leetcode-hot100-哈希表
文章目录
- [49. 字母异位词分组 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/group-anagrams/)
- [169. 多数元素 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/majority-element/)
- [208. 实现 Trie (前缀树) - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/implement-trie-prefix-tree/)
- [1. 两数之和 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/two-sum/)
- [438. 找到字符串中所有字母异位词 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/)
- [347. 前 K 个高频元素 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/top-k-frequent-elements/)
- [76. 最小覆盖子串 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/minimum-window-substring/)
- [3. 无重复字符的最长子串 - 力扣(LeetCode) (leetcode-cn.com)](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/)
49. 字母异位词分组 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 创建一个
HashMap,key为每次遍历之后的排序,这样只要是由相同的字母组成的字符串,最后都会聚集在这个map对应的value中,value存放每次遍历得到的字符串。 - 最后返回的时候,只需要返回
map中的values即可,因为只需要对应的结果。
- 创建一个
-
代码
public List<List<String>> groupAnagrams(String[] strs) { Map<String, List<String>> map = new HashMap<>(); for(String str : strs){ char[] array = str.toCharArray(); //只要是由相同字母组成的字符串,key都是一样的 Arrays.sort(array); String key = new String(array); //如果map中有,那么说明之前就有添加的,没有就说明是一个新的str,new一个就好 List<String> list = map.getOrDefault(key, new ArrayList<>()); //每次向得到的list添加当前遍历到的str list.add(str); //放入map中 map.put(key,list); } return new ArrayList<>(map.values()); }
169. 多数元素 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 使用
map,key,value分别是当前扫描到的值,以及在map中的对应的value值 - 记住方法
getOrdefault(key,num)。表示如果map中有key那就取,如果没有,那么就使用num - 判断,只要当前数对应的
value长度大于[n/2],那么就返回。
- 使用
-
代码
class Solution { public int majorityElement(int[] nums) { int n = nums.length; int halfN = n / 2; Map<Integer, Integer> res = new HashMap<>(); for(int num : nums){ res.put(num, res.getOrDefault(num, 0) + 1); if(res.get(num) > halfN){ return num; } } return 0; } }
208. 实现 Trie (前缀树) - 力扣(LeetCode) (leetcode-cn.com)
-
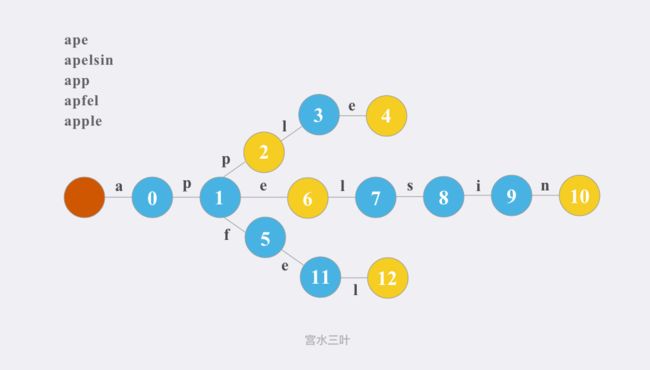
-
核心思想:使用边来代表有无字符,使用点来记录是否为单词结尾以及其后续字符串的字符是什么。
-
思路:
- 创建一个
TrieNode节点,随着数据的不断插入,根据需要不断的创建TrieNode节点。- 该节点作用是什么呢?这个结点天生有一个大小为26的数组,数组的类型也是自己本身
TrieNode,这样的话可以从任意一个位置再继续衍生。还有一个判断是否是结尾的标志end。
- 该节点作用是什么呢?这个结点天生有一个大小为26的数组,数组的类型也是自己本身
- 首先需要一个根节点。
- 初始化前缀树的时候,根节点进行初始化。
insert操作:使用工作指针p,对给定的字符串进行扫描,每次扫描到的字符先减去a,这样可以知道当前扫描的字符相对于a有多远,因为内部有一个大小为26的数组。只要扫描到的字符对应的数组为空,那么就将这个位置再初始化一个TrieNode,这样就可以方便之后的展开,然后指针移动到扫描的位置。最后对给定的字符串扫描完毕之后,那么就再最后一个位置标记end为true。search操作:同样使用工作指针p。同样也是扫描给定字符串,一旦工作指针内部的数组在某个位置为空,那么就返回false,这个意思就是说,之前放入的节点,没有这个字符,直接就可以判定。否则指针就下移。最后只需要返回工作指针的end的状态。startWith操作:一样使用工作指针。同样扫描给定字符串,找到工作指针内部的数组,看起状态是否为空,如果为空,同样也是说明之前的字符串就没有这个字符,直接可以判定。否则指针下移。如果都扫描完了,那么说明之前的字符串的可以截取成现在给定的字符串。
- 创建一个
-
代码
class Trie { class TrieNode{ boolean end; TrieNode[] tns = new TrieNode[26]; } TrieNode root; /** Initialize your data structure here. */ public Trie() { root = new TrieNode(); } /** Inserts a word into the trie. */ public void insert(String word) { TrieNode p = root; for(int i = 0; i < word.length(); i++){ int u = word.charAt(i) - 'a'; if(p.tns[u] == null){ p.tns[u] = new TrieNode(); } p = p.tns[u]; } p.end = true; } /** Returns if the word is in the trie. */ public boolean search(String word) { TrieNode p = root; for(int i = 0; i < word.length(); i++){ int u = word.charAt(i) - 'a'; if(p.tns[u] == null){ return false; } p = p.tns[u]; } return p.end; } /** Returns if there is any word in the trie that starts with the given prefix. */ public boolean startsWith(String prefix) { TrieNode p = root; for(int i = 0; i < prefix.length(); i++){ int u = prefix.charAt(i) - 'a'; if(p.tns[u] == null){ return false; } p = p.tns[u]; } return true; } } /** * Your Trie object will be instantiated and called as such: * Trie obj = new Trie(); * obj.insert(word); * boolean param_2 = obj.search(word); * boolean param_3 = obj.startsWith(prefix); */
1. 两数之和 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 使用HashMap。key是当前数,value是下标。
- 如果map中包含
target-num说明就找到了两个数之和为target的,那么直接返回即可。否则就添加进map。 - 如果循环完毕都没有找到,那么就直接返回int[0]
-
代码
class Solution { public int[] twoSum(int[] nums, int target) { Map<Integer, Integer> map = new HashMap<>(); int len = nums.length; for(int i = 0; i < len; i++){ if(map.containsKey(target - nums[i])){ return new int[]{map.get(target - nums[i]), i}; } map.put(nums[i], i); } return new int[0]; } }
438. 找到字符串中所有字母异位词 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 用长度为26的数字来记录字母出现的次数
- 设n为s的长度,m为p的长度。
- 本题的前提就是s的长度大于p的长度,所以一旦p的长度超过s的长度,那么不可能有
- 然后记录p和s字符串的频次数,这个长度只能限定为p的长度。统计在这个长度下出现的频次数。
- 如果相等,那么说明从开始的时候就有相等的情况。添加0.
- 然后继续遍历s字符串索引为[m,n)的字母,在sCount中每次新增加一个新的字母就要去掉原来的旧的字母,这样做的目的是保持sCount和pCount的频次相等。
- 判断pCount和sCount是否相等,相等话就在返回值res新增加i - m + 1.
-
解释一下:
限定两个字符串频次数组的长度,一定是p字符串的长度。频次长度为26,因为26个字母,第一次扫描到m位置,如果频次相等,那么就是说明s字符串从一开头就异词相等。然后再扫描[m,n)这之间对应s字符串的字母,保持长度相等,每次新增加一个,就要删除之前旧的,如果频次数组相等,那么就添加i-m+1
-
代码
class Solution { public List<Integer> findAnagrams(String s, String p) { int n = s.length(), m = p.length(); List<Integer> res = new ArrayList<>(); if(n < m){ return res; } int[] sCount = new int[26]; int[] pCount = new int[26]; for(int i = 0; i < m; i++){ pCount[p.charAt(i) - 'a']++; sCount[s.charAt(i) - 'a']++; } if(Arrays.equals(sCount,pCount)){ res.add(0); } for(int i = m; i < n; i++){ sCount[s.charAt(i - m) - 'a']--; sCount[s.charAt(i) - 'a']++; if(Arrays.equals(sCount,pCount)){ res.add(i - m + 1); } } return res; } }
347. 前 K 个高频元素 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 初始化一个数组大小为k的结果集。
- 遍历数组,将每个数放放入map中,key为数值,value是每个数值出现的次数。
- 设置一个最大的数。用来统计出现次数的。
- 取map的entrySet,只要对应的value值大于maxTime,就更新。
- 接着还是对entry进行遍历,只要当前entry的value和maxtime相等,那么说明找到了一个符合要求的值,为什么?因为一旦找到之后,就向数组的第k-1个位置添加当前entry的key,并且k–。这个k–的目的就是说我现在已经有一个了,那么前k个就变成了前k-1。如果遍历entry没有找到找到maxtime对应的,那就让maxtime–,这一步就是说,maxtime记录最大次数,一旦我找到这个最大次数之后,下一轮我就应该找第二大的,那么这个出现的次数就要随之减少。
-
代码
class Solution { public int[] topKFrequent(int[] nums, int k) { int[] res = new int[k]; Map<Integer, Integer> map = new HashMap<>(); for(int num : nums){ map.put(num, map.getOrDefault(num, 0) + 1); } int maxTime = 0; for(Map.Entry<Integer, Integer> entry: map.entrySet()){ if(entry.getValue() > maxTime){ maxTime = entry.getValue(); } } while(k > 0){ for(Map.Entry<Integer,Integer> entry : map.entrySet()){ if(entry.getValue() == maxTime){ res[k - 1] = entry.getKey(); k--; } } maxTime--; } return res; } }
76. 最小覆盖子串 - 力扣(LeetCode) (leetcode-cn.com)
-
题解:【数据结构和算法】滑动窗口,视频演示 - 最小覆盖子串 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
- 滑动的就是只左右都可以进行移动,但是怎么移就是关键了。
- 先将t字符串扫进map中,定义一个窗口的左右边界,用来滑动,同时定义满足条件的窗口的开始位置以及满足条件的窗口的长度。
- 窗口如何移动呢?那就是只要窗口的右边界没有超过字符串长度就可以,每次扫描的时候要记录右指针扫描过的字符。
- 右指针的目的就是扫描s字符串中含有t字符串中字符的。
- 如果右指针扫描的字符存在在map中,那么就减1,说明前面已经扫描到有相同字符的。
- 记录完成之后再右指针前移。
- 检查这段窗口是否都覆盖了t中的字符,如果都覆盖就要移动左边界。没有覆盖继续移动右边界。
- 检查工作?因为上面说到有存在的就-1,那么map中的value值,只要有小于0的,就直接返回false。没有小于0的,就返回true。
- 一旦串口覆盖了t中的字符串,那么就要找最小的全部能覆盖的窗口
- 更新窗口的长度,只要右-左的长度小于初始化的长度,并且此时窗口的开始位置就是左。
- 因为是找最小,左移每次要移除窗口最左边的元素,就是缩小窗口的大小。获取s字符串在最左边的元素,一旦map中存在这个元素,那么将这个元素+1,其实就是操作t所对应的map,只有当map中的只有小于等于0的时候才是找到最小的。同时左指针也右移。
- 更新窗口的长度,只要右-左的长度小于初始化的长度,并且此时窗口的开始位置就是左。
- 最后只要长度不是原始值,那么就有最小的覆盖子串。
-
代码
class Solution { public String minWindow(String s, String t) { //先把t中的字符扫进map中 Map<Character, Integer> map = new HashMap<>(); for(char c : t.toCharArray()){ map.put(c,map.getOrDefault(c, 0) + 1); } //左右边界 int left = 0; int right = 0; //满足条件的起始位置和窗口的长度。 int strStart = 0; int windowLength = Integer.MAX_VALUE; //只要右边界在s串内都可以 while(right < s.length()){ //先扫描s串的右边界,看是否在map中,如果在,那么说明s串中有一个可以进行覆盖的元素,那么map对应的value就要-1 char rightChar = s.charAt(right); if(map.containsKey(rightChar)){ map.put(rightChar, map.getOrDefault(rightChar, 0) - 1); } //扫描完成,右边界向右移动 right++; //检查map中的元素是否是满足条件 while(check(map)){ //更新起始位置和窗口长度 if(right - left < windowLength){ windowLength = right - left; strStart = left; } //移除窗口的左边界元素 char leftChar = s.charAt(left); //如果移除的这个元素在map中有,那么就+1 if(map.containsKey(leftChar)){ map.put(leftChar, map.getOrDefault(leftChar, 0) + 1); } //滑动永远向右 left++; } } //找到合适的窗口就进行截取 if(windowLength != Integer.MAX_VALUE){ return s.substring(strStart, strStart + windowLength); }else { return ""; } } //检查窗口是否把字符串t中所有的字符都覆盖了,如果map中所有的value的值都不大于0,那么说明实现了全部覆盖 //为什么是不大于0?因为根据扫描t的时候map决定的。所以只能是不大于0. public boolean check(Map<Character, Integer> map){ for(int value : map.values()){ if(value > 0){ return false; } } return true; } } -
简述:
1. 先将t串扫描进map,记录每次字符出现的次数 2. 左右边界,用来确定最后窗口的大小。以及起始位置和窗口大小。 3. 右边界移动,得到每个右边界字符,到map中查看是否有,如果有,那么就-1。不管是否存在该字符,有边界要一直移动到最右端。 3.1. 每移动一次,都要对map检查,因为按照规则,当s串的某个字符出现在t串的时候,该字符对应map中的值减1,所以一旦某个字符大于1,那么一定不包含。 3.2. 完成检查之后,开始移动左边界元素,map中存在左边界元素,那么就给对应值加1.左边界一直移动(前提还是map中包含了t的所有字符)。 4. 完成扫描了,那么就得到值了。
3. 无重复字符的最长子串 - 力扣(LeetCode) (leetcode-cn.com)
-
思路:
-
使用哈希表和双指针i,j。i负责扫描重复的字符串,j负责扫描字符串。
-
扫描字符串,获得每次扫描的字符。并将该字符放入map中,使用到getOrDeafault()。
-
只要该字符在map中出现的次数大于1,定位在i位置的字符,这个字符已经出现至少两次了。然后将这个重复的字符放入map中,val值就是获取reapt-1,因为计算了一次,就要减少它重复的次数。同时将i++。之后的字符也可能是再次出现的,所以在判断重复字符串的时候使用循环while。
-
res就是res和j-1+1的最大值,j是用来向前扫描的,i是用来定位到重复的字符串的,+1是因为返回的是长度。
-
返回res;
-
-
代码
class Solution { public int lengthOfLongestSubstring(String s) { int n = s.length(); Map<Character, Integer> map = new HashMap<>(); int res = 0; for(int i = 0, j = 0; j < n; j++){ char cur = s.charAt(j); map.put(cur, map.getOrDefault(cur,0) + 1); while(map.get(cur) > 1){ char repeat = s.charAt(i); map.put(repeat, map.get(repeat) - 1); i++; } res = Math.max(res, j - i + 1); } return res; } }