ICCV 2023 | Actformer:从单人到多人,迈向更加通用的3D人体动作生成
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
以下内容来源于东方理工科技之声
近日,宁波东方理工大学(暂名)联合上海交通大学、商汤科技、香港理工大学以及上海人工智能实验室的一篇关于3D人体动作生成的研究工作被计算机视觉顶级会议ICCV 2023录用,论文、代码、数据均开源。

ActFormer: A GAN-based Transformer towards General Action-Conditioned 3D Human Motion Generation
主页:https://liangxuy.github.io/actformer/
论文:https://arxiv.org/abs/2203.07706
代码:https://github.com/Szy-Young/actformer
本文的主要贡献为:
提出了基于 GAN 和 Transformer混合架构的通用 3D 人体动作生成框架;
不仅能够实现单人动作生成,还能拓展到多人交互式动作生成;
基于GTA游戏引擎构造了一个合成的多人打架数据集,包括2~5个人同时交互,现已开源。

图1. Actformer支持多种类型的人体动作表征,支持单人/多人动作生成
1. 简介
3D人体动作生成是计算机视觉和图形学中的经典问题,近期通过文本描述生成人体动作的研究方向(text-to-motion)更是吸引了大量关注,其对于游戏、AR/VR、人机交互、具身智能等实际应用有重要的现实意义。本研究旨在探索给定动作类别标签,生成高质量的、多样化的3D人体动作序列。
我们发现,现有的相关工作在以下几个方面存在一定局限性:
大多工作局限于人体SMPL[5]参数模型表征的3D人体动作,而对于骨架坐标表征泛化性能差;
大多工作关注单人动作生成,而忽略了多人交互动作的生成;
因此,我们希望设计一种更加通用的、能够支持多种类型的人体动作表征的、支持单人/多人动作生成的3D人体动作生成框架。
2. 具体方法
如下图所示,给定一个动作类别语义标签,以及从隐式高斯过程先验中采样的,Actformer能够生成一段3D人体动作序列,每一帧包含个个体,即,其中人的动作包括全局的根节点位移和局部的人体位姿变化,即人的全局运动轨迹和局部关节运动,对于局部关节运动,我们支持骨架坐标或者SMPL参数模型表示。

图2. Actformer框架图
2.1. 单人动作生成
时序连贯性对3D动作生成任务至关重要,因此我们采用高斯过程作为隐式先验,并随机采样一个维度为()的向量作为,其中为待生成的动作序列长度,为通道维度。
Actformer构造了一个基于Transformer结构的生成网络来将隐式向量和给定的动作类别标签转化成人体动作序列。具体来说,隐式向量被看成包含个tokens的列表,通过一个全连接层将其映射到表征空间,随后与动作类别标签的表征合并为长度为的最终表征。在输入多层时序Transformer之前,我们加上了可学习的位置编码。利用Transformer对于动作数据的时序建模,输出的结果通过一层全连接层,恢复出3D人体动作序列。
2.2. 多人动作生成
从单人拓展到多人动作生成需要额外的人数维度,我们可以通过小幅度调整网络框架进行拓展。首先,考虑到在同一时刻,多个人的动作是高度相关且同步的,因此我们将其作为一个整体,多个人共享同一个采样的隐式表征,实验证明这样能够生成更加同步的交互结果。
生成器网络方面,我们设计了交互Transformer结构(I-Former)来建模不同人体之间的交互,以及时序Transformer结构(T-Former)来建模同一个人动作的时序变化,我们通过交替式地建模交互和时序来处理多人动作的建模。多人条件下,可学习的位置编码拓展为时间维度和人数维度的拼接。和单人生成一样,我们通过一层全连接层恢复出多人的3D人体动作序列。
2.3. 生成对抗训练
Actformer是条件生成对抗网络框架,训练时,给定动作类别标签后,生成器合成3D人体动作序列,判别器以动作序列为输入,试图区分真实和合成动作序列,而生成器通过判别器的反馈提升生成质量。实验中,我们通过条件Wasserstein GAN损失函数来训练网络,并采用ST-GCN[4]的网络框架作为判别器。
由于多人的动作特征通过在特征通道维度拼接操作进行融合,然而拼接操作不具备排列不变性质,即
3. GTA Combat数据集
为了弥补目前多人交互,尤其是超过2个人的复杂交互数据集的缺乏,我们基于GTA-V游戏引擎合成了一个多人打架数据集,每个打架序列包含2~5个参与者,具有交互真实感、丰富的随机性。在GTA-V游戏引擎中,通过随机触发超过10种原子的打架模式,以及组合不同的人物、场景、被打者的随机反应,保证了合成数据集的多样性;同时,GTA-V的物体模型保证了合成数据集的物理真实性。对于2/3/4/5个人的打架行为,我们分别合成了大约2.3/1.9/1.5/1.2K数量的动作序列。数据将开源用作学术使用。

图3. GTA Combat数据集概况
4. 实验
我们在NTU-13、NTU RGB+D 120、BABEL以及本文提出的GTA Combat数据集上进行了大量实验,来证明算法的有效性和泛化性。评测方面,我们采用了动作识别准确率和FID分数作为量化指标,利用训练好的ST-GCN网络进行动作识别准确率的评测以及FID评测的特征提取,值得注意的是,与之前的工作不同的是,我们的ST-GCN网络考虑了人的全局位移,这是因为位移变化对多人交互的真实性更加重要。
4.1. 量化结果
我们和Action2Motion[1]、ACTOR[2]和CSGN[3]等方法在单人和多人动作生成任务上进行了对比。从表1可得,我们的算法在所有数据集上均取得了最好的效果。

表1. 单人动作生成结果对比
对于多人动作生成实验,我们将Action2Motion[1]、ACTOR[2]和CSGN[3]方法拓展到多人场景,从表2可得,我们的算法均取得了最好的效果。

表2. 多人动作生成结果对比。左侧:NTU-2P,右侧:GTA Combat数据集
4.2. 消融实验
我们在不同网络模块设计上进行了大量消融实验。表3展示了高斯过程隐式先验(1)、Transformer生成网络(2)、可学习的位置编码(3)的有效性。
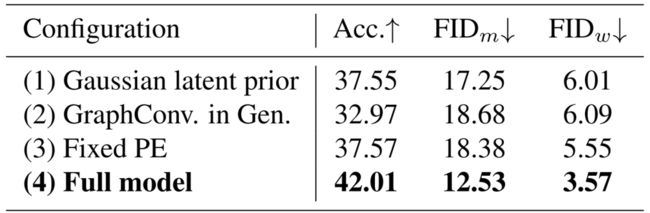
表3. NTU-1P上的网络模块消融实验
表4展示了判别器的特征融合选择(5-7)、可学习的位置编码(8)、时间维度和人数维度的拼接(9)的有效性。

表4. NTU-2P上的网络模块消融实验
表5展示了多人交互生成中多人共享采样的隐式表征(1)以及I-Former模块(2)的有效性。

表5. 多人交互编码消融实验
4.3. 可视化结果
如下图4所示,Actformer能够生成高质量的、多样化的3D人体动作序列,支持骨架坐标或者SMPL参数模型,同时支持多人交互的生成。更多的可视化结果以及视频效果可以参见项目主页。

图4. 可视化结果
5. 结论
本文旨在面向更加通用的3D人体动作生成,并提出了基于GAN和Transformer的生成网络框架,支持多种人体动作表征以及单人/多人动作生成,我们提出的GTA Combat数据集也结论的第一段“我们提出的GTA Combat数据集也弥补了当前复杂场景交互数据集不足的现状。
希望大家更多地关注3D人体动作生成领域,并持续关注我们关于人体动作/交互的理解与生成的后续工作,也欢迎对该领域感兴趣的同学加入我们!
参考
1.Guo, Chuan, et al. "Action2motion: Conditioned generation of 3d human motions." Proceedings of the 28th ACM International Conference on Multimedia. 2020.
2.Petrovich, Mathis, Michael J. Black, and Gül Varol. "Action-conditioned 3D human motion synthesis with transformer VAE." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
3.Yan, Sijie, et al. "Convolutional sequence generation for skeleton-based action synthesis." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
4.Yan, Sijie, Yuanjun Xiong, and Dahua Lin. "Spatial temporal graph convolutional networks for skeleton-based action recognition." Proceedings of the AAAI conference on artificial intelligence. Vol. 32. No. 1. 2018.
5.Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." ACM transactions on graphics (TOG) 34.6 (2015): 1-16.
提醒
点击“阅读原文”跳转到00:09:52
可以查看回放哦!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 观看回放!