算法的时间和空间复杂度
时间复杂度
一、究竟什么是时间复杂度
「时间复杂度是一个函数,它定性描述该算法的运行时间」。
我们在软件开发中,时间复杂度就是用来方便开发者估算出程序运行的答题时间。
那么该如何估计程序运行时间呢,通常会估算算法的操作单元数量来代表程序消耗的时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
假设算法的问题规模为n,那么操作单元数量便用函数f(n)来表示,随着数据规模n的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
二、大O符号表示法
算法导论给出的解释:「大O用来表示上界的」,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
同样算法导论给出了例子:拿插入排序来说,插入排序的时间复杂度我们都说是O(n^2) 。
输入数据的形式对程序运算时间是有很大影响的,在数据本来有序的情况下时间复杂度是O(n),但如果数据是逆序的话,插入排序的时间复杂度就是O(n2)**,也就对于所有输入情况来说,**最坏是O(n2) 的时间复杂度,所以称插入排序的时间复杂度为O(n^2)。
同样的同理再看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,「所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)」。
「但是我们依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界」。如图所示:

「面试中说道算法的时间复杂度是多少指的都是一般情况」。
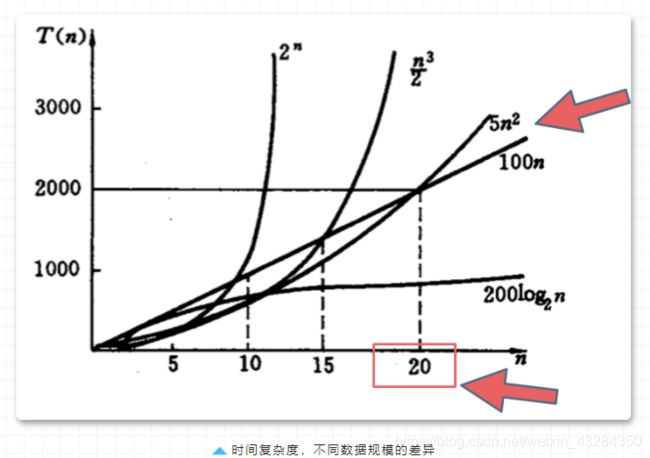
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小甚至可以用O(n^2)的算法比O(n)的更合适(在有常数项的时候)
常数阶O(1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是O(1),
int i = 1;
int j = 2;
++i;
j++;
int m = i + j;
线性阶O(n)
for(i=1; i<=n; ++i)
{
j = i;
j++;
}
for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度。
对数阶O(logN)
int i = 1;
while(i<n)
{
i = i * 2;
}
从上面代码可以看到,在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。我们试着求解一下,假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2^n
也就是说当循环 log2^n 次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(logn)
线性对数阶O(nlogN)
for(m=1; m<n; m++)
{
i = 1;
while(i<n)
{
i = i * 2;
}
}
线性对数阶O(nlogN) 其实非常容易理解,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)。
平方阶O(n²)
for(x=1; i<=n; x++)
{
for(i=1; i<=n; i++)
{
j = i;
j++;
}
}
平方阶O(n²) 就更容易理解了,如果把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²) 了。
这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(nn),即 O(n²)
如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O(mn)
「因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量」。
「所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示」:
O(1)常数阶 < O(logn)对数阶 < O(n)线性阶 < O(n^2)平方阶 < O(n^3)(立方阶) < O(2^n) (指数阶)
三、复杂表达式的化简
O(2*n^2 + 10*n + 1000)
1.去掉运行时间中的加法常数项 (因为常数项并不会因为n的增大而增加计算机的操作次数)。
2.去掉常数系数(上文中已经详细讲过为什么可以去掉常数项的原因)。
O(n^2 + n)
只保留保留最高项,去掉数量级小一级的n (因为n^2 的数据规模远3.大于n)
O(n^2)
所以最后我们说:这个算法的算法时间复杂度是O(n^2)
四、O(logn)中的log是以什么为底?

「我们统一说 logn,也就是忽略底数的描述」。
五、 举一个例子
题目描述:
找出n个字符串中相同的两个字符串(假设这里只有两个相同的字符)
如果是暴力枚举的话,时间复杂度是多少呢,是O(n^2)么?
这里一些同学会忽略了字符串比较的时间消耗,这里并不像int 型数字做比较那么简单,除了n^2 次的遍历次数外,字符串比较依然要消耗m次操作(m也就是字母串的长度),所以时间复杂度是O(m * n * n)。
先排对n个字符串按字典序来排序,排序后n个字符串就是有序的,意味着两个相同的字符串就是挨在一起,然后在遍历一遍n个字符串,这样就找到两个相同的字符串了。
那看看这种算法的时间复杂度,快速排序时间复杂度为O(nlogn),依然要考虑字符串的长度是m,那么快速排序每次的比较都要有m次的字符比较的操作,就是O(m * n * logn) 。
之后还要遍历一遍这n个字符串找出两个相同的字符串,别忘了遍历的时候依然要比较字符串,所以总共的时间复杂度是 O(m * n * logn + n * m)。
我们对O(m * n * logn + n * m) 进行简化操作,把m * n提取出来变成 O(m * n * (logn + 1)),再省略常数项最后的时间复杂度是 O(m * n * logn)。
最后很明显O(m * n * logn) 要优于O(m * n * n)!
空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的一个量度,同样反映的是一个趋势,我们用 S(n) 来定义。
空间复杂度 O(1)
如果算法执行所需要的临时空间不随着某个变量n的大小而变化,即此算法空间复杂度为一个常量,可表示为 O(1)
int i = 1;
int j = 2;
++i;
j++;
int m = i + j;
代码中的 i、j、m 所分配的空间都不随着处理数据量变化,因此它的空间复杂度 S(n) = O(1)
空间复杂度 O(n)
int[] m = new int[n]
for(i=1; i<=n; ++i)
{
j = i;
j++;
}
这段代码中,第一行new了一个数组出来,这个数据占用的大小为n,这段代码的2-6行,虽然有循环,但没有再分配新的空间,因此,这段代码的空间复杂度主要看第一行即可,即 S(n) = O(n)
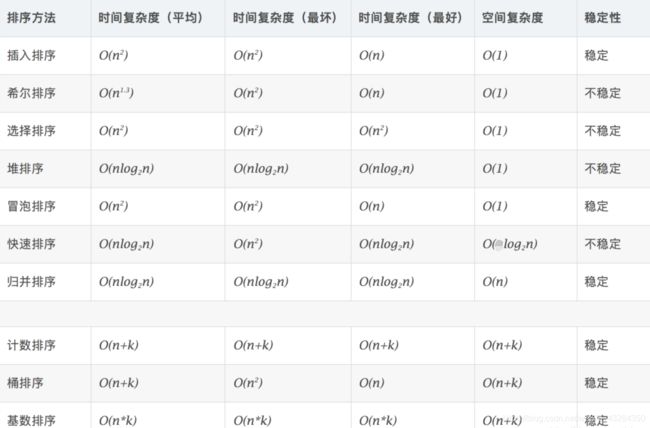
附各排序算法复杂度及稳定性: