sql刷题
文章目录
-
- section A
-
- 1 各部门工资最高的员工(难度:中等)
- 2 换座位(难度:中等)
- 3 分数排名(难度:中等)
- 4 连续出现的数字(难度:中等)
- 5 树节点 (难度:中等)
- 6 至少有五名直接下属的经理 (难度:中等)
- 7 查询回答率最高的问题 (难度:中等)
- 8 各部门前3高工资的员工(难度:中等)
- 9 平面上最近距离 (难度: 困难)
- 10 行程和用户(难度:困难)
- section B
-
- 1 行转列
- 2 列转行
- 3 谁是明星带货主播?
- 4 MySQL 中如何查看sql语句的执行计划?可以看到哪些信息?
- 5 解释一下 SQL 数据库中 ACID 是指什么
- section C
- 1 行转列
- 2 列转行
- 学习收获
-
-
- 知识点合书回忆
- 心得
- 刷题经验总结
-
section A
1 各部门工资最高的员工(难度:中等)
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
+----+-------+--------+--------------+
创建Department 表,包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
-- 创建
create table Employee (
Id int not null,
Name varchar(6),
Salary int,
DepartmentId int,
primary key (Id)
);
insert into Employee values
(1, 'Joe', 70000, 1),
(2, 'Henry', 80000, 2),
(3, 'Sam', 60000, 2),
(4, 'Max', 90000, 1);
create table Department(Id int,
Name varchar(6),
primary key (Id));
insert
into
Department
values (1,
'IT'),
(2,
'Sales');
-- 查询方法1
create view view_employee as (
select
D.Name as Department,
E.Name as Employee ,
E.Salary as Salary
from
Employee as E,
Department as D
where
E.DepartmentId = D.Id)
select Department, Employee, Salary
from view_employee as e
where e.Salary = (select max(e2.Salary) from view_employee as e2 where e.Department = e2.Department)
-- 查询方法2
select e1.Department, e2.Name, e1.Salary
from
(select d.Name as Department, max(e.Salary) as Salary
from employee as e
inner join department as d
on e.DepartmentId = d.Id
group by Department) as e1, employee as e2
where e1.Salary = e2.Salary
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| Sales | Henry | 80000 |
| IT | Max | 90000 |
+------------+----------+--------+
- 主键是不能重复,但是不会自增,仍要手动插入;或设置
AUTO_INCREMENT - 两表联合查询,先连结。
- 可以先找出部分想要的列再和别的表合并。
2 换座位(难度:中等)
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的id是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
+---------+---------+
| id | student |
+---------+---------+
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
+---------+---------+
假如数据输入的是上表,则输出结果如下:
+---------+---------+
| id | student |
+---------+---------+
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
+---------+---------+
注意: 如果学生人数是奇数,则不需要改变最后一个同学的座位。
create table seat (id int auto_increment primary key, student varchar(10));
insert into seat (student) values ('Abbot'), ('Doris'), ('Emerson'), ('Green'), ('Jeames');
delimiter //
create procedure `sp_exchangeseat`()
begin
DECLARE i int;
DECLARE total int default 0;
declare up varchar(10);
declare down varchar(10);
SET i = 0;
SELECT COUNT(*) INTO total from seat;
while i < total-1 do
set i = i + 2;
SELECT student INTO up FROM seat WHERE id = i;
SELECT student INTO down FROM seat WHERE id = i - 1;
prepare s1 from 'update seat set student = ? where id = ?';
set @up_var = up;
set @down_var = down;
set @i1 = i-1;
set @i2 = i;
execute s1 using @up_var, @i1;
execute s1 using @down_var, @i2;
DEALLOCATE PREPARE s1;
end while;
end //
delimiter ;
call sp_exchangeseat()
-- 运行结果和示例相同
- while 应以 end while结束
- 所有声明应写在begin… end开头
- 变量需要声明,@变量可以直接set
- 最后要加上
delimiter ;
3 分数排名(难度:中等)
假设在某次期末考试中,二年级四个班的平均成绩分别是 93、93、93、91。
+-------+-----------+
| class | score_avg |
+-------+-----------+
| 1 | 93 |
| 2 | 93 |
| 3 | 93 |
| 4 | 91 |
+-------+-----------+
目前有如下三种排序结果,请根据查询结果书写出查询用 sql
+-------+-----------+-------+-------+-------+
| class | score_avg | rank1 | rank2 | rank3 |
+-------+-----------+-------+-------+-------+
| 1 | 93 | 1 | 1 | 1 |
| 2 | 93 | 1 | 1 | 2 |
| 3 | 93 | 1 | 1 | 3 |
| 4 | 91 | 4 | 2 | 4 |
+-------+-----------+-------+-------+-------+
select class
, score_avg
, rank() over (order by score_avg desc) as rank1
, dense_rank() over (order by score_avg desc) as rank2
, row_number() over (order by score_avg desc) as rank3
from `a-3`
-- 运行结果和示例相同
4 连续出现的数字(难度:中等)
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
+----+-----+
| Id | Num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
select distinct num as ConsecutiveNums
from
(
select num,
lead(num, 1) over (order by id) as next1,
lead(num, 2) over (order by id) as next2
from a_4) as tem
where
num = next1 and num = next2
-- 运行结果和示例相同
5 树节点 (难度:中等)
对于tree表,id是树节点的标识,p_id是其父节点的id。
+----+------+
| id | p_id |
+----+------+
| 1 | null |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
+----+------+
每个节点都是以下三种类型中的一种:
- Root: 如果节点是根节点。
- Leaf: 如果节点是叶子节点。
- Inner: 如果节点既不是根节点也不是叶子节点。
写一条查询语句打印节点id及对应的节点类型。按照节点id排序。上面例子的对应结果为:
+----+------+
| id | Type |
+----+------+
| 1 | Root |
| 2 | Inner|
| 3 | Leaf |
| 4 | Leaf |
| 5 | Leaf |
+----+------+
说明
- 节点’1’是根节点,因为它的父节点为NULL,有’2’和’3’两个子节点。
- 节点’2’是内部节点,因为它的父节点是’1’,有子节点’4’和’5’。
- 节点’3’,‘4’,'5’是叶子节点,因为它们有父节点但没有子节点。
下面是树的图形:
1
/ \
2 3
/ \
4 5
注意
如果一个树只有一个节点,只需要输出根节点属性。
select id,
case when p_id is null then 'Root'
when id in (select p_id from tree) then 'Inner'
else 'Leaf'
end as type
from tree;
-- 运行结果和示例相同
6 至少有五名直接下属的经理 (难度:中等)
Employee表包含所有员工及其上级的信息。每位员工都有一个Id,并且还有一个对应主管的Id(ManagerId)。
+------+----------+-----------+----------+
|Id |Name |Department |ManagerId |
+------+----------+-----------+----------+
|101 |John |A |null |
|102 |Dan |A |101 |
|103 |James |A |101 |
|104 |Amy |A |101 |
|105 |Anne |A |101 |
|106 |Ron |B |101 |
+------+----------+-----------+----------+
针对Employee表,写一条SQL语句找出有5个下属的主管。对于上面的表,结果应输出:
+-------+
| Name |
+-------+
| John |
+-------+
注意:
没有人向自己汇报。
select name
from
(select managerId
from Employee
group by managerId
having count(*)>=5) as e
inner join
Employee
on Employee.id = e.managerId
-- 运行结果和示例相同
7 查询回答率最高的问题 (难度:中等)
求出survey_log表中回答率最高的问题,表格的字段有:uid, action, question_id, answer_id, q_num, timestamp。
uid是用户id;action的值为:“show”, “answer”, “skip”;当action是"answer"时,answer_id不为空,相反,当action是"show"和"skip"时为空(null);q_num是问题的数字序号。
写一条sql语句找出回答率(show 出现次数 / answer 出现次数)最高的 question_id。
举例:
输入
| uid | action | question_id | answer_id | q_num | timestamp |
|---|---|---|---|---|---|
| 5 | show | 285 | null | 1 | 123 |
| 5 | answer | 285 | 124124 | 1 | 124 |
| 5 | show | 369 | null | 2 | 125 |
| 5 | skip | 369 | null | 2 | 126 |
输出
| question_id |
|---|
| 285 |
说明
问题285的回答率为1/1,然而问题369的回答率是0/1,所以输出是285。
注意:
最高回答率的意思是:同一个问题出现的次数中回答的比例。
select question_id
from(SELECT question_id,
COUNT(CASE WHEN action = 'answer' THEN 1 END) / COUNT(CASE WHEN action = 'show' THEN 1 END) AS answer_rate
FROM survey_log
GROUP BY question_id
ORDER BY answer_rate DESC, question_id limit 1) as subquery;
-- 运行结果和示例相同
8 各部门前3高工资的员工(难度:中等)
将练习一中的 employee 表清空,重新插入以下数据(也可以复制练习一中的 employee 表,再插入第5、第6行数据):
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
+----+-------+--------+--------------+
编写一个 SQL 查询,找出每个部门工资前三高的员工。例如,根据上述给定的表格,查询结果应返回:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
此外,请考虑实现各部门前N高工资的员工功能。
select Department, Employee, Salary
from(select
d.name as Department,
e.name as Employee,
e.salary as Salary,
dense_rank() over (partition by d.name order by e.salary desc) as r
from Employee as e
inner join Department as d
on e.departmentId = d.id ) as subsql
where r <= 3
-- 运行结果和示例相同
9 平面上最近距离 (难度: 困难)
point_2d表包含一个平面内一些点(超过两个)的坐标值(x,y)。
写一条查询语句求出这些点中的最短距离并保留2位小数。
|x | y |
|----|----|
| -1 | -1 |
| 0 | 0 |
| -1 | -2 |
最短距离是1,从点(-1,-1)到点(-1,-2)。所以输出结果为:
| shortest |
1.00
+--------+
|shortest|
+--------+
|1.00 |
+--------+
**注意:**所有点的最大距离小于10000。
SELECT ROUND(MIN(SQRT(POWER(p1.x - p2.x, 2) + POWER(p1.y - p2.y, 2))), 2) AS shortest
FROM point_2d p1, point_2d p2
WHERE p1.x != p2.x OR p1.y != p2.y;
-- 运行结果和示例相同
- 考察笛卡尔积
10 行程和用户(难度:困难)
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
| Id | Client_Id | Driver_Id | City_Id | Status | Request_at |
|---|---|---|---|---|---|
| 1 | 1 | 10 | 1 | completed | 2013-10-1 |
| 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-1 |
| 3 | 3 | 12 | 6 | completed | 2013-10-1 |
| 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-1 |
| 5 | 1 | 10 | 1 | completed | 2013-10-2 |
| 6 | 2 | 11 | 6 | completed | 2013-10-2 |
| 7 | 3 | 12 | 6 | completed | 2013-10-2 |
| 8 | 2 | 12 | 12 | completed | 2013-10-3 |
| 9 | 3 | 10 | 12 | completed | 2013-10-3 |
| 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-3 |
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+
| Users_Id | Banned | Role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
写一段 SQL 语句查出2013年10月1日至2013年10月3日期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
+------------+-------------------+
| Day | Cancellation Rate |
+------------+-------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
+------------+-------------------+
select request_at as Day,
round(count(case when not T.status = 'completed' then 1 end)/count(*),2) as `Cancellation Rate`
from Trips as T
inner join Users as u1 on (T.client_id = u1.users_id and u1.banned='No')
inner join Users as u2 on (T.driver_id = u2.users_id and u2.banned='No')
where T.request_at BETWEEN '2013-10-01' AND '2013-10-03'
group by Day
-- 运行结果和示例相同
- 先把题目要求的范围找到,该剔除的都剔除,再在找到的表中做查询
- 难点是正确剔除被ban的用户。司机和用户共用一套ID体系。
section B
1 行转列
假设 A B C 三位小朋友期末考试成绩如下所示:
+-----+-----------+------|
| name| subject |score |
+-----+-----------+------|
| A | chinese | 99 |
| A | math | 98 |
| A | english | 97 |
| B | chinese | 92 |
| B | math | 91 |
| B | english | 90 |
| C | chinese | 88 |
| C | math | 87 |
| C | english | 86 |
+-----+-----------+------|
请使用 SQL 代码将以上成绩转换为如下格式:
+-----+-----------+------|---------|
| name| chinese | math | english |
+-----+-----------+------|---------|
| A | 99 | 98 | 97 |
| B | 92 | 91 | 90 |
| C | 88 | 87 | 86 |
+-----+-----------+------|---------|
select name,
sum(case when subject='chinese' then score end) as chinese,
sum(case when subject='math' then score end) as math,
sum(case when subject='english' then score end) as english
from students
group by name
-- 运行结果和示例相同
- 行转列用sum case
- 当待转换列为数字时,可以使用
SUM AVG MAX MIN等聚合函数; - 当待转换列为文本时,可以使用
MAX MIN等聚合函数
2 列转行
假设 A B C 三位小朋友期末考试成绩如下所示:
+-----+-----------+------|---------|
| name| chinese | math | english |
+-----+-----------+------|---------|
| A | 99 | 98 | 97 |
| B | 92 | 91 | 90 |
| C | 88 | 87 | 86 |
+-----+-----------+------|---------|
请使用 SQL 代码将以上成绩转换为如下格式:
+-----+-----------+------|
| name| subject |score |
+-----+-----------+------|
| A | chinese | 99 |
| A | math | 98 |
| A | english | 97 |
| B | chinese | 92 |
| B | math | 91 |
| B | english | 90 |
| C | chinese | 88 |
| C | math | 87 |
| C | english | 86 |
+-----+-----------+------|
SELECT name, 'chinese' AS subject, chinese AS score FROM students_scores
UNION all
SELECT name, 'math' AS subject, math AS score FROM students_scores
UNION all
SELECT name, 'english' AS subject, english AS score FROM students_scores
ORDER BY name, subject;
-- 运行结果和示例相同
- union 实现列转行
3 谁是明星带货主播?
假设,某平台2021年主播带货销售额日统计数据如下:
表名 anchor_sales
+-------------+------------+---------|
| anchor_name | date | sales |
+-------------+------------+---------|
| A | 20210101 | 40000 |
| B | 20210101 | 80000 |
| A | 20210102 | 10000 |
| C | 20210102 | 90000 |
| A | 20210103 | 7500 |
| C | 20210103 | 80000 |
+-------------+------------+---------|
定义:如果某主播的某日销售额占比达到该平台当日销售总额的 90% 及以上,则称该主播为明星主播,当天也称为明星主播日。
请使用 SQL 完成如下计算:
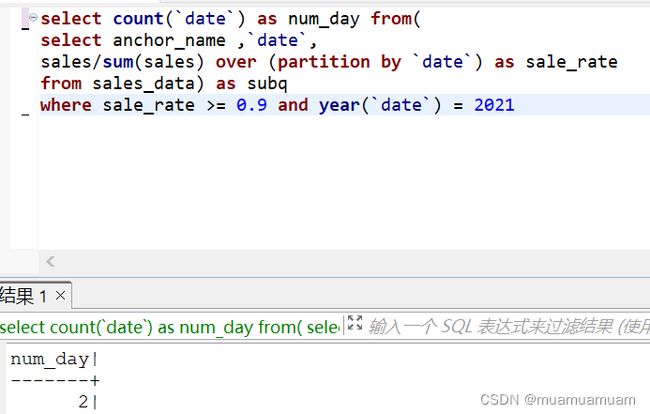
a. 2021年有多少个明星主播日?答:2天
select count(`date`) as num_day from(
select anchor_name ,`date`,
sales/sum(sales) over (partition by `date`) as sale_rate
from sales_data) as subq
where sale_rate >= 0.9 and year(`date`) = 2021
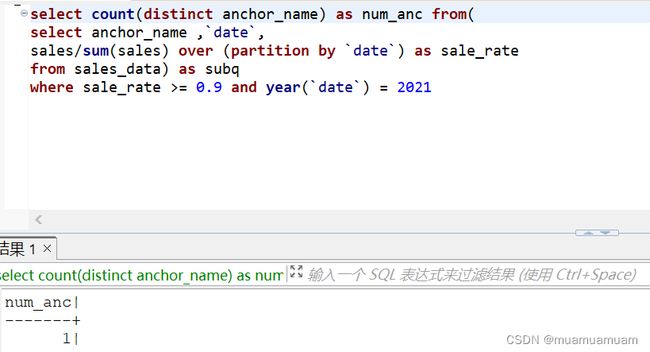
b. 2021年有多少个明星主播?答:1个
select count(distinct anchor_name) as num_anc from(
select anchor_name ,`date`,
sales/sum(sales) over (partition by `date`) as sale_rate
from sales_data) as subq
where sale_rate >= 0.9 and year(`date`) = 2021
4 MySQL 中如何查看sql语句的执行计划?可以看到哪些信息?
explain
这部分暂时还不太能看懂
-
id 执行顺序
-
select_type 每个select子句的类型
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果)
(6) SUBQUERY(子查询中的第一个SELECT)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
-
table 正在访问的表名
-
partitions
-
type 访问类型
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
-
possible_keys 指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
-
key 显示MySQL实际决定使用的键(索引)
-
key_len 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
-
ref
-
rows
-
filtered
-
Extra
5 解释一下 SQL 数据库中 ACID 是指什么
ACID,是指在可靠数据库管理系统(DBMS)中,事务(transaction)所应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
section C
1 行转列
假设有如下比赛结果:
+--------------+-----------+
| cdate | result |
+--------------+-----------+
| 2021-01-01 | 胜 |
| 2021-01-01 | 胜 |
| 2021-01-01 | 负 |
| 2021-01-03 | 胜 |
| 2021-01-03 | 负 |
| 2021-01-03 | 负 |
+------------+-------------+
请使用 SQL 将比赛结果转换为如下形式:
+--------------+-----+-----|
| 比赛日期 | 胜 | 负 |
+--------------+-----------+
| 2021-01-01 | 2 | 1 |
| 2021-01-03 | 1 | 2 |
+------------+-----------+
select cdate as '比赛日期',
sum(case when result='胜' then 1 end) as '胜',
sum(case when result='负' then 1 end) as '负'
from game_results
group by cdate
2 列转行
假设有如下比赛结果:
+--------------+-----+-----|
| 比赛日期 | 胜 | 负 |
+--------------+-----------+
| 2021-01-01 | 4 | 1 |
| 2021-01-03 | 1 | 4 |
+------------+-----------+
请使用 SQL 将比赛结果转换为如下形式:
+--------------+-----------+
| cdate | result |
+--------------+-----------+
| 2021-01-01 | 胜 |
| 2021-01-01 | 胜 |
| 2021-01-01 | 胜 |
| 2021-01-01 | 胜 |
| 2021-01-01 | 负 |
| 2021-01-03 | 胜 |
| 2021-01-03 | 负 |
| 2021-01-03 | 负 |
| 2021-01-03 | 负 |
| 2021-01-03 | 负 |
+------------+-------------+
学习收获
知识点合书回忆
创建数据库,创建删除表;修改表,插入数据。
基本查询:select … from … where … group by … order by … having …
执行顺序:from > where > group by > select > having > order by
关联子查询(先执行select from),标量子查询
聚合函数,算数函数,字符串函数,case,谓词
集合运算(union,对称差),连结 (inner join; left / right join),笛卡尔积
视图,窗口函数,利用窗口函数求移动平均,rollup
存储过程,预处理声明
心得
- 多动手才能学会,对于刚刚学过的知识点,自己动手实现一遍。
- SQL 的思维方式和高级编程语言很不一样,目前我还没有总结出SQL的核心思想,可能还需要系统地学习数据库。
- 这半个月的学习帮助我SQL入门,为以后的学习打下基础。
刷题经验总结
- 题目提供了多个表的,一般要把多表连结,连结条件可能比较复杂,这就是难题所在。
- 大多数题目会使用子查询
- 目前知识已经涵盖了绝大多数题目考察范围,接下来可以看看红皮书和刷题。