《Presto(Trino)——The Definitive Guide》Presto指南20版
Presto系列文章目录
This book provides a great introduction to Presto and teaches you everything
you need to know to start your successful usage of Presto.
—Dain Sundstrom and David Phillips, Creators of the Presto
Projects and Founders of the Presto Software Foundation
Presto plays a key role in enabling analysis at Pinterest. This book covers the Presto essentials, from use cases through how to run Presto at massive scale.
—Ashish Kumar Singh, Tech Lead,
Bigdata Query Processing Platform, Pinterest

文章目录
- Presto系列文章目录
- 前言
- 一、Presto in Production
-
- Monitoring with the Presto Web UI
-
- Cluster-Level Details
- Query List
- Query Details View
-
- Overview
- Live Plan
- Stage Performance
- Splits
- JSON
- Tuning Presto SQL Queries
- Tuning the CBO
- Memory Management
- Task Concurrency
- Worker Scheduling
-
- Scheduling Splits per Task and per Node
- Local Scheduling
- Network Data Exchange
- Concurrency
- Buffer Sizes
- Tuning Java Virtual Machine
- Resource Groups
-
- Resource Group De€nition
- Scheduling Policy
- Selector Rules Definition
- 总结
前言
Presto: The Definitive Guide SQL at Any Scale, on Any Storage,in Any Environment
——Matt Fuller, Manfred Moser, and Martin Traverso
- Part I. Getting Started with Presto
-
- Introducing Presto.
-
- Installing and Con€guring Presto
-
- Using Presto
- Part II. Diving Deeper into Presto
-
- Presto Architecture
-
- Production-Ready Deployment
-
- Connectors.
-
- Advanced Connector Examples
-
- Using SQL in Presto.
-
- Advanced SQL
- Part III. Presto in Real-World Uses
-
- Security
-
- Integrating Presto with Other Tools
-
- Presto in Production.
-
- Real-World Examples
-
- Conclusion.
- Index
提示:以下是本篇文章正文内容,非专业翻译,下面翻译仅供参考
一、Presto in Production
因为最近上手presto测试与选型,从客户端到WebUI,排查每条SQL语句的执行情况,包括队列阻塞,资源不足,内部错误等一系列问题,因此先从生产环境认识Presto(Trino)更直观。
在了解并安装Presto之后,首先在第2章中作为一个简单的探索性设置,然后作为第5章中的部署,您现在可以深入了解更多细节。 毕竟,简单地说集群的Lling和配置是一项非常不同的任务,它可以日夜保持和运行,不同的用户和改变数据源和完全独立的使用。 在这一章你因此,正在探索您需要了解的其他方面,以便成为Presto集群的成功的操作员。
Monitoring with the Presto Web UI
正如第35页“PrestoWebUI”中所讨论的,PrestoWebUI可以在每个Presto集群协调器上访问,并且可以用于检查和监视Presto集群和处理的查询。 提供的细节信息可以用来更好地理解和调整Presto系统的整体以及单个查询。
- The Presto Web UI exposes information from the Presto system
tables, discussed in “Presto System Tables” on page 134.
Presto Web UI公开了Presto系统表中的信息,在第134页的“Presto系统表”中进行了讨论。
当您第一次导航到Presto Web UI地址时,您将看到图12-1所示的主仪表板。 它在顶部部分显示Presto集群信息,在底部se显示查询列表Ction
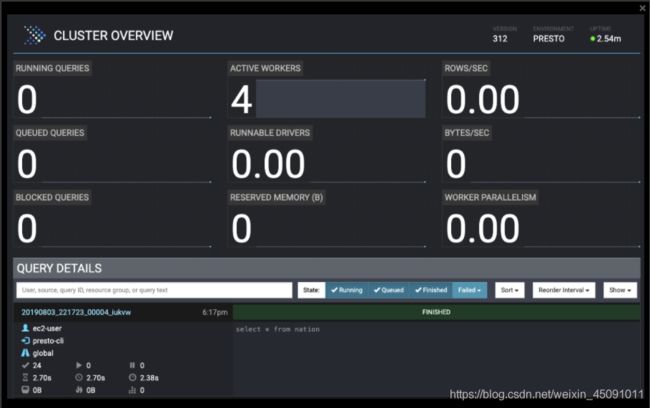
Figure 12-1. Presto Web UI main dashboard
Cluster-Level Details
让我们首先讨论当前集群信息:
- Running Queries
当前在当前集群中运行的查询总数。这占了所有用户的账户。例如,如果爱丽丝在跑步两个查询和Bob正在运行五个查询,此框中的总数显示了七个查询。 - Queued Queries
所有用户的Presto集群的排队查询总数。
排队查询ar等待协调器根据资源组配置来安排它们。 - Blocked Queries
集群中阻塞查询的数量。 由于缺少可用的splits或其他资源,无法处理阻塞的查询。您将在下一节中了解有关查询状态的更多信息。 - Active Workers
集群中Active Workers节点的数量。 添加或删除任何工作节点手动或自动伸缩在发现服务中注册,并相应地更新显示的数字。 - Runnable Drivers
可运行驱动程序集群中可运行驱动程序的平均数量,如第4章所述。 - Reserved Memory
保留内存,Presto中以字节为单位的保留内存总量。 - Rows/每秒
在集群中运行的所有查询中处理的行。 - 字节/秒
在集群中运行的所有查询中处理的字节总数。 - Worker Parallelism,这是所有Worker之间的线程CPU时间的总数,跨越在集群中运行的所有查询。
Query List
Presto Web UI仪表板的底部部分列出了最近运行的查询。 图12-2显示了一个示例截图。 此历史列表中可用查询的数量取决于the Presto集群配置。

Figure 12-2. List of queries in the Presto Web UI
在列表本身之上,控件可以选择确定列出哪些查询的标准。 这允许您找到特定的查询,即使集群非常繁忙并运行数百个查询。
输入字段允许您键入标准文本,以便搜索特定的查询。 标准包括查询发起者的用户名、查询源、查询ID、资源g查询的SQL文本和查询状态。 文本输入字段旁边的状态过滤器允许您包含或排除基于查询状态的查询-运行、排队、fini脱落和失败的查询。 失败的查询可以进一步详细说明,以包括或排除特定的失败原因-内部、外部、资源和用户错误。
左边的控件允许您去确定显示的查询的排序顺序、数据更改时重新排序的时间以及要显示的最大查询数量。 查询条件下面的每一行都表示一个单独查询。 行中的左列显示有关查询的信息。 右侧列显示SQL文本和查询状态。 图12提供了查询摘要的Figure 12-3.

Figure 12-3. Information for a specific query in the Presto Web UI
让我们仔细看看查询细节。 每个查询对于每个查询运行都有相同的信息。
左上方的文本是查询ID。 在这个例子中,值是20210225_125918_00134_zvank。 仔细观察,您可能会注意到日期和时间(UTC)使用格式YYYYMMDD_HHMMSS组成ID的开始。 后半部分是查询的增量计数器。 对价00134仅仅意味着这是自协调节点启动以来的第134次查询运行。 最后一段zvank是协调检点的随机标识符。 这个随机标识符和计数器值则如果重新启动协调节点,则重置。 右上角的时间是运行查询的本地时间。 示例中的下三个值——root、trino-cli和global——表示最终用户运行查询、查询的来源和用于运行查询的资源组。 在本例中,用户是默认的root,我们使用trino-cli提交查询。 如果你在运行PrestoCLI时指定-用户标志,该值将更改为您指定的值。 源也可能是Presto-cli以外的一些东西;例如,当应用程序使用JDBC驱动程序连接到Presto,它可能显示Presto-jdbc。
应用程序使用JDBC驱动程序连接到Presto。 客户端还可以使用Presto CLI或JDBC连接字符串属性的-–source标志将其设置为任何所需的值。
下面的值网格在PrestoWebUI中没有很好的标记,但是它包含了有关查询的一些重要信息,如表12-1所解释的
Table 12-1. Grid of values for a specific query

-
Completed Splits:查询的已完成splits的数量。 示例显示25个已完成的splits。 查询执行开始时,此值为0。 它在查询执行期间随着splits完成而增加。
-
Current Total Reserved Memory:当前用于查询执行时间的总保留内存。 对于已完成的查询,此值为0
-
Peak Total Memory:查询执行期间的峰值总内存使用情况。 查询执行过程中的某些操作可能需要大量内存,了解峰值是什么很有用。
-
Cumulative User Memory: 在整个查询处理过程中使用的累积用户内存。这并不意味着所有内存都是同时使用的。这是内存的累积量。
-
Queued Splits: 查询的排队Splits数量。 查询完成后,此值始终为0。 然而,在执行过程中,这个数字会随着在排队状态和运行状态之间的分割移动而改变。
-
wait time :执行查询所花费的总等待时间。 即使是分页结果,这个值也会继续增长。
-
CPU时间:处理查询的总CPU时间。 这个值通常比wait time 大,因为工人和工人上的线程之间的并行执行都是单独计数并添加up.例如,如果四个CPU花费1秒处理查询,则得到的CPU总时间为4秒
-
Running Splits:查询的运行Splits数。 查询完成后,此值始终为0。 但是,在执行过程中,这个数字会随着Splits运行和完成而改变。
-
Cumulative User Memory: 累积用户内存:在整个查询处理过程中使用的累积用户内存。 这并不意味着所有的内存都是同时使用的。 这是内存的累积量。
-
Presto Web UI中的许多图标和值都有弹出的工具提示,如果您将鼠标光标悬停在图像上,这些提示是可见的。 如果您不确定某个特定的值代表是什么,这将很有帮助。
接下来需要了解更多关于查询处理的不同状态,显示在查询文本本身上面。 最常见的状态是RUNNING、Finished、USER CANCELLED或USERERROR。 运行和完成的状态是不言自明的。 USER CANCELLED表示查询被用户杀死。 另一方面,USER错误表示SQL查询状态用户提交包含语法或语义错误。 当正在运行的查询在等待资源或其他要处理的Splits被阻塞时,就会发生阻塞状态。 看到查询来来去去这个状态是正常的。 但是,如果查询陷入这种状态,存在许多潜在的原因,这可能表明查询或Presto集群存在问题。 如果您发现一个查询似乎被困在这种状态,首先检查内存的使用和系统配置。 这可能是这个查询需要一个不常用的高内存,或者在计算上开销太大。 此外,如果客户端没有检索结果或无法读取结果足够快,这个背压(反压 back pressure)可以将查询放入阻塞状态。
QUEUED状态发生在启动查询或停止处理查询时,并作为为资源组定义的规则的一部分进入等待阶段。查询正在等待执行。您也可以在计划状态中看到查询。 这通常发生在较大的复杂查询中,这些查询需要大量的计划和优化来运行查询。 如果你经常看到这个,计划似乎需要大量的时间来查询,您应该调查可能的原因,例如协调节点的内存不足或处理能力不足。
Query Details View
到目前为止,您已经看到了有关Presto集群的总体信息和有关查询的高级信息。 Web UI提供了更多关于每个查询的详细信息。 只需单击sp的名称即可具体查询,如图12-3所示,以访问查询详细信息视图。 查询详细信息视图包含许多关于特定查询的信息。
- Presto开发人员和对Presto有深入了解的用户经常使用Query Details视图。 这种复杂的水平要求你非常熟悉Presto代码和内部是的。 查看此视图对正常用户仍然有用。 随着时间的推移,你会学到更多,获得更多的专业知识
查询详细信息视图使用几个选项卡查看有关Presto查询的更详细信息。 除了选项卡,查询ID和状态总是可见的。 你可以看到一个例子视图的r与图12-4中的选项卡。

Figure 12-4. Query Details header and tabs
Overview
概述页面包括查询列表的查询详细信息部分中可见的信息,以及许多部分中的更多细节:
• Session
• Execution
• Resource Utilizations Summary
• Timeline
• Query
• Prepare Query
• Stages
• Tasks
Stages部分显示查询阶段的信息,如图12-5所示

Figure 12-5. Stages section in the Overview tab of the Query Details page
此特定查询是SELECT count(*) FROM lineitem query查询。 因为它是一个更简单的查询,所以它只包含两个阶段。 阶段0是在coordinator 上运行的单任务阶段,并且是负责合并第1阶段任务的结果并执行最终聚合。 第一阶段是一个分布式阶段,在每个 workers上运行任务。 这个阶段是负责读取数据并进行部分聚合。
下面的列表解释了每个阶段可用的Stages部分的数值:
- TIME—SCHEDULED
stage在该阶段的所有任务都完成之前的时间数量已完成。
- TIME—BLOCKED
stage在等待数据时被阻塞的时间
- TIME-CPU
- stageTasks的CPUTIME总数。
- MEMORY–CUMULATIVE
在整个stage使用的累积内存。 这并不意味着所有的内存都是同时使用的。 它是在处理时间内使用的累积内存量。
- MEMORY—CURRENT
stage使用的当前总保留内存。 对于已完成的查询,此值为0。
- MEMORY—BUFFERS
数据消耗的内存的当前amout,等待处理。
- MEMORY—PEAK
stage的峰值总内存。 在查询执行过程中的某些操作可能需要大量的内存,并且它被使用很想知道峰是多少。
- TASKS—PENDING
stage的待定Tasks数量。 查询完成后,此值始终为0。
- Tasks-RUNNING
stage的运行Tasks数量。 什么在查询完成时,此值始终为0。 在执行过程中,值随着Tasks的运行和完成而变化。
- TASKS—BLOCKED
阻塞stage的阻塞Tasks数量。 当查询完成后,这个值总是0。 然而,在执行期间,随着Tasks在阻塞状态和运行状态之间移动,这个数字将发生变化。
- TASKS-TOTAL
查询完成的Tasks数。
SCHEDULED TIME SKEW, CPU TIME SKEW, TASK SCHEDULED TIME, and
TASK CPU TIME
设定时间帧、CPU时间帧、设定时间帧和设定时间帧
这些直方图显示了多个任务的调度时间、CPU时间、任务调度时间和任务CPU时间在任务CPU时间的分布和变化。 这允许您诊断在执行较长时间运行的分布式查询过程中的workers的利用率。 下面的章节描述了更多的细节Tasks,如图12-6所示。

Figure 12-6. Tasks information in the Query Details page
让我们检查任务列表中的值;看看表12-2。
Table 12-2. Description of the columns in the tasks list in Figure 12-6

如果你仔细检查其中的一些值,你会注意到它们是如何滚动的。 例如,一个stage中所有任务的总CPU时间等于它们所属stage中列出的CPU时间。stage的总CPU时间等于列出的总的查询CPU时间。
Live Plan
The Live Plan tab allows you to view query processing performed by the Presto clus‐
ter, in real time, while it is executing. You can see an example in Figure 12-7.
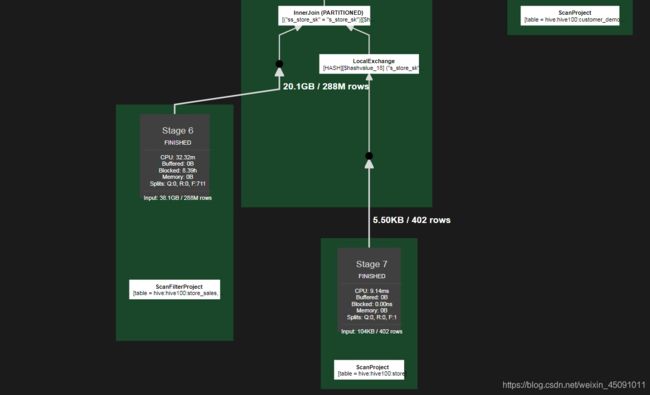
Figure 12-7. Live plan example for the query
在查询执行期间,计划中的计数器在查询执行过程中被更新。 计划中的值与Overview选项卡中描述的值相同,但它们被实时覆盖在查询执行计划上。 查看此视图有助于可视化查询被卡住的地方或花费大量时间,以便诊断或改进性能问题。
Stage Performance
stage性能视图提供了在查询处理完成后stage性能的详细可视化。 图12-8显示了一个示例。 这个视图可以被认为是从LivePlan视图下载,在那里您可以看到任务在stage内的operator pipeline。 计划中的值与概述选项卡中描述的值相同。 看着这个视图就是我们查看查询是否卡住或花费大量时间,以便诊断或修复性能问题。 您可以单击每个单独的操作访问详细信息。
 Figure 12-8. Presto Web UI view for stage performance of the query
Figure 12-8. Presto Web UI view for stage performance of the query
Splits
Splits视图显示了在查询执行期间创建和处理Splits的时间表。
JSON
JSON选项卡以JSON格式提供所有查询详细信息。 信息根据检索到的快照更新。
- Web UI部分有助于将冗长的字符串复制到系统剪贴板。 注意剪贴板图标。 通过点击它,关联字符串被复制到系统剪贴板,供您粘贴到其他地方。
Tuning Presto SQL Queries
调优Presto SQL查询
在第53页的“查询规划”中,您了解了Presto中基于成本的优化器。 回想一下,SQL是一种声明性语言,在这种语言中,用户编写SQL查询来指定他们想要的数据。 太好了这不像一个命令程序。 使用SQL,用户不指定如何处理数据以获得结果。 它留给查询计划器和优化器来确定pr的步骤顺序处理所需结果的数据。 步骤顺序称为查询计划query plan。 在大多数情况下,提交SQL查询的最终用户可以依赖Presto来计划、优化和执行一个SQL查询,以快速获得结果。 作为最终用户,你不必担心细节。 然而,有时你没有得到你期望的表现,所以你需要调优Presto查询。 您需要识别一个特定的执行是否是一个执行情况不佳的离群点单个查询,还是类似属性的多个查询执行情况不佳。 让我们从调整单个查询开始,假设您运行的其余查询在系统上是好的。 在检查性能不佳的查询时,您应该首先查看查询引用的表是否有数据统计。 在编写此文档时,唯一向Presto提供数据统计的表是与Hive连接器一起使用的表。 预计其它连接器将开始提供数据统计。
presto:ontime> SHOW STATS FOR flights;
join SQL是最重要的操作之一。 在优化查询的性能时,您需要专注于连接,并通过在查询上运行EXPLAIN来确定连接顺序。
presto:ontime> EXPLAIN
SELECT f.uniquecarrier, c.description, count(*) AS ct
FROM postgresql.airline.carrier c,
hive.ontime.flights_orc f
WHERE c.code = f.uniquecarrier
GROUP BY f.uniquecarrier, c.description
ORDER BY count(*) DESC
LIMIT 10;
通常,您希望连接的较小输入位于构建侧build侧。 这是对哈希连接的输入,哈希表是为此构建的。 因为构建侧需要在ent中读取在内存中输入并构建哈希表,您希望这是较小的输入。 能够确定Presto是否得到了正确的连接顺序,需要一些da的领域知识进一步调查。 例如,如果你对数据一无所知,你可能需要运行一些经验查询来获得更多的信息。
如果您已经确定连接顺序不是最优的,您可以通过设置切换来使用SQL查询中列出的表的语法顺序来覆盖连接重新排序策略。 这个可以在config.properties文件中配置为属性优化器.join-重新排序策略。 但是,如果要覆盖单个查询,通常只希望看到会话属性join_reordering_strategy(见第146页的“会话信息和配置)。 此属性的允许值是自动、ELIMINATE_CROSS_JOINS和无。 将值设置为ELIMINATE_CROSS_JOINS或NONE执行基于成本的优化器的覆盖。 ELIMINATE_CROSS_JOINS是一个很好的妥协,因为它重新订购只连接到Elimi-Nate交叉连接,这是良好的做法,否则保持查询作者建议的词汇顺序:
presto:ontime> EXPLAIN
SELECT f.uniquecarrier, c.description, count(*) AS ct
FROM postgresql.airline.carrier c,
hive.ontime.flights_orc f
WHERE c.code = f.uniquecarrier
GROUP BY f.uniquecarrier, c.description
ORDER BY count(*) DESC
LIMIT 10;
通常,您希望连接的较小输入在生成侧。这是为其建立哈希表的哈希联接的输入。因为建造方面
需要读取整个输入并在内存中构建哈希表这是较小的输入。能够确定Presto是否获得了
加入顺序正确需要对数据有一定领域知识,以便进一步研究。例如,如果您对数据一无所知,则可能需要运行一些实验。精神查询以获得其他信息。
如果确定联接顺序不是最优的,则可以覆盖联接通过设置切换以使用表中列出的表的句法顺序来进行重新排序策略SQL查询。可以在config.properties文件中将其配置为属性Optimizer.join-reordering-strategy。但是,如果您要覆盖单个查询,您通常只想查看会话属性join_reordering_strategy
(请参阅第146页的“会话信息和配置”)。的允许值此属性为AUTOMATIC,ELIMINATE_CROSS_JOINS和NONE。将值设置为ELIMINATE_CROSS_JOINS或NONE将替代基于成本的优化器。ELIMINATE_CROSS_JOINS是一个很好的折衷方案,因为它仅对与elimi-
固有的交叉联接,这是一种很好的做法,否则保持词汇顺序不变由查询作者建议:
FROM postgresql.airline.carrier c,
hive.ontime.flights_orc f
...
...
FROM hive.ontime.flights_orc f,
postgresql.airline.carrier c
...
Tuning the CBO
默认情况下,Presto基于成本的优化器(CBO)一次最多可重新排序9个表。对于9个以上的表,CBO会分割搜索空间。 例如,如果有查询中有20个表,Presto将前9个表重新排序为一个优化问题,第二个9作为第二个优化问题,最后是剩下的2个表。设置限制的原因是,可能的加入订单数量会按比例缩放。 所以一些需要设置合理的限制。 要增加该值,您可以设置config.properties文件中的optimizer.max-reordered-joins参数。 设定这个较高的值可能会导致Presto花大量时间的性能问题和资源来优化查询。 回想一下,CBO的目标不是获得最佳可能有计划,但要获得足够好的计划。
除了联接优化之外,Presto还包括一些基于启发式的优化。
这些优化器不计成本,也不总是总能获得最佳结果。优化位置可以利用Presto是分布式查询引擎这一事实。聚合是并行执行的。这意味着可以将聚合分为多个较小的零件,然后可以分配给多个工作人员,并在paral中运行并在部分结果的最后一步进行汇总。Presto和其他SQL引擎的常见优化是推送部分聚合连接前的操作,以减少进入连接的数据量。使用它可以使用push_aggregation_through_join属性配置。因为聚集合并会产生部分结果,加入后仍会进行最终聚合。使用此优化的好处取决于实际数据和优化甚至会导致查询变慢。例如,如果联接是高度选择性的,则联接完成后运行聚合可能会更有效。为了体验,您可以简单地通过将当前会话的属性设置为false来关闭此优化。
另一种常见的启发式方法是在最终聚合之前计算部分聚合:
presto:ontime> EXPLAIN SELECT count(*) FROM flights_orc;
Query Plan
---------------------------------------------------------------------
- Output[_col0]
Layout: [count:bigint]
_col0 := count
- Aggregate(FINAL)
Layout: [count:bigint]
count := "count"("count_3")
- LocalExchange[SINGLE] ()
Layout: [count_3:bigint]
- RemoteExchange[GATHER]
Layout: [count_3:bigint]
- Aggregate(PARTIAL)
Layout: [count_3:bigint]
count_3 := "count"(*)
- TableScan[hive:ontime:flights_orc]
Layout: []
(1 row)
通常,这是一个很好的启发式方法时,为哈希保留的内存量表可以调整。 例如,如果表中有很多行,且几乎没有不同的值在分组键中,此优化效果很好,并减少了数据量在通过网络分发之前提早。 但是,如果数量更多如果值不同,则散列表的大小需要更大,以减少数据量。 默认情况下,用于哈希表的内存为16 MB,但这可以通过在con-中设置task.max-partial-aggregation-memory来调整config.properties文件。然而,由于不同组键的计数太高,聚合对减少网络传输没有任何作用,甚至可能会减慢查询速度。
Memory Management
为您的当前集群正确获取内存配置和管理并不是一项容易的任务。许多不断变化的因素影响记忆的需要:
• Number of workers
• Memory of coordinator and worker
• Number and type of data sources
• Characteristics of running queries
• Number of users
对于Presto这个使用工人集群的多用户系统来说,资源管理是一个相当具有挑战性的问题。 最终,你必须选择一个起点,然后监控系统和适应当前和即将到来的需求。 让我们看看一些细节,并谈谈关于普雷斯托记忆管理和监测的建议和指导方针。
- 讨论的所有内存管理都适用于运行JVM Presto服务器。 这些值是JVM上的分配。worker,并且JVM配置需要考虑大小这些值允许分配。根据并发查询的数量,JVM需要调整到更大的值。 下一个示例提供一些观察角度insight。
前述所有因素共同构成了我们所说的工作量。 调整集群的内存严重依赖于正在运行的工作负载。
例如,大多数查询形状包含多个联接,聚合和窗口功能。 如果工作负载的查询大小较小,则可以设置较低的内存限制每个查询并提高并发性;反之,则可用于更大的查询大小。 对于上下文,查询大小是查询形状和输入数据量的乘积。
Presto提供了一种通过设置一些属性来管理整个群集中的内存利用率的方法。
在config.properties中部署时获取属性:
• query.max-memory-per-node
• query.max-total-memory-per-node
• query.max-memory
• query.max-total-memory
Presto中的内存管理分为两种内存分配:
- User memory
用户查询(例如聚合和排序)控制用户内存
分配。 - 系统内存
系统内存分配基于执行的实现查询引擎本身,包括对缓冲区的读取,写入和随机播放,表扫描,和其他操作。考虑到这种分离,您可以进一步检查内存属性: - query.max-memory-per-node
查询可在特定工作程序上利用的最大用户内存用来处理聚合,输入数据分配等 - query.max-total-memory-per-node
用户和系统内存的最大允许总数,比query.max-memory-per-node要更大。
当查询消耗的内存用户和系统分配超出此限制,将被杀死。 - query.max内存
查询可以在群集中的所有工作线程上利用的最大用户内存。 - query.max-总内存
查询用户和系统分配的最大内存使用率
对于整个集群,结果必然大于query.max-memory。
如果查询最终超过了这些限制并被杀死,则错误代码会暴露出原因
- EXCEEDED_LOCAL_MEMORY_LIMIT
表示query.max-memory-per-node或超出了每个节点的query.max总内存。 - EXCEEDED_GLOBAL_MEMORY_LIMIT
表示超出了query.max-memory或query.max total-memory。
让我们来看一个由一个协调节点和十个工作节点组成的小型集群的真实示例及其特征:
• One coordinator
• Ten workers; typically workers are all identical system specifications
• Physical memory per worker: 50 GB
• Max JVM heap size configured in -Xmx in jvm.config to 38 GB
• query.max-memory-per-node: 13 GB
• query.max-total-memory-per-node: 16 GB
• memory.heap-headroom-per-node: 9 GB
• query.max-memory: 50 GB
• query.max-total-memory: 60 GB
让我们进一步分解这些数字。每个工作程序上的总可用内存为〜50 GB,而对于JVM外部运行的操作系统,代理/守护程序和组件系统。这些系统包括监控系统和其他可让您手动操作的系统老化机器并使其正常运转。因此,我们决定设置JVM的最大堆大小为38 GB。
当查询大小和形状较小时,可以将并发设置为更高。在前面例如,我们假设查询的大小和形状为中等到较大,并且考虑数据偏斜。 query.max-memory设置为50 GB,这在总体上集群级别。在查看最大内存时,我们还考虑了初始哈希分区。理想情况下,该数字应小于或等于workers数。
如果将其设置为8,最大内存为50 GB,则得到50/8,因此每个workers大约为6.25 GB。查看设置为13 GB的本地限制每节点最大内存,我们保留了一些每个节点允许两倍的内存消耗,从而为数据倾斜提供了空间。这些数字根据数据的组织方式和查询类型的不同而有很大差异实例通常在运行,基本上是集群的工作负载。
此外,用于群集的基础架构,例如可用的计算机大小和数量,对理想配置的选择有很大影响。可以设置一个配置来避免出现死锁情况:query.low-memory killer.policy。可以将其设置为阻塞节点上的总保留或总保留。设置为总保留时,Presto将终止最大的运行在群集上查询以释放资源。另一方面,总保留的阻塞节点会杀死正在使用以下资源的节点上占用最多内存的查询:被阻止。从示例中可以看到,您最终做出了一些假设开始。然后根据实际工作量进行调整。
例如,运行一个集群以从用户那里获得可视化的交互式临时查询。化工具可以创建许多小的查询。用户数量的增加最终会增加-查询的数量及其并发性。这通常不需要更改内存配置,但只是增加了集群中的workers。另一方面,如果同一集群获得了添加的新数据源,复杂查询的大量数据很可能超出限制,您必须调整内存。这使我们到达了另一个值得一提的地方。
遵循最佳实践建议,在典型的Presto群集基础架构设置中,所有workers都是相同的。所有虚拟机均使用相同的虚拟机(VM)映像或容器大小硬件规格。因此,通常更改这些工作程序上的内存意味着新值对于物理可用内存而言太大,或者较小,以充分利用整个系统。因此,调整内存会产生需要替换集群中的所有工作节点。取决于您的集群基础架构使用例如私有云中的虚拟机或虚拟机中的容器的结构来自公共云提供商的Kubernetes集群,此过程可能或多或少费力且快速实施。这导致我们在这里值得一提的最后一点。
您对工作的评估-负载可以表明它们有很大的不同:许多查询都是小型,快速,临时的查询占用的内存很少,而其他查询则是耗时较长的流程在那里进行大量分析,甚至可能使用非常不同的数据源。这些工作负载差异表明内存配置非常不同,甚至非常不同不同的workers配置,甚至监控需求。在这种情况下,您确实应该采取下一步措施,并通过使用Presto集群。
Task Concurrency
为了提高Presto群集的性能,某些与任务相关的属性可能会需要从默认设置中进行调整。在本节中,我们讨论两个常见的您可能需要调整的属性。但是,您可以在Presto中找到其他几个文档。所有这些属性都在config.properties文件中设置:任务工作者线程默认值设置为计算机的CPU数量乘以2。例如,双十六进制核心计算机使用2×6×2,因此有24个工作线程。如果您会观察到所有线程都在使用中,并且机器仍然很低,您可以尝试提高CPU利用率,从而提高性能。通过task.max-worker-threads设置增加此数字。这建议缓慢增加此数字,因为将其设置得过高会增加由于增加了内存使用量而导致收益递减或不利影响,并且其他上下文切换。任务运算符并发联接等操作和聚合通过分区并行处理本地数据并并行执行运算符。例如,数据是在GROUP BY列上进行本地分区,然后进行多次聚合运算符是并行执行的。这些并行的默认并发操作的值为16。可以通过设置task.concurrency来调整此值。财产。如果您正在运行许多并发查询,则默认值可能是由于上下文切换的开销,导致性能降低。为了仅运行较少数量的并发查询的集群,较高的值可以帮助提高并行度,从而提高性能
Worker Scheduling
为了提高Presto群集的性能,某些与调度相关的属性可能需要从默认设置中进行调整。 您可以调整三个常见的外形:
• Splits per task
• Splits per node
• Local scheduling
在Presto文档中解释了其他几个。
Scheduling Splits per Task and per Node
每个辅助节点处理最大数量的拆分。 默认情况下,最大值每个辅助节点处理的拆分数为100。可以使用node-scheduler.max-splits-per-node属性。 您可能需要对此进行调整您会发现workers节点已经达到了这个价值,并且仍然没有得到充分利用。增加值可以提高性能,特别是当存在大量拆分时。 在此外,您可以考虑增加每个任务的node-scheduler.max-pending-splits-per-task属性。 该值不应超过每个节点的node-scheduler.max-splits--per-node。 它可以确保当workers完成正在处理的任务时,使workers排队。
Local Scheduling
在工作节点上调度splits时,Presto调度程序使用两种方法。使用的方法取决于Presto的部署。例如,如果workers运行在与分布式存储相同的计算机上,最好在数据所在的工作节点。在没有数据的地方进行调度ted要求将数据通过网络传输到工作节点以进行保护停止。因此,当您在存储数据的同一节点。计划时,默认方法传统不考虑数据位置分裂。改进的平面方法在计划时确实考虑了数据位置分割,可以通过设置node-scheduler.network-topology来使用。这Presto调度程序使用50%的队列来调度本地拆分。当安装Presto并使用并置在HDFS数据节点上或使用RubiX进行缓存时(请参阅“性能RubiX的改进”(第230页)。 RubiX从分布式缓存数据存储在工作节点上。因此,调度局部拆分是有利的。
Network Data Exchange
影响Presto群集性能的另一个重要因素是网络集群中的工作配置和设置以及与数据源的距离。Presto支持特定于网络的属性,可以将其从默认值调整为适应您的特定情况。除了提高性能外,有时还会出现其他与网络相关的问题需要调整才能使查询正常运行。 让我们讨论一些共同点您可能需要调整的属性。
Concurrency
Presto交换客户端向上游任务发出请求以生成数据。 这交换客户端使用的默认线程数为25。此值可以为adjusted通过设置属性exchange.client-threads来完成。设置更多数量的线程可以提高更大集群的性能,或者配置为高并发性的集群。 原因是当更多的数据得到支持时导致额外的并发消耗数据可以减少延迟。 保持在请注意,这些额外的线程会增加所需的内存量。
Buffer Sizes
交换期间发送和接收的数据保存在目标和源上的缓冲区中双方的交流。 每一侧的缓冲区大小可以独立调整。在源端,任务将数据写入等待等待请求的缓冲区来自下游交换客户端。 默认缓冲区大小为32 MB。 有可能通过设置sink.max-buffer-size属性进行调整。 增加价值可能增加更大集群的吞吐量。在目标端,数据在被下游处理之前被写入缓冲区任务。 默认缓冲区大小为32 MB。 可以通过设置属性来调整exchange.max-buffer-size。 设置更高的值可以提高查询性能通过在施加反压力之前允许通过网络检索更多数据。对于较大的集群尤其如此
Tuning Java Virtual Machine
在第2章中,您使用了配置文件etc / jvm.config,其中包含JVM的命令行选项。 Presto启动器在启动时会使用此文件运行Presto的JVM。 与前面提到的配置相比,适合生产使用的配置使用更高的内存值:
代码如下(示例):
-server
-XX:+UseG1GC
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+UseGCOverheadLimit
-XX:+HeapDumpOnOutOfMemoryError
-XX:-UseBiasedLocking
-Djdk.attach.allowAttachSelf=true
-Xms16G
-Xmx16G
-XX:G1HeapRegionSize=32M
-XX:ReservedCodeCacheSize=512M
-Djdk.nio.maxCachedBufferSize=2000000
通常,您需要增加JVM的最大内存分配池Xmx值,在这种情况下,最大为16 GB。 Xms参数设置初始名称,最小的内存分配。一般建议同时设置Xmx和Xms值相同在上述配置示例中,内存分配设置为16 GB。实际上您使用的值取决于群集使用的计算机。一般建议将Xmx和Xms都设置为系统总内存的80%。这为其他系统进程的运行留出了足够的空间。更多详细信息有关Presto的内存管理和相关配置的信息,请参见第254页的“内存管理”。对于大型Presto部署,不会分配200 GB及以上的内存罕见。尽管诸如监控之类的小流程可以与Presto在同一台计算机上运行,但是不建议与其他资源密集型软件共享系统。为了例如,Apache Spark和Presto不应在同一组硬件上运行。如果您怀疑Java垃圾回收(GC)问题,则可以设置其他参数帮助您调试:
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics=2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=1
在对整个GC暂停进行故障排除时,这些选项会很有帮助。 结合随着JVM的发展以及Presto查询引擎(GC)的工程技术暂停应该是非常罕见的事件。 如果确实发生,则应进行调查。 第一的解决这些问题的步骤通常是JVM版本和Presto 的升级使,因为两者都会定期获得性能改进
JVM和垃圾收集算法和配置是组合的复杂的话题。 可从Oracle获得有关GC调优的文档和其他JVM供应商。 我们强烈建议您调整这些在尝试更改测试环境中的较小设置之前将它们推广到生产系统。 还请记住,Presto当前需要Java11。旧的或新的JVM版本,以及来自不同供应商的JVM版本可能具有不同的行为。
Resource Groups
资源组是Presto中的一个强大概念,用于限制以下资源的利用率:系统。 资源组配置包括两个主要部分:资源组属性和选择器规则。资源组是定义可用集群的属性的命名集合。资源。 您可以将资源组视为群集中一个单独的部分,即与其他资源组隔离。 该组由CPU和内存限制定义它的并发限制,排队优先级以及选择排队的优先级权重查询运行。另一方面,选择器规则允许Presto分配传入的查询请求到特定的资源组。默认资源组管理器使用基于文件的配置,并且需要在etc / resource-groups.properties中配置
代码如下(示例):
resource-groups.configuration-manager=file
resource-groups.config-file=etc/resource-groups.json
如您所见,实际配置使用JSON文件。 文件内容定义资源组以及选择器规则。 请注意,JSON文件可以是Presto可访问的任何路径,并且需要配置资源组仅在协调员上执行:
{
"rootGroups": [],
"selectors": [],
"cpuQuotaPeriod": ""
}
cpuQuotaPeriod is optional.
Let’s look at the definition of two resource groups to get started:
"rootGroups": [
{
"name": "ddl",
"maxQueued": 100,
"hardConcurrencyLimit": 10,
"softMemoryLimit": "10%",
},
{
"name": "ad-hoc",
"maxQueued": 50,
"hardConcurrencyLimit": 1,
"softMemoryLimit": "100%",
}
]
该示例定义了两个名为ddl和ad-hoc的资源组。每个组都有一个设置并发查询的最大数量和分布式内存的总量限制。对于给定的组,如果满足并发或内存限制的限制,然后将任何新查询放入队列中。一旦总内存使用量下降或查询完成后,资源组从队列中选择一个查询以进行调度跑步。每个组还具有要排队的最大查询数。如果这个限制是到达后,所有新查询都会被拒绝,客户端会收到一条错误消息,指出这一点。在我们的示例中,临时组是为非DDL查询的所有查询设计的。该组仅允许一个查询同时运行,最多可以同时运行50个查询排队。该组的内存限制最高为100%,这意味着它可以使用所有可用内存来运行它。DDL查询具有自己的组,其思想是这些类型的查询是相对的简短而轻巧,不应被运行时间较长的临时SQL所饿死查询。在该组中,您指定不应超过10个DDL查询同时运行,以及所有查询使用的分布式内存总量运行的内存不应超过Presto群集内存的10%。这允许无需在临时查询行中等待即可执行DDL查询。现在已经定义了两个组,您需要定义选择器规则。当一个新查询到达协调器,并分配给特定的组。让我们来看例子:
"selectors": [
{
"queryType": "DATA_DEFINITION",
"group": "ddl"
},
{
"group": "ad-hoc"
}
]
第一个选择器匹配DATA_DEFINITION的任何查询类型,并将其分配给ddl资源组。 第二个选择器匹配所有其他查询并将这些查询放置ad-hoc资源组中的查询。
选择器的顺序很重要,因为它们是按顺序处理的,并且第一个匹配项将查询分配给该组。 为了匹配,所有属性指定必须匹配。 例如,如果我们切换选择器的顺序,则所有包括DDL在内的查询将分配给临时资源组。 没有查询曾经分配给ddl资源组.
Resource Group De€nition
让我们仔细看看资源组的以下配置属性:
- Name
资源组的必需名称,由选择器规则引用 - maxQueued
为该组排队的所需查询的最大数量。 - hardConcurrencyLimit
The required maximum number of concurrent queries that can be running in the
Group组中可以运行的所需的最大并发查询数 - softMemoryLimit
并发运行的查询可以使用的所需的最大分布式内存量。 达到此限制后,新查询将排队,直到内存减少。 绝对值(GB)和百分比(%)均可使用 - softCpuLimit
可选的软限制,可在由cpuQuotaPeriod属性定义的时间段。一旦达到此限制达到后,惩罚将应用于正在运行的查询。 - hardCpuLimit
可选的硬限制,可限制在以下时间内使用的CPU时间
由cpuQuotaPeriod属性定义的时间段。一旦达到此限制
到达后,查询将被拒绝,直到下一个配额期。 - schedulingPolicy调度策略
用于安排新查询的策略,以从队列中的队列中选择一个查询,资源组并对其进行处理。以下部分提供了详细信息。 - scheduleWeight
此可选属性将与schedulePolicy结合使用。 - jmxExport
标记以使资源组通过JMX公开。默认为false。 - subGroups
用于其他嵌套资源组的容器
Scheduling Policy
The schedulingPolicy value noted in the preceding list can be configured to various
values to be run in the following modes:
Fair
Setting schedulingPolicy to fair schedules queries in a first-in, first-out (FIFO)
queue. If the resource group has subgroups, the subgroups with queued queries
alternate.
Priority
Setting schedulingPolicy to query_priority schedules queued queries based
on a managed priority queue. The priority of the query is specified by the client
by using the query_priority session property (see “Session Information and
Configuration” on page 146). If the resource group has subgroups, the subgroups
must also specify query_priority.
Weighted
Setting schedulingPolicy to weighted_fair is used to choose the resource
group subgroup to start the next query. The schedulingWeight property is used
in conjunction with this: queries are chosen in proportion to the scheduling
Weight of the subgroups.
Selector Rules Definition
需要选择器规则来定义组属性,因为它确定了分配查询的资源组。 这是一个好习惯文件集中的选择器仅定义一个组。 然后,它充当显式的总体组。可选属性和正则表达式可用于优化选择器规则:
user
Matches against a username value. Regular expressions may be used to match
against multiple names.
source
Matches against the source value. For example, this may be presto-cli or
presto-jdbc. Regular expressions may be used.
queryType
Matches against the type of query. The available options are DATA_DEFINITION,
DELETE, DESCRIBE, EXPLAIN, INSERT, and SELECT.
clientTags
Matches against the client tags specified by the client submitting the query.
To set the source or client tags from the Presto CLI, you can use the --source and
--client-tags options:
$ presto --user mfuller --source mfuller-cli
$ presto --user mfuller --client-tags adhoc-queries
该处使用的url网络请求的数据。
总结
Well Done! 您在Presto方面走了很长一段路。 在本章中,您沉浸在您可以自己监视,调整和调整Presto。 当然有总是要学习更多,通常这些技能会随着实践而提高。 务必与其他用户交流以交流想法并从他们的经验中学习并加入Presto社区(请参阅第13页的“社区聊天”)。在第13章中,您将了解其他人已经使用Presto实现了什么。