UPHDR-GAN: Generative Adversarial Network forHigh Dynamic Range Imaging with Unpaired Data
Abstract
本文提出了一种利用未配对数据集有效融合多次曝光输入并生成高质量高动态范围(HDR)图像的方法。基于深度学习的HDR图像生成方法严重依赖于成对的数据集。地面真像对生成合理的HDR图像起着主导作用。没有地面真相的数据集很难用于训练深度神经网络。最近,生成对抗网络(Generative Adversarial Networks, GAN)已经证明了在缺少成对例子的情况下,其将图像从源域X转换到目标域Y的潜力。在本文中,我们提出了一个基于gan的网络来解决这些问题,同时生成令人愉快的HDR结果,名为UPHDR-GAN。该方法放松了配对数据集的约束,学习了从LDR域到HDR域的映射。尽管对数据缺失,UPHDR-GAN在改进GAN损耗、改进的鉴别器网络和有用的初始化阶段的帮助下,仍然可以适当地处理由移动物体或不对中引起的重影伪影。该方法保留了重要区域的细节,提高了图像的整体感知质量。与代表性方法的定性和定量比较证明了所提出的UPHDR-GAN方法的优越性。
I. INTRODUCTION
商业成像产品的动态范围低于自然场景。大多数数字摄影传感器无法获得足够宽的辐照度范围。高动态范围(HDR)成像技术能够克服这些限制,生成更大动态范围的图像,因此得到了广泛的应用。已经引入了专用的硬件设备[1]来直接获取HDR映像,但它通常过于昂贵而不能被广泛采用。一个可选的策略是合并具有不同曝光的图像堆栈,以产生信息输出[2]。
HDR成像技术自20世纪90年代首次推出以来,发展迅速,其应用包括显著性检测[9]和视频压缩[10]。首先提出了几种HDR成像方法,通过两个步骤生成结果:(1)重建HDR图像;(2)应用音调映射算法显示[11]。由于这些方法没有考虑不同输入图像之间的误差,因此不适合处理动态场景。随后,Oh等人提出了一种秩最小化算法,用于检测HDR生成的离群值,对齐输入图像[12]。Szpak等人引入了Sampson距离来估计单应性矩阵,并利用单应性对输入图像[13]进行对齐。当输入正确对齐时,这些方法工作得很好。然而,完全对齐多次曝光的图像是一个挑战。如果对齐过程失败,上述方法可能会产生重影或模糊工件。为了解决这个问题,提出了一些基于patch的方法来生成完全注册的图像堆栈。Sen等人认为HDR重建是一种优化,包括对齐和重建[4]。Hu等人使用PatchMatch的一种变体构建了新的图像堆栈,以处理饱和区域并避免重影伪影[3]。然而,基于patch的方法缺乏鲁棒性,不能对复杂场景产生满意的效果。
受卷积神经网络(CNN)的启发,引入了一些基于学习的方法来模拟融合进程。Kalantari et al.[5]和Wu et al.[6]采用了相似的网络结构,但在预处理方面有所不同。Kalantari等人[5]应用基于流的预处理对输入进行对齐,而Wu等人[6]将对齐过程嵌入到网络中。Yan et al.[14]和Liu et al.[15]提出了注意引导网络,该网络可以同时处理偏位和饱和。但由于图像配准的不可靠性,这些方法也存在不可避免的伪影。也有一些基于gan的方法,通过引入对抗损失来创建真实信息[8]来改善不理想区域。通过引入不同的技术来提高融合性能。然而,基于深度学习的融合方法最重要的问题是它们严重依赖于配对输入和地面事实。
为了放松数据集的约束,我们提出了一种基于gan的融合方法,利用未配对数据集对网络进行优化。首先,与著名的单图像增强方法[16]-[19]以及近年来在成对数据集上训练的基于gan的图像融合方法[8]、[20]、[21]相比,本文提出的方法对成对数据集进行训练,并将多次曝光的LDR域图像转换为HDR域图像。常用的基于深度学习方法的数据集需要输入和地面真实图像。然而,HDR地面真实图像的获取非常困难,现有的数据集大多只包含输入图像。最近的一些数据集[5]根据输入生成地面真实图像,但其场景的多样性非常有限。在非配对数据集上训练模型可以放松配对训练的约束,扩大数据集的应用范围。其次,我们的方法是一种考虑移动对象的多输入方法,而不像一些针对非配对数据集设计的方法主要集中于处理单输入。例如,CycleGAN[22]设计用于训练未配对的数据集和处理单个输入。CycleGAN不适合融合多次曝光输入,因为前向过程(将多次曝光的图像合成为HDR输出)可能会被正确学习,而后向过程(将HDR图像分解为多次曝光的图像)可能不会成功收敛。在CycleGAN中,正向过程和反向过程是相互作用的。因此,如果逆向过程不能令人满意地工作,则会影响正向过程。即使考虑多输入,简单地串联多个曝光输入也会导致严重的重影。
相比之下,UPHDR-GAN设计了特定的模块来解决这些问题,并产生信息丰富的HDR输出,同时减少重影工件。首先,我们引入初始化阶段来维护引用和输出之间的内容信息。初始化阶段只是将参考图像转移到HDR域,完全避免了重影现象的发生。其次,我们改进了常见的对抗性损失,生成边缘尖锐的图像(图2 (b))。第三,融合曝光不足和过曝光图像信息时,采用小补丁训练模块(图2 (c))对重影伪影进行检测和处理。几种去重影方法的比较结果如图1所示。比较方法有不同的工件,而UPHDR-GAN在HDR转换和内容保存之间保持平衡,适当地处理动态对象。
总之,主要的贡献包括:
•提出了一种基于gan的多曝光HDR融合网络,该网络放松了成对训练数据集的约束,学习了输入域和目标域之间的映射关系。据我们所知,这项工作是第一个基于gan的方法用于未配对HDR重建。
•所提出的方法不仅可以在未配对数据集上进行训练,而且生成HDR结果的重影伪影较少。我们采用改进的GAN损耗、初始化阶段和小补丁训练模块来避免重影,提高图像质量。
•我们对几种主要方法进行了全面比较。结果表明,所提出的UPHDR-GAN方法优于现有方法,并且在具有挑战性的情况下工作良好。
II. RELATED WORKS
A. HDR Imaging
HDR成像在过去的几十年里得到了广泛的研究。现有的HDR成像方法主要分为静态场景和动态场景两大类。
a)静态场景方法:Debevec等人首先提出将不同曝光图像融合为HDR图像[23]。最初的方法产生了壮观的静态相机和静态场景的结果。然后通过生成视差图或使用神经网络[24],[25]引入一些变体。Sun等人首先计算视差图,然后应用它们来计算相机响应函数[25]。Hashimoto等人通过一种新的色调再现算法[24]开发了难以查看或不可查看的彩色图像特征和内容。也有许多静态融合方法不生成HDR输出,而是直接获得信息丰富的LDR结果[26]-[29]。Li等人在融合方法中加入边缘保持因子,以保持细节[28]。Wang et al.[29]提出了一种统一的多尺度密集连接的融合网络,用于融合红外和可见光图像。但是,由于缺乏对动态对象的显式检测,上述方法无法感知场景中的任何运动,因此仅适用于静态场景。
b)动态场景方法:为了解决静态方法不适用于多个场景的问题,引入了很多去重影算法[30],[31]。一些方法计算输入图像的权值映射,同时消除移动内容[32],[33]。另外,一些方法首先对图像进行合并,然后对结果[34]进行重影处理。这种方法常常会出现像素不对齐的情况,从而不能充分利用现有的内容生成HDR图像。也有一些方法是应用能量优化来保持图像的一致性或模型的噪声分布的颜色值[35]。此外,还提出了基于光流[2]或基于patch的对应[3]、[4]等更复杂的方法来实现更精确的图像配准。Li等人利用光流对手持相机拍摄的多曝光图像进行粗略对齐,然后利用基于patch的优化获得全对齐输入[2]。
B. GAN-based Fusion
GAN由Goodfellow等人提出。[36],它在图像混合[37],图像生成[38],[39],图像风格转移[40]和解决拼图[41]方面取得了令人印象深刻的结果。通常,常见的基于GAN的方法的输入是噪声或单个图像。从多输入中获取信息也是一个重要的研究课题[42],[43]。Guo等人介绍了一种基于GAN的多聚焦图像融合系统,该系统利用生成器生成所需的掩模图[44]。Huang等人提出了一种自适应权重块来确定源像素是否聚焦。[45]Li等人提出了AttentionFGAN,将注意力机制应用到GAN框架中,并使用注意力特征融合红外和可见光图像[46]。最近,提出了一些基于GAN的方法来处理多曝光图像[8],[20],[21]。Xu等人引入了自注意机制来解决多次曝光图像的亮度变化[20]。Yang等人通过增加鉴别器的数量来融合曝光过度和曝光不足的图像[21]。Niu等人结合了对抗学习和基于参考的残差合并块来解决大运动[8]。然而,这些基于GAN的方法严重依赖于成对的训练数据集,因此它们的性能受到很大限制。相比之下,我们提出了UPHDRGAN来融合多个曝光输入,这与未配对的数据集兼容,因此我们提出的网络的灵活性和鲁棒性得到了显着提高。
III. METHOD
我们提出了一个基于GAN的多曝光融合框架,这是第一个设计用于处理未配对数据集的HDR成像任务的方法。类似于常见的GAN框架,生成器G将源域的输入变换为具有目标域特征的期望输出,而鉴别器D将目标域图像与生成的图像区分开以优化G。我们收集的数据集包括有和没有地面实况的场景。通过分解输入和地面真实值之间的对应关系,获得不成对的训练集。为了更好地描述框架,收集两个域数据,包括(1)源LDR域X,其由广泛多样的多曝光序列x = {x1,x2,x3}构成,以及(2)目标域Y,其由HDR图像的集合构成。我们将它们的数据分布分别表示为x~pdata(x)和y~pdata(y)。所提出的UPHDR-GAN可以在没有配对数据集的情况下生成具有较少重像伪影的HDR图像。
A. Network Architecture
UPHDR-GAN是一个具有三个输入和一个输出的图像到图像任务。UPHDR-GAN的结构如图所示。2.网络架构的详细层配置如表I所示。为了提高效率,我们以64的步幅从训练图像中裁剪256 × 256个重叠块,而不是用全尺寸图像优化模型。编码器包含三个分支,并且每个分支的输入大小为256x256 × 6,其是输入x = {x1,x2,x3}及其映射的HDR图像Hm = {H1,H2,H3}的级联。Hm使用简单的伽马编码来获得:
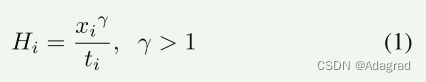
其中xi是输入图像,ti是对应的曝光时间。LDR图像和映射的HDR图像是互补的,其中前者检测饱和度和未对准,而后者促进网络跨LDR图像的收敛。
在得到HDR输出Ho之后,我们添加了一个µ-law [5]后处理来细化生成的HDR图像的范围,因为在色调映射的HDR图像上计算损失函数更有效:
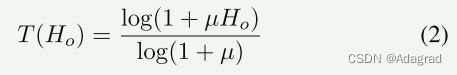
其中Ho分别是输出HDR图像和真实的HDR图像,μ表示压缩量,在我们的实现中设置为5,000。
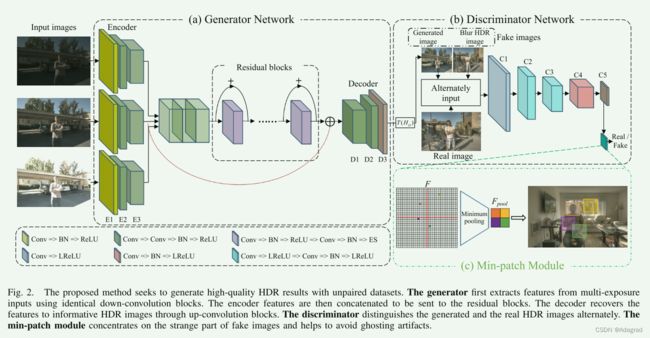
1)生成器:生成器网络由编码器、残差块和解码器组成。具体地,编码器由三个卷积块组成:E1、E2和E3,如表中所述。一、有用的信号在编码器过程中被提取,并用于后续残差块以探索高级特征。两个转置卷积块(D1和D2)和卷积层(D3)构成解码器以恢复特征以输出图像。
2)鉴别器:鉴别器与发生器互补。应用PatchGAN [47]对图像块而不是完整图像进行分类。我们从生成的HDR图像和真实的HDR图像中裁剪70 × 70重叠块来训练基于块的鉴别器。然而,并非补丁中的所有区域都有助于训练期间的鉴别器优化。如果生成器产生的图像具有奇怪且不同于真实的图像的区域,则特殊区域可以被认为是不期望的重影伪影。多关注最奇怪的部分是必不可少的。
3)最小补丁模块:我们介绍了min-patch训练模块(图1)。2(c))在PatchGAN结束时。min-patch训练的实现是将可选的最小池化层添加到鉴别器的最终输出[43]。我们定义F来表示鉴别器中的“C5”卷积层之后的特征。在训练鉴别器时,应用常规PatchGAN,并使用F.在训练生成器时,我们在“C5”卷积层之后添加最小池化层。最小池化层(Fpool)之后的特征用于计算损失。生成器使用Fpool进行了优化,Fpool在检测生成图像的最重要部分(例如错误部分或奇怪部分)方面起着至关重要的作用。鉴别器使用普通PatchGAN区分真实的图像和伪图像,并使用F.在我们的实现中,'C5'卷积层之后的特征F的大小为64 × 64。我们使用16 × 16最小池用于min-patch训练模块,并输出大小为4 × 4的特征Fpool以优化生成器。
B. Loss Function
由于GAN是最小-最大优化系统,因此所提出的UPHDR-GAN优化以下等式以在生成器和鉴别器之间取得平衡:
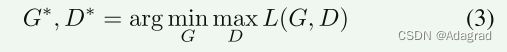
基于HDR成像特性,目标函数被设计为具有以下两项:(1)GAN损失LGAN(G,D),以实现将多曝光输入转换成HDR输出的期望变换;(2)在HDR变换期间保留图像语义信息的内容损失Lcon(G)。全损失函数为:
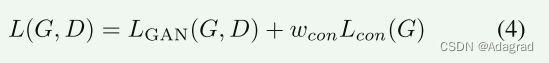
其中WCON是控制内容丢失的相对重要性的超参数,以便平衡变换和内容保存的效果。
1)GAN损失:GAN损失帮助G在缺乏地面实况的情况下生成与目标域图像类似的结果,并且使用生成的HDR图像和真实的HDR图像混淆D。然而,应用普通GAN损失是不够的,这不能保留边缘和边界信息,而这样的信息是重要的HDR图像。为此,Chen et al.[48]建议混淆D与模糊数据集,这已被证明是有用的样式转换。模糊数据集被认为是假图像,以驱动生成器生成具有清晰边缘的图像。类似地,我们还添加了模糊HDR数据集,以便于G生成高质量的输出。具体地,对于目标图像{yj}j=1,…M ∈ Y,我们利用核大小为5×5的高斯滤波器去除它们的清晰边缘并生成模糊数据集{bj}j=1,…,M ∈ B。我们在图中展示了模糊数据集的两个示例。3.在生成的图像中应避免边缘模糊的特点。选择模糊数据集作为假图像可以帮助网络生成没有模糊边缘的图像。换句话说,有三个类别需要由鉴别器分类:G(x)、B和y,其中生成图像G(x)和模糊HDR图像b是伪输入,真实的HDR图像y是真实输入。修改后的对抗性损失被设计为:

我们采用修改的对抗损失的否定形式,以便正确使用最小补丁训练模块。传统的对抗性损失最小化生成器损失,同时最大化鉴别器损失。现在,我们训练生成器以最大化损失函数,并训练鉴别器以最小化损失函数。逆优化是专门为最小补丁训练模块设计的,该模块仅在训练生成器时使用。修改后的生成器损失试图在通过最小池化之后最大化鉴别器值。较低的鉴别器输出暗示了假补丁,其可以表示模糊或重影区域。修改的发生器损耗可以通过最大化较低的鉴别器值来集中在这些奇怪的部分上。
2)内容物损失:GAN损失仅确保生成器产生类似于真实的HDR域图像的图像。单靠对抗性损失无法保证语义信息的保存。为语义一致性添加额外的约束是必要的。通常,我们选择具有中等曝光的图像作为参考图像,并且将具有欠曝光和过曝光的图像与参考对准。内容丢失被定义为约束配对的中间曝光输入x2和生成的结果G(x)关于语义相似性。代替使用共同的MSE损失函数,感知损失[49]被应用来约束内容差异,其公式化为:
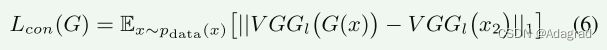
其中层L的选择是重要的。较大的l将提取高级特征。在我们的方法中,我们利用VGG19网络的“conv4 4”层的特征。
添加超参数wcon以平衡对抗损失和内容损失。对抗性损失影响解对域翻译,而内容损失限制了对域翻译的内容保留。较大的wcon破坏域变换并且由于来自输入的过多内容保留而生成不喜欢期望的HDR图像的结果,而较小的wcon更多地集中于未配对的域翻译并且参考图像的语义信息将被破坏。为了实现平衡,在初始阶段根据经验将wcon设置为1.5。在训练过程变得越来越稳定并且来自参考的内容信息得到合理的维护之后,wcon逐渐减小以实现域转换。wcon被描述为:
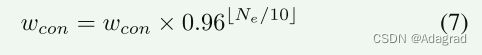
其中Ne是时期的数量,其在我们的实现中被设置为200。
V. CONCLUSION
我们已经提出了一种新的方法来生成HDR图像从多曝光输入与未配对的数据集。所提出的方法通过引入生成对抗网络来放松基于深度学习的方法需要成对输入和地面实况的约束。所提出的方法学习输入域和目标域之间的转换,并将多个输入转换为信息丰富的HDR输出。然而,生成对抗网络有时会得到不明确的结果。我们设计了特定的技术来生成具有清晰的边缘和清晰的内容信息的图像,包括初始化噬菌体,改进的对抗损失和设计的min-patch训练模块。已经进行了全面的实验,以证明所提出的UPHDR-GAN的有效性。