CUDA C++ Programming Guide(Version 10.0) —— 2. Programming Model
CUDA编程 - Programming Model
-
- Kernels
- Thread Hierarchy(线程层次结构)
- Memory Hierarchy(内存层次结构)
- Heterogeneous Programming (异构编程)
- Compute Capability
GPU 常用于并行计算,可拥有大量线程数,下面主要是对线程的一些描述。
Kernels
CUDA C extends C by allowing the programmer to define C functions, called kernels, that when called, are executed N times in parallel by N different CUDA threads, asopposed to only once like regular C functions.
kernels 即CUDA每个线程执行内容对应的C函数。
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
核函数使用__global__进行指示, 而函数调用的执行配置则使用<<<...>>>来指定线程数。核函数中的threadIdx为内置变量,提供线程的索引信息。
Thread Hierarchy(线程层次结构)
上面的例子只是一维的向量的操作,对于线程其实还可以为多维的,其索引方式跟数组的索引方式可以说是对应的。下面是一个二维的例子,threaDIdx负责存储线程的层次信息。
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
Memory Hierarchy(内存层次结构)
CUDA线程使用的内存分层次的,其具体的内存分配如下:
threadIdx:是一个uint3类型,表示一个线程的索引。
blockIdx:是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim:是一个dim3类型,表示线程块的大小。
gridDim:是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
对应的维度的描述,1D或2D的线程可描述为Blocks, 多个Blocks则称之为Grid, 下图可描述该模型

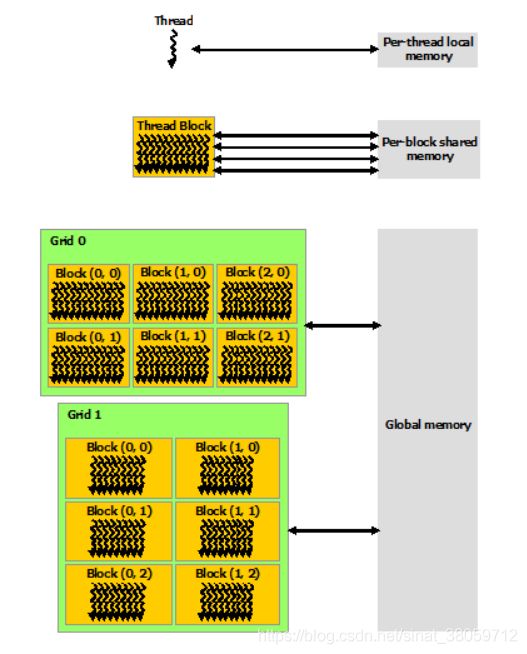
除上图,还有两种全局只读内存:constant and texture memory
cuda 通过<<< >>>符号来分配索引线程的方式,常用有15种索引方式。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include >>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 5; s.y = 5; s.z = 1;
//testBlock2<<>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testBlock3<<>>(dev_c, dev_a, dev_b);
//testBlockThread1<<>>(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;
//testBlockThread2 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;
//testBlockThread3 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread4 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread5 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;
//testBlockThread6 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;
//testBlockThread7 << > >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;
//testBlockThread8 <<>>(dev_c, dev_a, dev_b);
uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
uint3 s2; s2.x = size / 200; s2.y = 5; s2.z = 2;
testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b);
cudaMemcpy(c, dev_c, size*sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
cudaGetLastError();
}
int main()
{
const int n = 1000;
int *a = new int[n];
int *b = new int[n];
int *c = new int[n];
int *cc = new int[n];
for (int i = 0; i < n; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
c[i] = b[i] - a[i];
}
addWithCuda(cc, a, b, n);
FILE *fp = fopen("out.txt", "w");
for (int i = 0; i < n; i++)
fprintf(fp, "%d %d\n", c[i], cc[i]);
fclose(fp);
bool flag = true;
for (int i = 0; i < n; i++)
{
if (c[i] != cc[i])
{
flag = false;
break;
}
}
if (flag == false)
printf("no pass");
else
printf("pass");
cudaDeviceReset();
delete[] a;
delete[] b;
delete[] c;
delete[] cc;
getchar();
return 0;
}
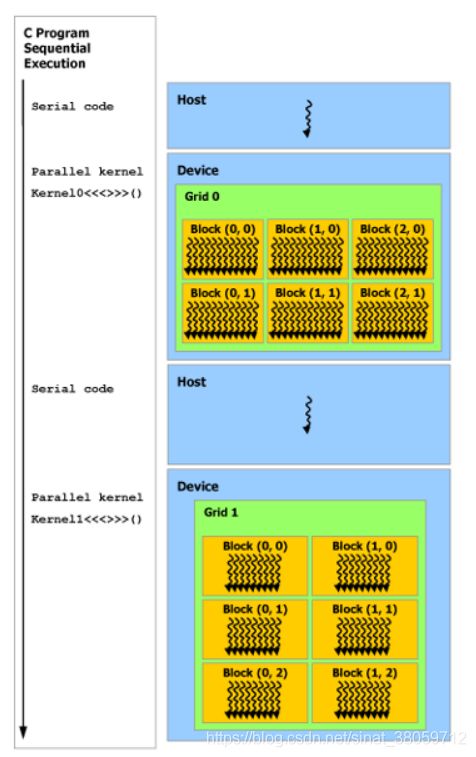
Heterogeneous Programming (异构编程)
The CUDA programming model also assumes that both the host and the device maintain their own separate memory spaces in DRAM, referred to as host memory and device memory, respectively. Therefore, a program manages the global, constant, and texture memory spaces visible to kernels through calls to the CUDA runtime. This includes device memory allocation and deallocation as well as data transfer between host and device memory.
Compute Capability
设备的计算能力由版本号表示,有时也称为"SM version"。 此版本号标识GPU硬件支持的功能,并由应用程序在运行时用于确定当前GPU上可用的硬件功能和/或指令。
计算能力包括 major revision 主要修订号X 和 minor revision 次要修订号Y,并由X.Y表示。
主要修订号X:
- The major revision number is 7 for devices based on the Volta architecture
- The major revision number is 6 for devices based on the Pascal architecture
- The major revision number is 5 for devices based on the Maxwell architecture
- The major revision number is 3 for devices based on the Kepler architecture
- The major revision number is 2 for devices based on the Fermi architecture
- The major revision number is 1 for devices based on the Tesla architecture
次要修订号Y:对应于核心体系结构的增量改进,如新功能等。