python的文件操作
一、文件的基本操作
1.读文件read
f=open(filename,'r',encoding='utf-8')
data=f.read() # 读文件
f.close() # 关闭文件
# 1.绝对路径的易错点 文件路径中'\'前要加转义字符 或者 使用r使转义字符失效
f=open('c:\\windows\\users\\first.txt','r',encoding='utf-8')
f=open(r'c:\windows\users\first.txt','r',encoding='utf-8')
# 2.要确保路径存在,否则会报错 filenotfounderror 怎么判断路径是否存在
import os #导入操作系统判断路径是否存在
exists = os.path.exists('c:\\windows\\users\\first.txt') # exists是bool类型
2.写文件write
f=open(filename,'w',encoding='utf-8')
data=f.write() # 写文件
f.close() # 关闭文件
# 1.w模式的特点: 先清空文件,再写入文件
# 2.a模式的特点,在文件的末尾写入
3.文件的打开模式(要注意游标的位置,游标的位置会随着文件的读写进行移动)

# 1.移动光标位置
f.seek(n)
# 将游标位置重置为起始位置
f.seek(0)
# 2.获取光标位置
p=f.tell()
# 3.strip()默认是移除字符串首尾的空格或换行符 也可通过strip("需要移除的字符序列")将需要移除的字符序列移除
line.strip()
# 4.读文件的一些操作
# read()读所有
data=f.read()
# read(n) 读n个字符(r模式,一个中文字用3个字节表示)或n个字节(rb模式)
f.read(1)
# readline()读一行
str=f.readline()
# readlines() 按行读取,结果是列表类型,每行作为列表的一个元素
list_data=f.readlines()
# 循环读大文件
for line in f:
print(line.strip())
4.with上下文管理器
# 使用上下文管理器不需要再对文件进行关闭操作
with open(filename,'r',encoding='utf-8') as f:
pass
5.练习题
# 根据要求修改文件 将文件中的河南省替换为123
filename = "E:/file/2011年1月销售数据.txt"
with open(filename, 'r', encoding='utf-8') as readfile, open(r'update.txt', 'w', encoding='utf-8') as newfile:
for line in readfile:
new_line = line.replace("河南省", '123')
newfile.write(new_line)
# 重命名文件
import shutil
shutil.move("update.txt", "2011年1月销售数据.txt")
二、操作excel格式的文件
1.打开excel文件 新建excel文件
from openpyxl import workbook ,load_workbook
wb = workbook.Workbook() # 创建excel 且默认会创建一个Sheet
wb = load_workbook('E://file//11月11日名单.xlsx') # 打开excel
sheet相关操作
# 1.获取excel中所有sheet的名称
"""
print(wb.sheetnames) # ['Sheet1', 'Sheet2', 'Sheet3']
"""
# 2.选择sheet 基于名称 基于索引
"""
sheet = wb['Sheet1']
"""
"""
sheet = wb.worksheets[0]
value = sheet.cell(1, 1).value # 读第一行第一列
print(value)
"""
# 3.循环所有的sheet 基于名称 基于索引
"""
for name in wb.sheetnames:
sheet = wb[name]
cell= sheet.cell(1,1)
print(cell.value)
"""
"""
for sheet in wb.worksheets:
cell= sheet.cell(1, 1)
print(cell.value)
"""
"""
for sheet in wb:
cell = sheet.cell(1,1)
print(cell.value)
"""
2.读单元格内容
# 读单元格的内容,先获取shell
sheet = wb.worksheets[0]
# 1.读n行n列的单元格
"""
cell = sheet.cell(1, 1)
print(cell.value)
"""
# 2.获取某个单元格
"""
cell = sheet['A2']
print(cell.value)
cell = sheet['D4']
print(cell.value)
"""
# 3.读第n行所有单元格
"""
for cell in sheet[1]:
print(cell.value)
"""
# 4.输出所有行的数据
"""
for row in sheet.rows:
print(row[0].value,row[1].value) # 输出第一和第二列 也就是输出前两列的元素
"""
# 5.输出所有列的数据
"""
for col in sheet.columns:
print(col[0].value) #输出每列的第一个元素 也就是输出第一行的元素
"""
3.读合并单元格

from openpyxl import workbook ,load_workbook
wb =load_workbook('E://file//11月11日名单.xlsx') # 打开excel
print(wb.sheetnames) # ['Sheet1', 'Sheet2', 'Sheet3']
# 读合并单元格,单元格的类型
sheet=wb.worksheets[2]
for row in sheet.rows:
print(row[0],row[0].value)
'''
输出结果:
部门名称
研究生院
None
None
None
None
None
None
None
None
None
None
None
''' | |
4.写Excel操作
from openpyxl import load_workbook
wb=load_workbook('E://file//11月11日名单.xlsx')
sheet=wb.worksheets[2]
# 修改某一单元格的值 方法1
cell=sheet.cell(1,1)
cell.value='这里是新名字'
wb.save('E://file//1.xlsx')
# 修改某一单元格的值 方法2
sheet['A1']='开始'
wb.save('E://file//2.xlsx')
# 修改某些单元格的值
cell_list = sheet['C1':'D2']
i=0
for row in cell_list:
i=i+1
j=0
for cell in row:
cell.value=i+j
j=j+1
wb.save('E://file//3.xlsx')
最后修改某些单元格的值的效果:

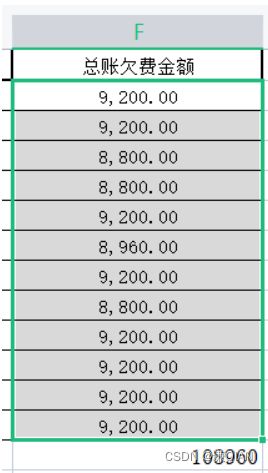
5.写入公式 SUM()
sheet['F14']='=SUM(F2:F13)'
wb.save('E://file//4.xlsx')
6.文件的绝对和相对路径
import os
# 获取当前文件的上级目录
base_dir=os.path.dirname(os.path.abspath(__file__))
# 路径拼接
file_path=os.path.join(base_dir,'dir1','filename')
补充:python项目打包
1.安装第三方软件 在线安装方式 pip install PyInstaller
2.执行打包操作 pyinstaller -F 22cqqCode\PycharmProjects\pythonProject\studentsys\stusystem.py
3.可执行文件保存到了C:\Users\86136\dist\路径下