacity.root.b.capacity
20
yarn.scheduler.capacity.root.c.capacity
20
yarn.scheduler.capacity.root.default.maximum-capacity
20
yarn.scheduler.capacity.root.a.maximum-capacity
100
yarn.scheduler.capacity.root.b.maximum-capacity
80
yarn.scheduler.capacity.root.c.maximum-capacity
80
yarn.scheduler.capacity.root.a.user-limit-factor
5
yarn.scheduler.capacity.root.b.user-limit-factor
5
yarn.scheduler.capacity.root.c.user-limit-factor
5
yarn.scheduler.capacity.root.default.default-application-priority
1
yarn.scheduler.capacity.root.a.default-application-priority
20
yarn.scheduler.capacity.root.b.default-application-priority
10
yarn.scheduler.capacity.root.c.default-application-priority
10
yarn.resourcemanager.scheduler.monitor.enable
true
yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round
0.3
yarn.nodemanager.resource.cpu-vcores
16
yarn.nodemanager.resource.memory-mb
16384
部署
# 分发配置
scp /opt/hadoop/etc/hadoop/capacity-scheduler.xml ha-node2:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/capacity-scheduler.xml ha-node3:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/yarn-site.xml ha-node2:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/yarn-site.xml ha-node3:/opt/hadoop/etc/hadoop/
# 刷新队列
yarn rmadmin -refreshQueues
# 重启yarn集群
stop-yarn.sh
start-yarn.sh
测试使用over capacity
# 运行作业测试
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 5 1
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 5 1
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 5 1
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 5 1
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 5 1
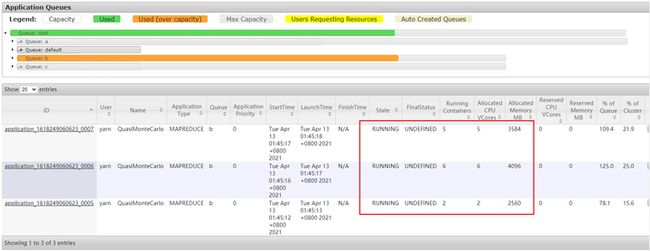
测试抢占
# 先往b队列中提作业,把集群资源打满
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
# 再往a队列中提交1个作业,检查抢占情况
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=a 50 20

FAIR Scheduler
简介
FAIR Scheduler可以让所有运行在YARN上的应用程序,在一段时间内获取到相同等份的资源。默认下,Fair scheduler只基于内存来进行调度。我们可以配置Fair scheduler同时调度v-core和memory。当如果YARN集群只有一个应用在运行时,这个应用将可以使用整个YARN集群的资源。当其他应用程序提交时,释放出来的资源会分配给新的应用程序,最终每个应用程序最终能够获得大致相同的资源。
Fair Scheduler与默认的Hadoop调度策略不一样,它允许短作业可以在合理的时间内完成,这样就不至于因为长作业而导致短作业无法被执行。例如:一个Spark应用配置了动态资源分配,因为要跑一个比较大的JOB,所以一次申请了100个exectuor,直接把YARN集群的资源占满了。此时,我们再提交新的JOB时,就会发现JOB会处于pending状态。而当这个Spark应用的JOB执行完一部分后,会释放出来已经运行完成的executor。那么此时,又可以将新的JOB提交到YARN集群了。Fair Scheduler可以和优先级一起使用,通过优先级可以指定应用程序总共能够获取到的资源权重。
Fair Scheduler也是将应用组织到队列中,并可以在队列之间公平地共享资源。默认情况下,所有的应用都会提交到“default”队列中。而如果在请求container时指定了queue,那么就会将请求指定queue的资源。和CapactityScheduler类似,也可以根据用户名来进行映射。在每个队列中,可以指定调度策略来让应用程序共享资源。默认配置为:基于内存的公平调度。当然,也可以配置FIFO、和多资源、抢占资源调度。类似于Capacity Scheduler,Fair Scheduler也可以配置为层次结构的队列,并且配置权重。
Fair Scheduler可以给队列设置最小保留资源,这样可以确保某些用户、组始终能够获取到资源。但队列不需要保留资源,则共享队列的所有资源。Fair Scheduler默认允许所有程序运行,我们也可以控制每个用户、每个队列能够同时运行的应用数量。限制应用程序的数量不会导致后续提交的应用程序失败,而是让它们处于等待状态,直到队列中的某些应用完成为止。
可插拔的分层队列
和Capacity Scheduler一样,Fair scheduler也支持分层队列,也都是从 root 开始的。只不过,Fair Scheduler是以公平调度的方式来进行资源分配的。
队列调度策略
用户可以通过扩展org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy来构建自定义策略。FifoPolicy、FairSharePolicy(默认)和DominantResourceFairnessPolicy是内置的调度策略。
自动分发作业到队列
和Capacity Scheduler一样,Fair Scheduler也可以让管理员配置映射策略,自动将符合某个规则的应用提交到对应的队列中。
配置使用Fair Scheduler
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
默认的Scheduler为Capacity Scheduler,如下:
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
配置选项
一般Fair Scheduler涉及到两个配置文件的修改。
- 配置yarn-site.xml——对整个FairScheduler配置
- 为Fair Scheduler创建独立的配置文件,配置队列、以及各自的权重和容量。这个配置文件每10秒重新加载一起,随时可更改。
yarn-site.xml
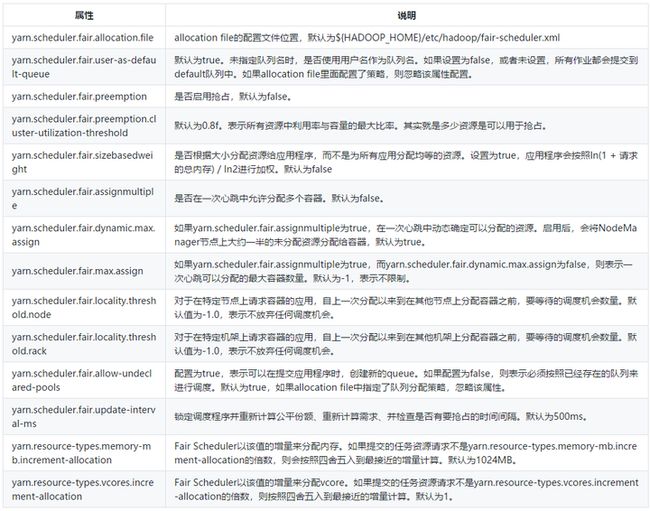
allocation file
Allocation file以XML格式组织。包含了多种不同类型的XML节点组成。
Queue节点
Queue节点为为Fair Scheduler配置队列的地方。可以为Queue节点配置不同的属性,我们可以为一个queue设置一个type属性,当type属性配置为parent时,表示当前配置的是一个父级队列。
上面的配置文件,就表示配置了一个Queue,它的类型为parent,是一个父级队列。
我们还可以为队列配置其他属性。包括:
- minResources:配置队列被分配的最小资源。如果当前不满足队列的最小资源配置,则会在父队列下的其他队列中为它提供可用资源。
- maxResources:配置队列被分配的最大资源。如果队列的资源超过该阈值,则不会再分配容器给该队列。
- maxContainerAllocation:队列能够为单个容器分配的最大资源。如果该属性未设置,将会从父队列继承。默认值为:yarn.scheduler.maximum-allocation-mb和yarn.scheduler.maximum-allocation-vcores。它不能高于maxResources。
- maxChildResources:子队列的最大资源。如果子队列超过该阈值,则不会分配资源。
- maxRunningApps:队列中同时能够执行的应用程序数量
- maxAMShare:队列中能够用于AM Container的资源占比。默认为:0.5f。如果设置为1.0f,则表示最多可以占用100%的内存和CPU。-1.0f表示禁用该功能,不做检查。
- weight:分配不同队列的权重。默认为权重为1,如果配置权重为2,则表示队列所接收的资源大约是权重为默认队列的2倍。
- schedulingPolicy:调度策略。可以配置为fifo、fair、或者drf。或者自己实现org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy。默认为fair,如果设置为fifo,那么优先为较早提交的应用分配容器,如果分配完后仍然有空间,则继续进行下一轮分配。
- aclSubmitApps:配置哪些用户、或者哪些用户组能够提交应用到队列。
- aclAdministerApps:配置哪些用户、哪些组可以管理应用。目前,就是kill应用的权限。
- minSharePreemptionTimeout:队列可用资源低于minResources,Fair Scheduler将会从其他队列中抢占容器的超时等待时间。超过该时间,则开始抢占。如果未设置,则从父队列继承。默认为:Long.MAX_VALUE,表示不从其他队列抢占容器。
- fairSharePreemptionTimeout:队列可用资源低于Fair share阈值,Fair Scheduler将会从其他队列中抢占容器的超时等待时间。超过该时间,则开始抢占,如果未设置,从父队列继承。默认为:Long.MAX_VALUE,表示不从其他队列抢占容器。
- fairSharePreemptionThreshold:队列的Fair share阈值,如果Fair Scheduler等待一段时间后,确实没有等到fairSharePreemptionThreshold * fair share,那么可以从其他队列中抢占容器获取资源。如果未设置,从父队列继承。默认为:0.5f。
- allowPreemptionFrom:是否允许Fair scheduler从队列中抢占资源。默认为true。如果设置为false,则所有子队列的资源都是不允许被抢占的。
- reservation:向资源保留系统配置为用户预留资源,如果未配置,表示不为预留资源。
示例:
10000 mb,0vcores
90000 mb,0vcores
50
0.1
2.0
fair
charlie
5000 mb,0vcores
User节点
user节点可以控制独立一个用户的资源。User节点可以包含相关属性。例如:maxRunningApps,这个用户最多能够提交的应用。
userMaxAppsDefault
用户最多默认能够提交的应用数量。
defaultFairSharePreemptionTimeout
为该用户设置root队列 Fair share 的抢占超时等待时间。默认为:Long.MAX_VALUE。
defaultMinSharePreemptionTimeout
为该用户设置root队列 Min Share的抢占超时等待时间。默认为:Long.MAX_VALUE。
defaultFairSharePreemptionThreshold
为该用户设置root队列 Fair Share的抢占阈值。一旦没有拿到 Fair Share * 阈值,则开始抢占。
queueMaxAppsDefault
为该用户设置最大能够提交到Queue的数量。
queueMaxAMShareDefault
设置Queue默认的最大AM能够占用的百分比
defaultQueueSchedulingPolicy
设置Queue的默认调度策略。
reservation-agent
设置ReservationAgent的实现,这个实现类是要将用户的预留请求放到计划中。默认值为:org.apache.hadoop.yarn.server.resourcemanager.reservation.planning.AlignedPlannerWithGreedy。
reservation-policy
设置SharingPolicy(共享策略),这个实现是用来验证资源保留是否会和其他配置冲突。默认值为:org.apache.hadoop.yarn.server.resourcemanager.reservation.CapacityOverTimePolicy。
reservation-planner
设置Planner的实现类,如果发现Plan的容量如果小于用户保留资源,则会调用它。默认为:org.apache.hadoop.yarn.server.resourcemanager.reservation.planning.SimpleCapacityReplanner,它会扫描plan,并按照LIFO删除保留资源,直到保留的资源在计划容量内。
queuePlacementPolicy
包含一系列的规则节点列表,这些规则可以决定应该如何将应用请求放在哪个队列中,规则是以在配置中出现的顺序应用。每一个规则都有一个create参数,默认为true。如果设置为false,表示应用程序会被放入到allocation file中未配置的队列中。以下是关于rule(规则)的说明:
- specified:应用程序会放入到指定的队列中。如果应用程序没有指定队列,则会放入到“default”队列中。如果队列名称是以「.q1」或者「q1.」开头或者结尾,会被拒绝。
- user:将对应用户名的应用提交到队列中,如果用户名中包含了「.」,会被替换为「dot」,例如:用户first.last会被替换为first_dot_last。
- primaryGroup:以某个primary group的用户会放入到该队列中。和用户名一样,如果组名中包含了点号,也会被替换为_dot_。
- secondaryGroupExistingQueue:以某个secondary group的用户会放入到该队列中。和用户名一样,如果组名中包含了点号,也会被替换为_dot_。
- nestedUserQueue:与user策略类似,但user规则只能在根队列下创建用户队列,而nestedUserQueue可以在任何父队列下创建用户队列。注意,nestedUserQueue只能配置为type为parent的队列。
- default:设置用户提交应用的默认队列。如果没有指定queue,会放置在root.default队列中。
- reject:该应用会被拒绝
示例:
0.5
40000 mb,0vcores
30
5
参考配置文件:
10000 mb,0vcores
90000 mb,0vcores
50
0.1
2.0
fair
charlie
5000 mb,0vcores
0.5
40000 mb,0vcores
3.0
4096 mb,4vcores
30
5
需求及实现
需求
考虑当前使用YARN集群资源有三个部门,分别是A、B、C。
- A部门是经常跑ETL的部门,我们最多提交的是T+1的跑批任务,而且需要消耗大量资源。但白天的时候,这部门资源使用是比较少的。
- B部门是经常跑AdHoc的部门1,它们集中在白天使用,会有大量用户往YARN集群中提交大量作业,包含了大作业、以及小作业。白天的时候需要保证B部门的资源使用。
- C部门与B部门类似,是AdHoc的部门2。
需求分析
- 因为不同部门会有不同的资源需求,我们需要为不同的部门建立不同的队列。
- A部门跑批的数据是AdHoc的基础,所以在凌晨执行ETL任务时,必须要保证其资源的使用。所以该队列的优先级是高的。A部门的作业数量比较多,且大作业数量也比较多。所以,我们希望当A部门在夜间跑批时,能够抢占到集群的所有资源使用。
- B、C部门在白天提交AdHoc作业,所以,我们希望B、C部门能够抢占到更多的A部门的资源。
规划
- 配置三个Fair队列,分别是a、b、c、default,a设置的weight为6,b和c的weight为3、default的weight为1。
- 为了方便在队列中大家共享资源,所以需要使用fair调度。
- 需要开启抢占资源。
配置
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.scheduler.fair.preemption
true
yarn.resource-types.memory-mb.increment-allocation
256
注意:配置Fair scheduler需要删除掉Capcity相关配置(例如:Capacity Scheduler的抢占配置)
10%
20%
1.0
50%
100%
6.0
20%
80%
20000
3.0
20%
80%
3.0
10000
20000
0.5f
fair
部署
# 分发配置
scp /opt/hadoop/etc/hadoop/fair-scheduler.xml ha-node2:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/fair-scheduler.xml ha-node3:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/yarn-site.xml ha-node2:/opt/hadoop/etc/hadoop/ ;\
scp /opt/hadoop/etc/hadoop/yarn-site.xml ha-node3:/opt/hadoop/etc/hadoop/
# 重启yarn集群
stop-yarn.sh
start-yarn.sh
# 刷新队列
yarn rmadmin -refreshQueues
测试Fair Share
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 30 20
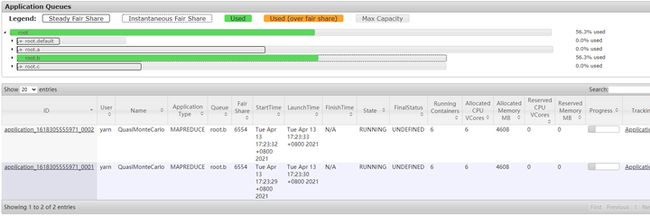

可以看到,两个应用占用的资源是差不太多的,这就实现了Fair Share。
测试不同weight权重的Fair Share
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=a 50 30
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 50 20

可以看到,root.a这个queue能够拿到的资源大约是root.b queue的两倍左右。
测试资源抢占
# 提交4个JOB,把root.b queue的资源打满
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=b 50 20
# 提交1个JOB到root.a,检查抢占情况
cd /opt/hadoop/share/hadoop/mapreduce; \
yarn jar hadoop-mapreduce-examples-3.2.1.jar pi -Dmapred.job.queue.name=a 50 20

我们可以看到随着时间推移,root.a开始抢占root.b的资源。
对比两种资源调度策略
Fair Scheduler的核心是尽可能地共享整个集群的资源,让多个用户可以共享使用整个集群。Capacity Scheduler旨在共享大型集群资源,并且为每个组织/部门提供最小的容量保证,它的核心是让YARN集群中的可用资源在多个组织/部门之间共享,Capacity Scheduler也可以共享空闲的容量。
其实它们两现在很多功能上都是有重叠的,例如,都支持Queue、都支持抢占、弹性资源扩展。而Capacity Scheduler比较适合超大规模的、多组织机构、严格的资源管理。而Fair Scheduler比较适合中小规模、组织机构不是特别复杂,而且对资源共享有较高需求的集群。
原文:
- https://zhuanlan.zhihu.com/p/335881182