python决策树画树
Yes, you read it right !! A tree can take decision !!
是的,你没有看错 !! 一棵树可以做出决定!
介绍: (Introduction:)
When we are implementing the Decision Tree algorithm using sklearn, we are calling the sklearn library methods. Hence we are not implementing the algorithm from scratch.
当我们使用sklearn实现决策树算法时,我们将调用sklearn库方法。 因此,我们不是从头开始实现该算法。
In this article, we will be implementing a Decision Tree algorithm without relying on Python’s easy-to-use sklearn library. The goal of this post is to discuss the fundamental mathematics and statistics behind a Decision Tree algorithm model. I hope this will help you understand at a low level, how Decision Tree works in the background.
在本文中,我们将实现决策树算法,而不依赖于Python的易于使用的sklearn库。 这篇文章的目的是讨论决策树算法模型背后的基本数学和统计学。 我希望这能帮助您从低层次了解决策树在后台的工作方式。
A decision tree algorithm, is a machine learning technique, for making predictions. As its name suggests, it behaves like a tree structure. The decision tree is built by, repeatedly splitting, training data, into smaller and smaller samples.Decision Tree works on, the principle of conditions. The algorithm checks conditions, at a node, and split the data, as per the result, of the conditional statement. Decision Tree algorithm belongs to, the family of, supervised machine learning algorithms. It can be used to, build classification, as well as regression models. In this article, we are going to discuss, how to implement, a simple Decision Tree, from scratch in Python. This means we are not going to use, any machine learning libraries, like sklearn.
决策树算法是一种用于进行预测的机器学习技术。 顾名思义,它的行为就像树形结构。 决策树是通过反复地将训练数据分成越来越小的样本来构建的。决策树基于条件原理。 该算法检查节点上的条件,并根据条件语句的结果拆分数据。 决策树算法属于有监督的机器学习算法家族。 它可以用于建立分类以及回归模型。 在本文中,我们将从头开始讨论如何实现简单的决策树。 这意味着我们将不使用任何机器学习库,例如sklearn。
Note that this is one of the posts in the series Machine Learning from Scratch. You may like to read other similar posts like Gradient Descent From Scratch, Linear Regression from Scratch, Logistic Regression from Scratch, Neural Network from Scratch in Python
请注意,这是Scratch机器学习系列中的文章之一。 您可能想阅读其他类似的文章,例如Scratch中的Gradient Descent,Scratch中的线性回归,Scratch中的Logistic回归,Python Scratch中的Neural Network。
You may like to watch this article as a video, in more detail, as below:
您可能希望通过以下视频更详细地观看本文:
演示地址
Implementation:
实现方式:
一般条款: (General Terms:)
Let us first discuss a few statistical concepts used in this post.
让我们首先讨论本文中使用的一些统计概念。
Entropy: The entropy of a dataset, is a measure the impurity, of the dataset Entropy can also be thought, as a measure of uncertainty. We should try to minimize, the Entropy. The goal of machine learning models is to reduce uncertainty or entropy, as far as possible.
熵:数据集的熵是度量数据集的杂质,也可以将熵视为不确定性的度量。 我们应该尽量减少熵。 机器学习模型的目标是尽可能减少不确定性或熵。
Information Gain: Information gain, is a measure of, how much information, a feature gives us about the classes. Decision Trees algorithm, will always try, to maximize information gain. Feature, that perfectly partitions the data, should give maximum information. A feature, with the highest Information gain, will be used for split first.
信息增益:信息增益是一项功能为我们提供有关类的多少信息的度量。 决策树算法将始终尝试以最大化信息增益。 完美分区数据的功能应提供最大的信息。 具有最高信息增益的功能将首先用于分割。
实现方式: (Implementation:)
导入库: (Import Libraries:)
We are going to import NumPy and the pandas library.
我们将导入NumPy和熊猫库。
# Import the required libraries
import pandas as pd
import numpy as np加载数据: (Load Data:)
We will be using pandas to load the CSV data to a pandas data frame.
我们将使用pandas将CSV数据加载到pandas数据框中。
# Load the data
df = pd.read_csv('data-dt.csv')
df.head()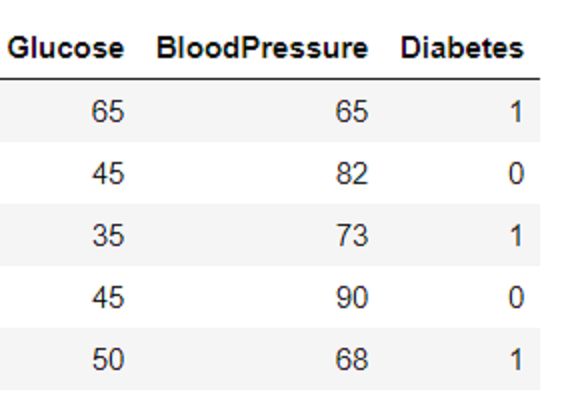
Define the calculate entropy function: we are defining, the calculate entropy function. This function is taking one parameter, the dataset label. After calculation, it is returning, the entropy of the dataset.
定义计算熵函数:我们正在定义计算熵函数。 此函数采用一个参数,即数据集标签。 计算后,它返回的是数据集的熵。
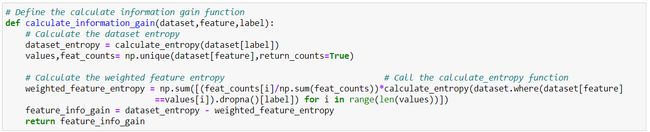
Define the calculate information gain function: This function, is taking three parameters, namely dataset, feature, and label. Here, we are first calculating, the dataset entropy. Then, we are calculating, the weighted feature entropy. Note that, we are calling, the calculate_entropy function, from inside of this function. At the end of this function, we are able to calculate, feature_information_gain, which is equal to, dataset_entropy minus weighted_feature_entropy
定义计算信息增益函数:该函数采用三个参数,即数据集,要素和标签。 在这里,我们首先计算数据集的熵。 然后,我们正在计算加权特征熵。 请注意,我们从该函数内部调用了calculate_entropy函数。 在此函数结束时,我们能够计算feature_information_gain,等于dataset_entropy减去weighted_feature_entropy
Define the create decision tree function: A decision tree, recursively, splits the training set into smaller and smaller subsets Decision trees, are trained by, passing data down, from a root node to leaves. The data is repeatedly split, according to feature variables, so that, child nodes are purer. This helps in reducing entropy. A pure node means, all the samples at that node, have the same label.
定义创建决策树功能:决策树将训练集递归地分成越来越小的子集。决策树是通过将数据从根节点向下传递到叶子来进行训练的。 根据特征变量重复拆分数据,以便子节点更纯净。 这有助于减少熵。 纯节点意味着该节点上的所有样本都具有相同的标签。
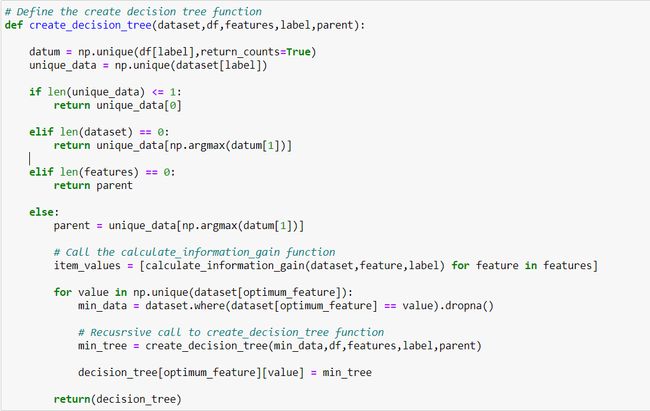
Note the recursive call to create_decision_tree function, towards the end of this function. This is required, as the tree grows recursively.
请注意,在此函数的结尾处,对create_decision_tree函数的递归调用。 这是必需的,因为树递归地增长。
尾注: (Endnotes:)
In this article, I built a Decision Tree model from scratch without using the sklearn library. However, if you will compare it with sklearn’s implementation, it will give nearly the same result.
在本文中,我从头开始构建了决策树模型,而没有使用sklearn库。 但是,如果将其与sklearn的实现进行比较,它将得到几乎相同的结果。
The code is uploaded to Github here.
该代码在此处上传到Github。
Happy Coding !!
快乐编码!
翻译自: https://medium.com/@dhiraj8899/decision-tree-from-scratch-in-python-629631ec3e3a
python决策树画树