JDK1.7与JDK1.8中HashMap的扩容
基础知识

注意
- Java中散列表用链表数组实现,每个链表被称为桶,想要查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余数,所得到的结果就是保存这个元素桶的索引。
- hash:翻译为”散列表“,就是把任意长度的输入,通过散列算法,变成固定长度输出,该输出结果是散列值。这种转换是一种压缩映射,散列表的空间通常小于输入的空间,不同的输入可能会散列成相同的输出,所以不能从散列表来唯一的确定输入值。
- hash冲突:就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经有人先来了。就是说这个地方要挤一挤啦。这就是所谓的hash冲突啦。
- 散列冲突:Java8中,桶满时会丛链表变为平衡二叉树(红黑树)。如果选择的散列函数不当,会产生很多的冲突,或者如果有恶意的代码试图在散列表中填充多个有相同散列码的值。转变成红黑树就能够提高性能。
- 加载因子(装填因子):决定何时对散列表进行在散列。例如默认为0.75,则表中超过75%的位置已经填入元素,这个表就会用双倍的桶数(bucket)自动的进行在散列。
- 拉链法:将链表与数组结合。也就是说创建一个链表数组,数组中每一格就是一个数组。若遇到哈希冲突,则将冲突的值加到链表中就可以了。
- 桶的个数就是数组的长度,默认为16。
为什么加载因子等于0.75?
作为一般规则,默认负载系数(0.75)提供了时间和空间成本之间的良好权衡。较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put)。在设置映射的初始容量时,应该考虑映射中预期的条目数量及其负载因子,以减少重新散列操作的数量。如果初始容量大于最大条目数除以负载因子,则不会发生重新散列操作。
HashMap的底层原理
HashMap是存储的是Key-Value键值,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,数组初始化长度为16,数组中的每一个元素初始值都是null,这个数组就是我们常说的桶或坑位。
JDK1.8之前:数组+链表
HashMap是线程不安全的,不安全的具体原因就是在高并发场景下,扩容可能产生死锁(Jdk1.7存在)以及get操作可能带来的数据丢失。
线程不安全的主要原因:
多线程扩容(resize方法)导致形成的链表环( transfer方法将所有表项从当前表转移到newTable使链表成环造成线程不安全问题)!
看源码先看一下重要的几个成员变量:
- DEFAULT_INITIAL_CAPACITY = 1 << 4; Hash表默认初始容量
- MAXIMUM_CAPACITY = 1 << 30; 最大Hash表容量
- DEFAULT_LOAD_FACTOR = 0.75f;默认加载因子
- TREEIFY_THRESHOLD = 8;链表转红黑树阈值
- UNTREEIFY_THRESHOLD = 6;红黑树转链表阈值
- MIN_TREEIFY_CAPACITY = 64;链表转红黑树时hash表最小容量阈值,达不到优先扩容。
put方法原理:
当调用HashMap.put(“qijian”,0),插入一个key为"qijian"的元素。Entry(key-value)插入的位置(index,table下标)由hash函数来决定。index = Hash(“qijian”)
当发生hash冲突时,当我们插入一个Entry的时候发现数组的对应下标中已经存在元素(链表的头节点)。此时新来的Entry节点插入链表,使用头插法插入。next一次指向下一个元素。使用头插法的原因:设计者认为后插入的元素被get的几率更大。
get方法原理:
首先对key做一次hash映射,得到index ( index = Hash(“qijian”) ) , 此时使用的hash需要与put时的hash函数是一样的。这时候只需要顺着对应链表的头节点,一个一个向下来查找,查找到key为qijian的Entry就是我们要查找的Entry。
扩容方法:
//将此映射的内容重新散列到一个容量更大的新数组中。当此映射中的键数达到其阈值时,将自动调用此方法。如果当前容量为MAXIMUM_CAPACITY,此方法不会调整map的大小,但将threshold设置为Integer.MAX_VALUE。这有防止未来调用的效果
//参数:newCapacity—新容量,必须是2的幂;必须大于当前容量,除非当前容量是MAXIMUM_CAPACITY(在这种情况下值无关)。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer方法源码:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
//当部位空时
while(null != e) {
//记录当前hash表的e.next
Entry<K,V> next = e.next;
if (rehash) {
//rehash计算出数组的位置(hash表中桶的位置)
e.hash = null == e.key ? 0 : hash(e.key);
}
//Returns index for hash code e.hash
int i = indexFor(e.hash, newCapacity);
//将e.nehfxt指向new hash表中的第一个元素
e.next = newTable[i];
//将e放入到new hash表的头部
newTable[i] = e;
//转移e到下一个节点, 继续循环下去
e = next;
}
}
}
单线程扩容
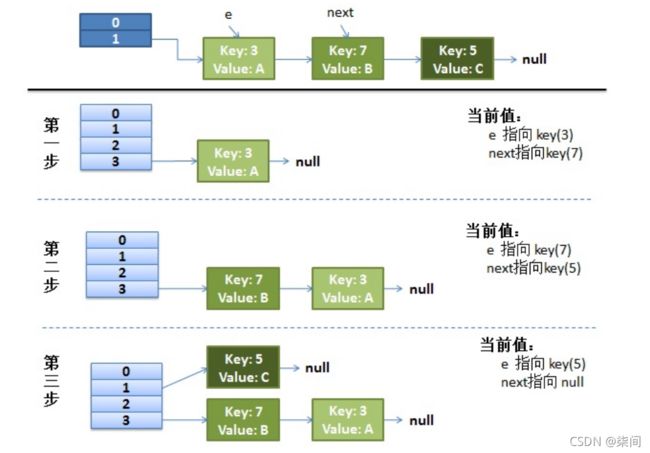
假设:hash算法就是简单的key与length(数组长度)求余。hash表数组长度为2,如果不扩容, 那么元素key为3,5,7按照计算(key%table.length)的话都应该碰撞到table[1]上。
扩容:hash表数组长度会扩容为4重新hash,key=3 会落到table[3]上(3%4=3), 当前e.next为key(7), 继续while循环重新hash,key=7 会落到table[3]上(7%4=3), 产生碰撞,这里采用的是头插入法,所以key=7的Entry会排在key=3前面(这里可以具体看while语句中代码)当前e.next为key(5), 继续while循环重新hash,key=5 会落到table[1]上(5%4=3), 当前e.next为null, 跳出while循环,resize结束。
多线程的扩容
假设有两个线程正在进行扩容,且同时进入了transfer()方法。
while(null != e) {
Entry<K,V> next = e.next;//当第一个线程执行到此时被挂起
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
下面我们通过走读源码分析一下为什么多线程下HashMap是线程不安全的。
HashMap线程不安全主要体现在扩容多线程的扩容。这里详细分析一下。其主要分为两步:
1,扩容:创建一个新的Entry空数组,长度是原来数组的2倍。
2,Rehash:遍历数组,把所有的Entry重新Hash到新的数组。Hash公式:index = hashCode(key) & (Length - 1);
假设HashMap的负载因子为0.75f,且HashMap已经到了Resize()的临界点,数组长度为4,这时有两个线程对HashMap进行put操作:
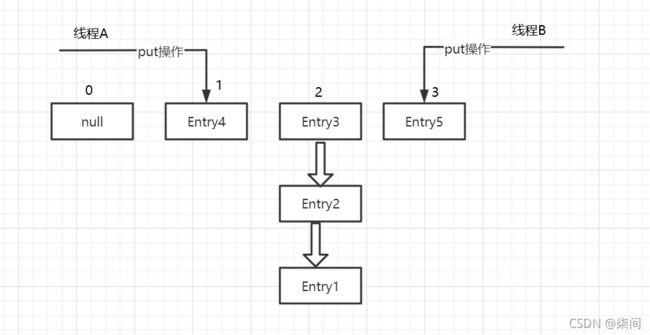
此时,发现空间利用率达到了0.75,此时HashMap将进行扩容。
线程B执行到Entry时被挂起,此时对于线程B来说:e = Entry3 ,next = Entry2。这时候线程A也在进行着Rehash,完成后如下:
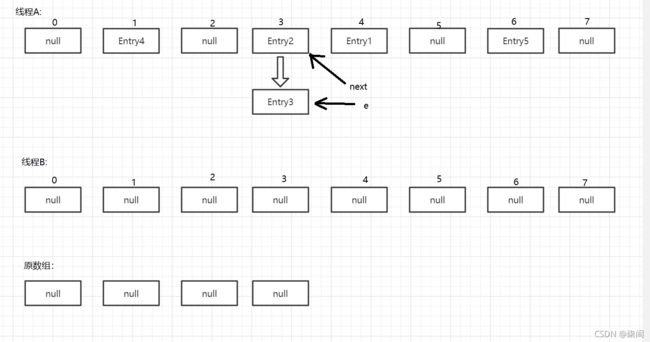
接下来,线程B恢复继续没有完成的操作,newTable[i] = e; e = next;
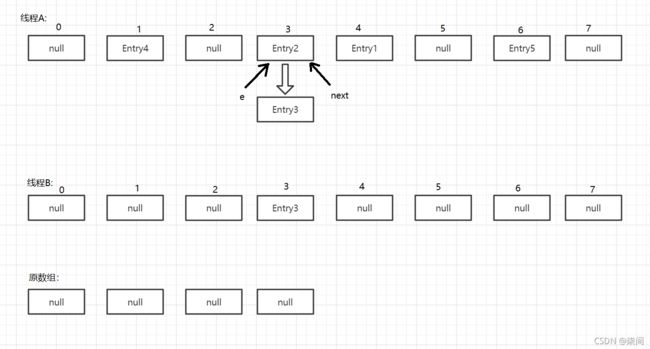
紧接着,进行下一轮的while循环,又执行到Entry 这时e = Entry2; next = Entry3 ,如下:

接下来继续执行,利用头插法把Entry2插入到线程B数组的头节点,代码如下:
e.next = newTable[i];
newTable[i] = e;
e = next;
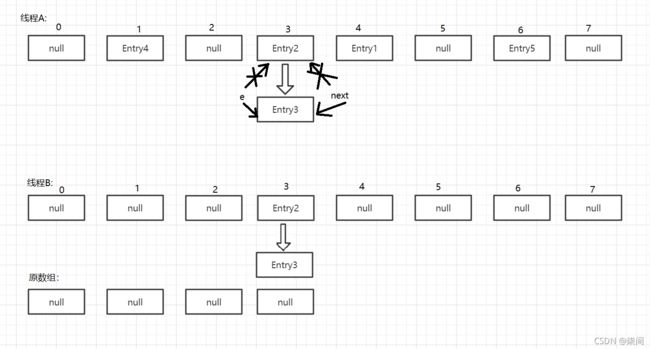
此时,e = Entry3;next = Entry3.
接下来,第三次循环开始,再次执行到Entry ,此时:
e = Entry3 ; next = Entry3.next = null;
继续执行, e.next = newTable[i]; 此时指向如下:
newTable[i] = Entry2; e = Entry3;
Entry2.next = Entry3 ; Entry3.next = Entry2;
很明显这里已经成环。此时。当调用Get查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!
JDK1.8: 数组+链表/红黑树
当链表长度大于阈值(默认为8)并且容量大于64时,将链表转化为红黑树,以减少搜索时间(空间换时间)。同时采用尾插法来解决扩容操作下的循环死链问题。 如果阈值大于8,但是容量小于等于64时,优先选择扩容。
红黑树就是为了解决二叉查找树的缺陷,二叉查找树在某些情况下会退化成一个线性结构。
在 JDK 1.8 中对 HashMap 进行了优化,在发生 hash 碰撞,不再采用头插法方式,而是直接插入链表尾部,因此不会出现环形链表的情况,但是在多线程的情况下仍然不安全
引入了新的数据结构,同时对put方法做了修改。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v0k0VXnu-1635672200016)(HashMap.assets/image-20211030234054834.png)]
JDK 1.8 链表为啥改为尾部插入呢?
和 HashMap 的扩容机制有关。数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是 resize。进行扩容时需要将扩容前的元素重新 hash 到新的数组中。
单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,旧数组中同一链表中元素可能被放到了新数组的不同位置上,一旦多线程并发调整完成,就可能出现环形链表。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
参考:https://my.oschina.net/muziH/blog/1596801