c语言初阶学习笔记——函数的嵌套调用和链式访问,函数的声明和定义,函数递归
文章目录
- 一、函数的嵌套调用和链式访问
-
- 1.嵌套调用
- 2.链式访问
- 二、函数的声明和定义
-
- 1.函数声明
- 2.函数定义
- 三、函数递归
-
- 1.什么是递归?
- 2.递归的两个必要条件
- 四、递归练习题
-
- 1.接受一个整型值(无符号),按照顺序打印它的每一位。
- 2.编写函数不允许创建临时变量,求字符串的长度。
- 3.求n的阶乘。(不考虑溢出)
- 4.求第n个斐波那契数。(不考虑溢出)
一、函数的嵌套调用和链式访问
函数和函数之间可以根据实际的需求进行组合的,也就是互相调用的。
1.嵌套调用
#include 函数可以嵌套调用,但是不能嵌套定义。
2.链式访问
把一个函数的返回值作为另外一个函数的参数。
#include 再来看一道题:
#include printf函数的返回值是打印在屏幕上字符的个数
所以结果是4321
二、函数的声明和定义
1.函数声明
- 告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,函数声明决定不了。
- 函数的声明一般出现在函数的使用之前。要满足先声明后使用。
- 函数的声明一般要放在头文件中的。
2.函数定义
函数的定义是指函数的具体实现,交待函数的功能实现。
函数有声明和定义,变量也有声明和定义
变量还是函数都得满足先定义(声明)后使用
变量的声明和定义可以写成下图
int a;//变量的声明
int main()
{
printf("%d\n", a);
return 0;
}
int a = 10;//定义
另一种写法(更推荐):
int a;//定义
int main()
{
printf("%d\n", a);
return 0;
}
函数的声明定义也类似:
//函数的声明
int Add(int x, int y);//可以写成int Add(int,int),交代类型即可
int main()
{
int a = 10;
int b = 20;
int c = Add(a, b);
printf("%d\n", c);
return 0;
}
//函数的定义
//不能因为声明中int Add(int x,int y)交代了类型,定义的时候就不交代类型了,
//如:int Add(x,y)是错误的
int Add(int x, int y)
{
return x + y;
}
另一种写法(更推荐):
//函数的定义
int Add(int x, int y)
{
return x + y;
}
int main()
{
int a = 10;
int b = 20;
int c = Add(a, b);
printf("%d\n", c);
return 0;
}
常见用法:

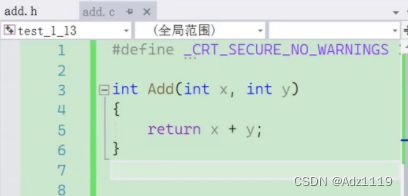
这样写的时候代码是分模块写的,大家更容易进行协助
三、函数递归
1.什么是递归?
程序调用自身的编程技巧称为递归( recursion)。
递归做为一种算法在程序设计语言中广泛应用。 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,
递归策略
只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。
递归的主要思考方式在于:把大事化小
2.递归的两个必要条件
- 存在限制条件,当满足这个限制条件的时候,递归便不再继续。
- 每次递归调用之后越来越接近这个限制条件。
下面来看一个简单的递归,死循环的会打印hehe

函数调用在栈区申请空间
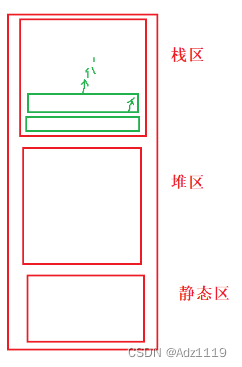
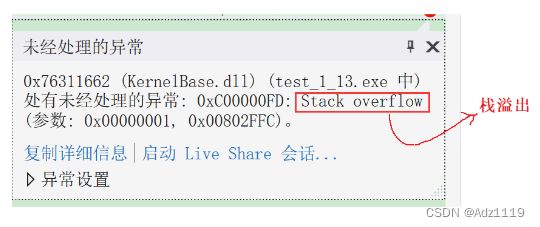
递归是函数自己调用自己,但是不能一直调用,一直调用会出现栈溢出的现象
四、递归练习题
1.接受一个整型值(无符号),按照顺序打印它的每一位。
例如:
输入:1234,输出 1 2 3 4
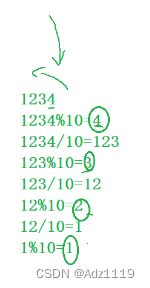
//%u - 无符号的整数
//%d - 有符号的整数
//Print(1234)
//Print(123) 4
//Print(12) 3 4
//Print(1) 2 3 4
void Print(unsigned int n)
{
if (n > 9)
{
Print(n / 10);
}
printf("%d ", n % 10);
}
int main()
{
unsigned int num = 0;
scanf("%u", &num);
Print(num);
return 0;
}
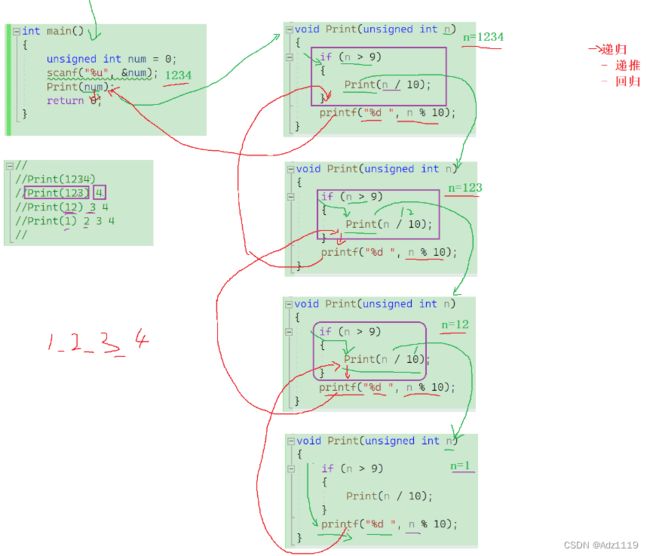
递归分为递推和回归,绿色线为递推,红色线为回归。
2.编写函数不允许创建临时变量,求字符串的长度。
首先想到循环实现:编写函数求字符串的长度。
//数组名是数组首元素的地址
int my_strlen(char* str)
{
int count = 0;
while (*str != '\0')
{
count++;
str++;
}
return count;
}
int main()
{
char arr[10] = "abc";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}
不允许创建临时变量,那么我们可以想到用递归
int my_strlen(char* str)
{
if (*str != '\0')
return 1 + my_strlen(str+1);
else
return 0;
}
int main()
{
char arr[10] = "abc";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}
大事化小的思想

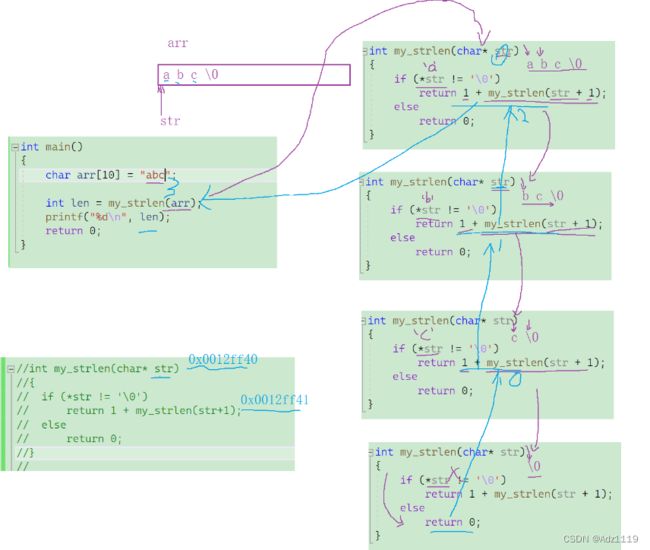
易错点:
错误写法:会发生死递归,因为拿到的str会指向相同的位置
int my_strlen(char* str)
{
if (*str != '\0')
return 1 + my_strlen(str++);
else
return 0;
}
不能用str++代替str+1,后置++,先使用再++,先把地址传进去再++,那么my_strlen得到的地址就和上次一样了。没++就传进去就不符合我们的预期了
假设第一次str指向的是a,*str != '\0’进入return 1 + my_strlen(str++);
my_strlen得到的就是str也就是a的地址,得到之后str++指向b,那么my_strlen得到的地址就和第一次得到的a一样了.
如果改为前置++,也不建议使用。这种++操作符是有副作用的。
my_strlen(str+1)是把下一个字符的地址传进去,留下的str没有被移动
如果是my_strlen(str++)把下一个字符的地址传进去,str会被移动
注:根据需要谨慎在递归中使用++操作符
为什么指针+1可以访问到下一个字符:
int main()
{
char arr1[] = "abcdef";
char* p1 = arr1;
int arr2[] = {'a','b','c','d','e','f','\0'};
int* p2 = arr2;
return 0;
}
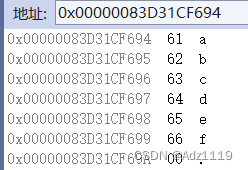
arr1:
arr2:
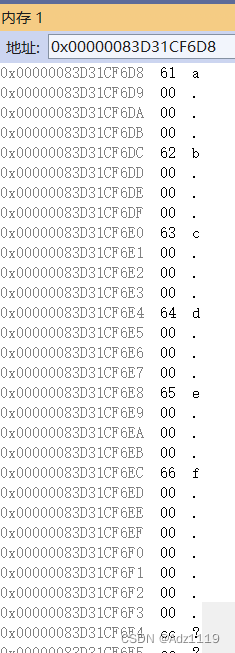
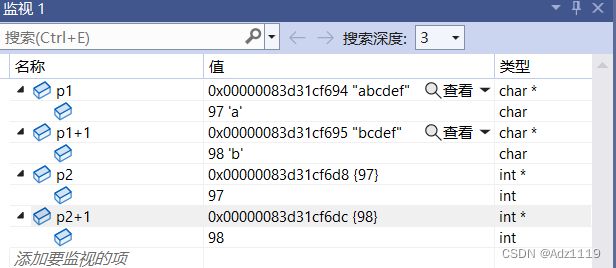
内存分为一个个的内存单元,一个单元大小是1byte
每个字节都有一个地址
整形指针解引用能访问四个字节,字符指针解引用访问一个字节
字符指针+1相当于跳过一个字符
整形指针+1相当于跳过一个整形
这和指针类型的意义有关,我们先理解字符指针+1相当于跳过一个字符即可,后面学习指针之后就明白了。
递归与迭代(循环是迭代的一种)
3.求n的阶乘。(不考虑溢出)
循环实现:
int fac(int n)
{
int i = 0;
int ret = 1;
for (i = 1; i <= n; i++)
{
ret = ret * i;
}
return ret;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = fac(n);
printf("%d\n", ret);
return 0;
}
递归实现:
int fac(int n)
{
if (n <= 1)
return 1;
else
return n * fac(n - 1);
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = fac(n);
printf("%d\n", ret);
return 0;
}
4.求第n个斐波那契数。(不考虑溢出)

int Fib(int n)
{
if (n <= 2)
return 1;
else
return Fib(n - 1) + Fib(n - 2);
}
但是我们发现有问题:
- 在使用 fib 这个函数的时候如果我们要计算第50个斐波那契数字的时候特别耗费时间。
- 使用 factorial 函数求10000的阶乘(不考虑结果的正确性),程序会崩溃。
为什么呢?
- 我们发现 fib 函数在调用的过程中很多计算其实在一直重复。
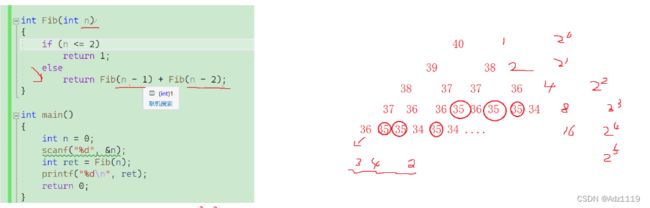
如果我们把代码修改一下:
int count = 0;//全局变量
int Fib(int n)
{
//统计的是第3个斐波那契数被重复计算的次数
if(n == 3)
count++;
if (n <= 2)
return 1;
else
return Fib(n - 1) + Fib(n - 2);
}
int main()
{
int n = 0;
scanf("%d", &n);//40
int ret = Fib(n);
printf("%d\n", ret);
printf("count = %d\n", count);
return 0;
}

最后我们输出看看count,是一个很大很大的值。
那我们如何改进呢?
在调试 Fib 函数的时候,如果你的参数比较大,那就会报错: stack overflow(栈溢出)
这样的信息。
系统分配给程序的栈空间是有限的,但是如果出现了死循环,或者(死递归),这样有可能导致一直开辟栈空间,最终产生栈空间耗尽的情况,这样的现象我们称为栈溢出。
那如何解决上述的问题:
将递归改写成非递归。
比如,下面代码就采用了,非递归的方式来实现:
//迭代的方式
int Fib(int n)
{
int a = 1;
int b = 1;
int c = 1;
while (n>=3)
{
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main()
{
int n = 0;
scanf("%d", &n);//40
int ret = Fib(n);
printf("%d\n", ret);
return 0;
}
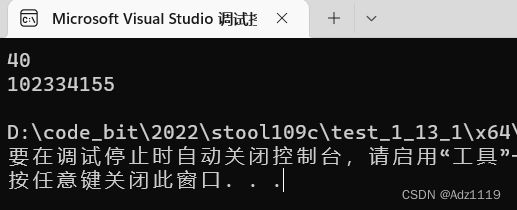

算出的结果太大会溢出,因为int类型的取值范围是有限的,超出范围就可能会导致符号位上的数为1,那么就打印出负数了。
递归只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。
当一个问题相当复杂,难以用迭代实现时,此时递归实现的简洁性便可以补偿它所带来的运行时开销。
许多问题是以递归的形式进行解释的,这只是因为它比非递归的形式更为清晰。
但是这些问题的迭代实现往往比递归实现效率更高,虽然代码的可读性稍微差些。
所以根据实际情况使用递归或者迭代。