GO 多线程工具使用和分析
GO 多线程工具使用和分析
Go 语言中的 sync 包提供了一些用于同步和互斥访问共享资源的原语,使用这些可以避免多个goroutine同时访问共享资源时出现的问题,他们有:
- 互斥锁
- 读写锁
- cond
- WaitGroup
- map
- once
- pool
- atomic
本文介绍它们的使用方式
互斥锁(Mutex)
互斥锁是最基本的同步原语,用于保护共享资源的访问。
在 Go 语言中,可以使用 sync.Mutex 类型来创建一个互斥锁,并使用 Lock 和 Unlock 方法分别来进行加锁和解锁操作。并且它不是可重入锁。
func main() {
var (
count int
mutex sync.Mutex
)
for i := 0; i < 1000; i++ {
go func() {
mutex.Lock()
defer mutex.Unlock()
count++
}()
}
time.Sleep(time.Second*3)
fmt.Println(count)
}
不可重入
func main() {
var lock sync.Mutex
lock.Lock()
lock.Lock()
lock.Unlock()
lock.Unlock()
}
// output:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [semacquire]:
sync.runtime_SemacquireMutex(0xc00008a000?, 0x0?, 0xc000086000?)
D:/goSdk/go1.19/src/runtime/sema.go:77 +0x25
sync.(*Mutex).lockSlow(0xc00008a000)
D:/goSdk/go1.19/src/sync/mutex.go:193 +0x165
sync.(*Mutex).Lock(...)
D:/goSdk/go1.19/src/sync/mutex.go:109
main.main()
D:/GolandProjects/base_go/synchander/sync.go:8 +0x6c
Process finished with the exit code 2
Mutex两种模式
normal(正常)
一个尝试加锁的goroutine会先自旋几次,尝试通过原子操作获得锁,若几次自旋之后仍不能获得锁,则通过信号量排队等待。(等待队列)
所有等待者会按照先入先出FIFO的顺序排队(信号量的底层是通过park来操作的)。
当锁被释放,第一个等待者被唤醒后并不会直接拥有锁,而是需要和后来者竞争,也就是那些处于自旋阶段,尚未排队等待的goroutine。
这种情况下后来者更有优势,有两个原因:
- 它们(处在自旋阶段,尚未排队的goroutine)正在CPU上运行,自然比刚被唤醒的goroutine更有优势。
- 处于自旋状态的goroutine可以有很多,而被唤醒的goroutine每次只有一个。
所以被唤醒的goroutine有很大概率拿不到锁。这种情况下它会被重新插入到队列的头部,而不是尾部。
starvation(饥饿)
当锁被释放之后,队列头部的goroutine可获取锁,没有goroutine和它竞争。尝试获取锁的每一个goroutine都会被添加到队列的 尾部。当他们获取锁的时候,mutex处于未加锁的状态。
两种模式的的切换
normal -> starvation
当一个goroutine本次加锁等待时间超过了1ms后,它会把当前Mutex从正常模式切换至“饥饿模式”。
starvation -> normal
当一个等待队列中等待者获取到锁之后,在下面两种情况下,会切换会正常模式
- 它等待锁的时间小于1ms(意思是当前goroutine等待的时间不长,也侧面反应当前的抢占锁的情况不强烈)
- 等待队列中没有等待的goroutine了。(等待队列已经空了)
数据结构
type Mutex struct {
state int32 // 状态
sema uint32 //等待信号量
}
// 有下面的几种状态
mutexLocked = 1 << iota // mutex is locked
mutexWoken // 唤醒
mutexStarving //饥饿
源码分析
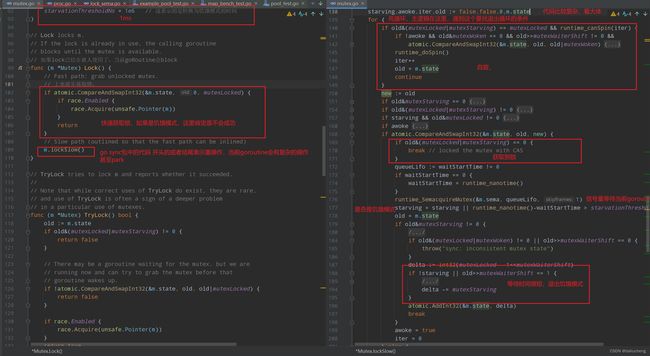
加锁
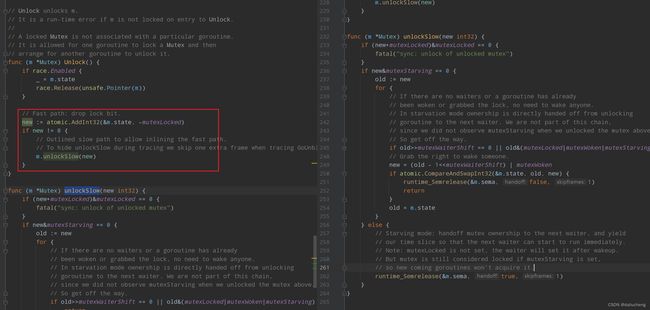
释放锁
总结
- Mutex不是一个可重入锁
- 有两种模式,并且两种模式在Mutex运行期间是可以互相切换的。
读写锁(RWMutex)
分为读锁,写锁,并且两者互斥。
它允许多个 goroutine 同时读取共享资源,但只允许一个 goroutine 写入共享资源。
读取和写入被分别表示为 RLock 和 Lock 方法。RLock 方法允许多个 goroutine 同时获取读锁,而 Lock 方法则只允许一个 goroutine 获取写锁。当一个 goroutine 获取写锁时,即使已经有其他 goroutine 获取了读锁,也会被阻塞。
关于泛型看:https://blog.csdn.net/nihaihaoma/article/details/125601630
// 下面是利用RWMutex写的goroutine并发安全的map
// 重点在于读取或写入的时候调用的方法不同
package main
import "sync"
type SafeMap[K comparable,T any] struct {
sync.RWMutex
m map[K]T
}
func newSafeMap[K comparable,T any](size int) *SafeMap[K,T] {
return &SafeMap[K,T]{
m: make(map[K]T,size),
}
}
func (sm *SafeMap[K,T]) Get(key K) (T, bool) {
sm.RLock()
defer sm.RUnlock()
value, ok := sm.m[key]
return value, ok
}
func (sm *SafeMap[K,T]) Set(key K, value T) {
sm.Lock()
defer sm.Unlock()
sm.m[key] = value
}
func (sm *SafeMap[K,T]) Delete(key K) {
sm.Lock()
defer sm.Unlock()
delete(sm.m, key)
}
func (sm *SafeMap[K,T]) Len() int {
sm.RLock()
defer sm.RUnlock()
return len(sm.m)
}
func main() {
m := newSafeMap[string,string](10)
m.Set("a","a")
v, _ := m.Get("a")
println(v)
}
数据结构
type RWMutex struct {
w Mutex // held if there are pending writers 写操作加锁,互斥锁
writerSem uint32 // 写锁goroutine等待队列
readerSem uint32 // 读锁goroutine等待队列
readerCount int32 // 当前持有读锁的goroutine的数量
readerWait int32 // 已经释放读锁的goroutine
}
在 RWMutex 中,读和写操作使用了不同的信号量和计数器,以保证读操作和写操作之间的互斥性。
在读操作中,如果没有等待的写操作,那么读取就会立即进行;
如果有等待的写操作,那么读取就会等待,直到写操作完成。
在写操作中,如果没有其他 goroutine 正在读或写,那么写入就会立即进行;
如果有其他 goroutine 正在读或写,那么写入就会等待,直到所有读操作完成。
最大的读操作goroutine的数量
const rwmutexMaxReaders = 1 << 30 // 2 的 30 次方,
读锁
获取
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
//加读锁,增加readerCount,readerCount为负数说明已经被获取到了写锁,
// readerCount为负是在 获取读锁之后,就把readcount -= maxReader
// 有写锁,当前的goroutine在获取读锁的时候应该等待。
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
释放
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
// 释放读锁,需要readerCount--,
//readerCount为负数的时候说明有写锁
// 持有写锁的goroutine readCount -= maxRead
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
if race.Enabled {
race.Enable()
}
}
func (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
fatal("sync: RUnlock of unlocked RWMutex")
}
// readerWait是写锁持有期间等待的goroutine的数量
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
// 为0 说明读操作已经结束了,需要唤醒在写上park的goroutine
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
写锁
获取
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
// lock之后下面的操作可就是一个goroutine了,剩下的操作就是等待所有的reader的goRoutine结束,写操作开始
rw.w.Lock()
// Announce to readers there is a pending writer.
// cas操作将readCOunt变为负数
// r就是当前持有的读锁的goRoutine
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
// 不为0说明当前还有正在持有读锁的goRoutine
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 当前有reader,一直等待所有的持有读锁的goroutine释放掉,才会从这unpark
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
释放
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
// 释放的时候将readerCount复原
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders { // 读的goroutine超过了max 报错
race.Enable()
fatal("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
// 唤醒所有的读的goroutine
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
总结:
- 读操作不加锁,写操作加锁。
- 没有所谓的锁降级的概念,也就是先持有写锁,在获取读锁,最后释放写锁,最后在释放先前持有的写锁的过程(Java中ReadWriteLock中就是这个特性,主要是因为java的内存模型影响的,为了保证数据的可见性)
- 读锁和写锁是完全互斥的,意思是读锁全部释放之后,写锁才可继续操作,反过来也是。
- 写锁的实现是
Mutex,他是不可重入的。读锁无所谓。
cond
这个和Java中的wait notify一样
提供了一种等待和通知的机制,可以用于协调多个 goroutine 的执行顺序。
在使用 cond 进行等待和通知时,通常需要与 mutex 配合使用,以确保并发安全。
当一个 goroutine 需要等待某个条件时,可以调用 cond.Wait() 方法,这个方法会释放当前的锁,并进入等待状态,直到其他 goroutine 通过调用 cond.Signal() 或 cond.Broadcast() 方法来唤醒它。
当条件满足时,可以通过调用 cond.Signal() 或 cond.Broadcast() 方法来通知其他等待的 goroutine 继续执行。
需要注意,在使用的时候必须是同一个lock。Java中是在任意一个对象上面wait的,wait notify也是Java面试很常见的了。
// 这是一个很简单的标志位退出的代码,两个goroutine,当isSuccess为true,退出
func main() {
var lock sync.Mutex
cond := sync.NewCond(&lock)
isSuccess := false
go func() {
lock.Lock()
defer lock.Unlock()
for{
if isSuccess{
println("success1")
return
}
cond.Wait()
}
}()
go func() {
lock.Lock()
defer lock.Unlock()
for{
if isSuccess{
println("success2")
return
}
cond.Wait()
}
}()
time.Sleep(1*time.Second)
lock.Lock()
println("main set value begin")
isSuccess = true
println("main set value end")
cond.Broadcast() // 唤醒所有,Signal只唤醒一个
lock.Unlock()
time.Sleep(time.Hour)
}
重温一下生产者消费者的经典写法
package main
import (
"math/rand"
"sync"
"time"
)
type Collection interface {
offer(data int)
poll() int
}
type SafeQueue struct {
data []int
lock *sync.Mutex // 这里需要注意,必须是指针,如果不是指针的话,这里就和cond里面的mutex不一样了,出现问题了。
pCond *sync.Cond // 生产者等待队列
cCond *sync.Cond // 消费者等待队列
cap int
size int
}
func newSafeQueue(cap int) *SafeQueue {
var m sync.Mutex
return &SafeQueue{
data: make([]int,cap),
lock: &m,
pCond: sync.NewCond(&m),
cCond: sync.NewCond(&m),
cap: cap,
size: 0,
}
}
func (q *SafeQueue) offer(data int) {
q.lock.Lock()
defer q.lock.Unlock()
if q.size ==q.cap{
println(data,"wait")
q.pCond.Wait()
}
q.data[q.size] = data
q.size++
println("offer",data,"size",q.size)
q.cCond.Signal()
}
func (q *SafeQueue) poll() int {
q.lock.Lock()
defer q.lock.Unlock()
if q.size == 0 {
println("poll wait")
q.cCond.Wait()
}
q.size--
res := q.data[q.size]
println("poll ",res,"size",q.size)
q.pCond.Signal()
return res
}
func main() {
queue := newSafeQueue(10)
go func() {
for {
queue.offer(rand.Int())
time.Sleep(time.Second)
}
}()
go func() {
for {
queue.poll()
}
}()
time.Sleep(time.Hour)
}
// 用channel改写一下
// 所以channel很牛皮,就这么一点代码,完成了上面的功能
func main() {
ints := make(chan int, 10)
go func() {
for {
ints<-rand.Int()
time.Sleep(time.Second)
}
}()
for i := range ints {
println(i)
}
}
WaitGroup
相当于Java中CountDownlatch
它可以用于等待一组 goroutine 的结束。WaitGroup 维护了一个计数器,表示还有多少个 goroutine 没有结束,当计数器归零时,表示所有的 goroutine 都已经结束,可以继续执行后面的代码。
WaitGroup 提供了三个方法:
Add(delta int):将计数器加上 delta,表示有 delta 个 goroutine 需要等待。Done():将计数器减去 1,表示一个 goroutine 已经结束。Wait():等待计数器归零,即所有的 goroutine 都已经结束。
需要注意
- WaitGroup可以连续add,和Java中的countdown latch不一样。后者只能是在创建的时候指定,并且只能一次
- WaitGroup可以连续用,在Wait触发之后,计数器归0,重新开始。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(10) // 等待10个goroutine结束
for i := 0; i < 10; i++ {
go func(i int) {
defer wg.Done()
fmt.Println("goroutine ", i, " done")
}(i)
}
wg.Add(1) // 在wait之前还可以继续加,这里表示等待11个goroutine结束
go func(i int) {
defer wg.Done()
fmt.Println("goroutine ", i, " done")
}(11)
wg.Wait()
// wait触发之后,还可以继续用,只不过这个时候从0开始了
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
fmt.Println("goroutine ", i, " done")
}(i)
}
wg.Wait()
fmt.Println("all done")
}
Map
一个并发安全的 Map 类型。该类型被设计为用于在多个 goroutine 之间共享键值对,并且支持并发读取和写入操作。
sync.Map 类型内部使用了读写锁和哈希表实现。
它的主要特点是在写入时不会阻塞读取操作,因为写入操作会将数据存储在一个 “脏(dirty)” Map 中,而读取操作则始终从一个 “干净(read)” Map 中读取数据。当 “脏” Map 中的数据量达到一定阈值时,该 Map 会被转换为 “干净” Map,以便读取操作可以更快地访问数据。
与标准库中的 map 类型不同,sync.Map 不支持使用下标语法来访问数据。相反,它提供了 Load、Store、LoadOrStore、Delete 和 Range 等方法来操作数据。这些方法的使用方式与标准库中的 map 类型类似,但是需要传递一个接口类型的键作为参数,而不是直接使用下标。
sync.Map不需要make,声明就可使用
需要注意的是,sync.Map 中的键和值必须是可比较的类型,否则会在运行时引发 panic。sync.Map的性能肯定是比不上map的,支持在某些情形下使用,因此在选择使用它时需要根据具体情况进行评估。
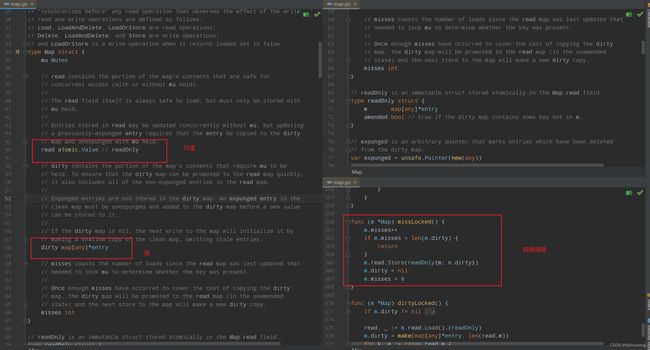
结构
once
可以保证在程序运行期间,某个函数只会被执行一次。Once通常被用来实现单例模式或者延迟初始化。
Once只有一个Do方法,该方法接收一个函数作为参数,当且仅当该函数第一次被调用时才会执行。Once会确保这个函数在程序运行期间只会被执行一次,即使在多个Go协程中同时调用Do方法也是安全的。Once使用了一个互斥锁和一个标志位来实现这个功能。
单例模式
import (
"fmt"
"sync"
)
type Singleton struct {
name string
}
var (
once sync.Once
instance *Singleton
)
func NewSingleton() *Singleton {
once.Do(func() {
instance = &Singleton{name: "MySingleton"}
})
return instance
}
func main() {
s1 := NewSingleton()
s2 := NewSingleton()
fmt.Println(s1 == s2) // true
}
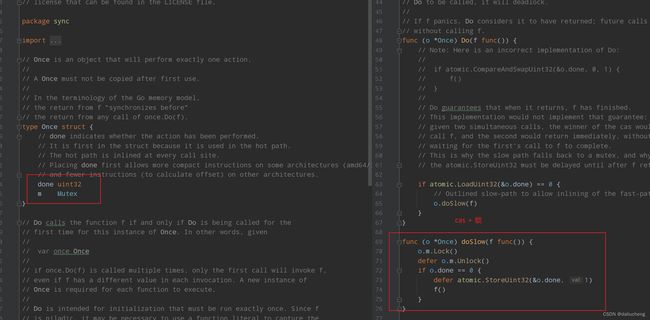
源码分析
pool
用于管理可重用的临时对象。Pool通常被用来避免在高并发场景下频繁地分配和释放内存,从而提高程序的性能。
对于很多需要重复分配、回收内存的地方,sync.Pool 是一个很好的选择。频繁地分配、回收内存会给 GC 带来一定的负担,而 sync.Pool 可以将暂时不用的对象缓存起来,待下次需要的时候直接使用,不用再次经过内存分配,复用对象的内存,减轻 GC 的压力,提升系统的性能。
有两个方法:
-
Get
Get方法用于获取一个可重用的对象,如果Pool中已经有可重用的对象,则返回其中一个。否则,会调用New方法创建一个新的对象并返回
-
Put。
Put方法用于将一个对象放回Pool中,以便下次被重用。需要注意:对象的属性并不会清空。建议在put的时候先清空属性,在放进去。
此外还需要通过New来指定加载方法。
package main
import (
"fmt"
"sync"
)
type MyObject struct {
name string
}
func NewMyObject(name string) *MyObject {
return &MyObject{name: name}
}
func main() {
pool := sync.Pool{
New: func() interface{} {
fmt.Println("Creating new object")
return NewMyObject("MyObject")
},
}
obj1 := pool.Get().(*MyObject) // 第一次加载,池中没有对象,会调用到New,创建一个对象
fmt.Println(obj1.name)
pool.Put(obj1) // 放进去
obj2 := pool.Get().(*MyObject) // 再次加载,不会在创建对象了,但可以看到,对象的属性并没有清空
fmt.Println(obj2.name)
}
这篇博客对pool分析的很到位:https://qcrao.com/post/dive-into-go-sync-pool/
atomic
atomic是原子操作。 原子操作就是不可中断的操作。
在实际使用的时候和循环配合的比较紧密。cas操作嘛
主要分为两大类
- 操作类
- Value(存储值)
操作类
按照不同的类型,主要分为下面的几个操作
- 增减操作(AddXXType):保证对操作数的原子增减;
- 载入操作(LoadXXType):保证读取到操作数前,没有其他routine对其进行更改操作;
- 存储操作(StoreXXType):保证存储时的原子性(避免被其他线程读取到修改一半的数据);
- 比较并交互操作(CompareAndSwapXXType):保证交换的CAS,只有原有值没被更改时才会交换;
- 交换操作(SwapXXType):直接交换,不关心原有值。
这里举个例子
按照顺序打印1,2,3,4,5.多个goroutine实现,用无锁的方法实现
package main
import (
"sync"
"sync/atomic"
)
var (
idx int32
group sync.WaitGroup // 利用waitGroup做同步
)
// expect 想要设置的值
// next 设置的值
// 这里的思想是看idx是否是自己想要的值,如果是设置为下一个值,然后结束循环,否则一直在循环
func s (expect,next int32) {
for{
if atomic.LoadInt32(&idx) == expect{
println(expect)
atomic.StoreInt32(&idx,next) // 将idx设置为新的值
group.Done()
return
}
}
}
func main() {
for i := 0; i < 10; i++ {
group.Add(1)
go s(int32(i), int32(i+1))
}
group.Wait()
}
将上面的例子改为用channel实现
思路:让这一个goroutine等待上一个goroutine结束,用无缓存的channel做同步
// 1. 先写这个,写等待此channel里面的数据。接下来看怎么做channel同步
func s(inputC,outputC chan struct{},i int) {
<-inputC
println(i)
if outputC == nil{
group.Done()
}
outputC<- struct{}{}
group.Done()
}
func main() {
// 这里的思路就是一个goroutine从一个channel中获取数据,在从另一个channel中写数据
cList := make([]chan struct{}, 0, 5)
for i := 0; i < 5; i++ {
cList = append(cList, make(chan struct{}))
}
for idx := range cList {
group.Add(1)
if idx == 4{
go s(cList[idx],nil,idx)
continue
}
go s(cList[idx],cList[idx+1],idx)
}
cList[0]<- struct{}{}
group.Wait()
}
存储
sync/atomic Value表示的是一个原子引用。配合Load,Store来原子的操作它。在go的Context包中使用了它。如下
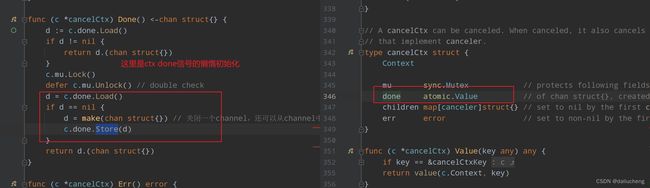
关于atomic可看:https://blog.csdn.net/alwaysrun/article/details/125023283
到这里,文章结束了。