编译原理——正规表达式与有限自动机(笔记)
一、正规式和正规集
正规集:程序设计语言的单词表、词汇集构成的集合,即是字的集合。它有一定特殊性,我们称之为正规集。用来代表程序语言的单词表。
正规式:可以说是正规集的名称。
- 正规集可以用正规表达式(简称正规式)表示
- 正规表达式是表示正规集一种方法
- 一个字集合是正规集当且仅当它能用正规式表示
比如,冯诺依曼构造自然数的方案,使用集合来定义(正规集),表达式来表达(正规式):
| 集合 | 表达式 |
| 0 | |
| 1 | |
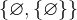 |
2 |
| 3 |
再比如:
DIM单独来说是一个正规式,也可以表达含有DIM和空集的正规集,即{DIM,![]() }。
}。
DIM,IF可以当作一个正规式,则{DIM,IF,![]() }为其对应的正规集。
}为其对应的正规集。

二、正规式和正规集的递归定义
对给定的字母表( 为字母表):
为字母表):
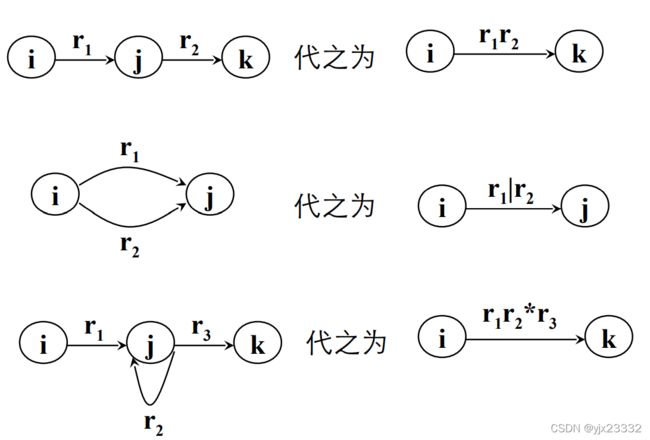
- 和都是上的正规式,它们所表示的正规集为和
- 任何, 则是上的正规式,它所表示的正规集为
- 假定
 和
和 都是上的正规式,它们所表示的正规集为和,则:
都是上的正规式,它们所表示的正规集为和,则:
1)![]() 为正规式,它所表示的正规集为
为正规式,它所表示的正规集为![]()
2)![]() 为正规式(做连接),它所表示的正规集为
为正规式(做连接),它所表示的正规集为![]() (连接)
(连接)
3)![]() 为正规式,它所表示的正规集为
为正规式,它所表示的正规集为![]() (闭包)
(闭包)
优先级:‘ ’比‘|’高
’比‘|’高
仅由有限次使用上述三步骤而定义的表达式才是上的 正规式,仅由这些正规式表示的字集才是上的正规集。
所有词法结构一般都可以用正规式描述
若两个正规式所表示的正规集相同,则称这两个正规式等价。如 b(ab)*=(ba)*b
证明
左侧:
L(b(ab)*)
= L(b)L((ab)*)
= L(b)(L(ab))*
= L(b)(L(a)L(b))*
= {b}{ab}*
= {b}{
,ab, abab,ababab,…}
= {b,bab,babab,bababab,…}
右侧:
L((ba)*b)
= L((ba)*)L(b)
= (L(ba))*L(b)
= (L(b)L(a))*L(b)
= {ba}*{b}
= {
= {b,bab,babab,bababab,...}
由于:L(b(ab)*) = L( (ba)*b)
因此:b(ab)*=(ba)*b
等价成立式
![]() |
|![]() =
= ![]() |
|![]() 交换律
交换律
![]() |(
|(![]() |
|![]() ) = (
) = (![]() |
|![]() )|
)|![]() 结合律
结合律
![]() (
(![]()
![]() ) =(
) =( ![]()
![]() )
)![]() 结合律
结合律
![]() (
(![]() |
|![]() ) =
) = ![]()
![]() |
|![]()
![]() 分配律
分配律
(![]() |
|![]() )
)![]() =
= ![]()
![]() |
|![]()
![]() 分配律
分配律
 =
= ![]() =
= 
![]()
![]() !=
!= ![]()
![]()
三、有限自动机(Finite Automata)
确定与非确定统称为有限自动机。
1.确定有限自动机(DFA,Deterministic Finite Automata)
对状态图进行形式化,则可以下定义:
确定有限自动机 (DFA) M 是一个五元式
此处M是指其DFA实例: DFA M
M=(S, , f, ![]() , F),其中:
, F),其中:
1.S:有穷状态集,即包含起点重点在内的,各个状态
2.:输入字母表(有穷),即状态改变的条件
3.f:状态转换函数,为 ![]() 的单值部分映射,即由A状态到B状态的改变
的单值部分映射,即由A状态到B状态的改变
f(s,a) = s’ 表示:当现行状态为s ,输入字符为a时,将状态转换到下一状态s’,s’称为s的一个后继状态
4.![]() :是唯一的一个初态,即起点唯一
:是唯一的一个初态,即起点唯一
5.![]() :终态集(可空),即最终状态,不唯一。
:终态集(可空),即最终状态,不唯一。
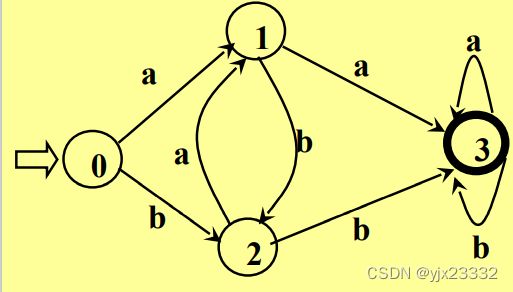
比如:
DFA M=({0,1,2,3},{a,b},f,0,{3}),
其中,f 定义如下:
f(0,a) = 1, f(0,b) = 2
f(1,a) = 3, f(1,b) = 2
f(2,a) = 1, f(2,b) = 3
f(3,a) = 3, f(3,b) = 3
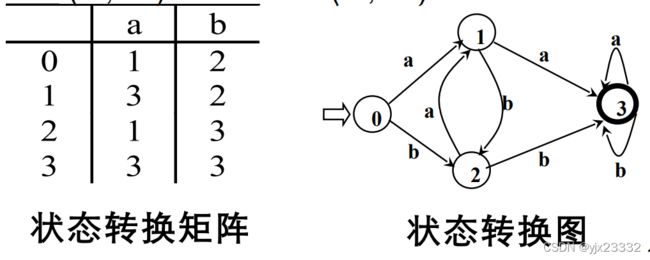
如上图所示,DFA 可以表示为状态转换图
- 假定 DFA M含有m个状态和n个输入字符
- 这个图含有m个状态结点,每个结点顶多含有 n 条箭弧射出,且每条箭弧用 Σ 上的不同的输入字符来作标记
对于Σ * 中的任何字 ,若存在一条从初态到某一终态的道路,且这条路上所有弧上的标记符连接成的字等于,则称为DFA M 所识别(接收)
,若存在一条从初态到某一终态的道路,且这条路上所有弧上的标记符连接成的字等于,则称为DFA M 所识别(接收)
DFA M 所识别的字的全体记为 L(M)
换言之,从初态到终态的字符,构成了一个字(一个字符也可以定义为一个字)。而所有的初态到终态可形成的字的集合就是字符集。
字与字的组合(或者单个字)可以作为一个正规式,其所代表的就是正规集。
2.非确定有限自动机 (NFA,Nondeterministic Finite Automata)
一个非确定有限自动机 (NFA) M,
是一个五元式 M=(S, , f, ![]() , F) ,其中:
, F) ,其中:
1.S: 有穷状态集
2.:输入字母表(有穷)
3.f: 状态转换函数,![]() 为的部分映射
为的部分映射
4.![]() :是非空的初态集
:是非空的初态集
5![]() :终态集 ( 可空 )
:终态集 ( 可空 )
对于 * 中的任何字,若存在一条从初态 到某一终态的道路,且这条路上所有弧上 的标记字连接成的字等于 ( 忽略那些标记为的弧 ) ,则称为 NFA M 所识别 ( 接 收 )
NFA M 所识别的字的全体记为 L(M)
NFA示例:
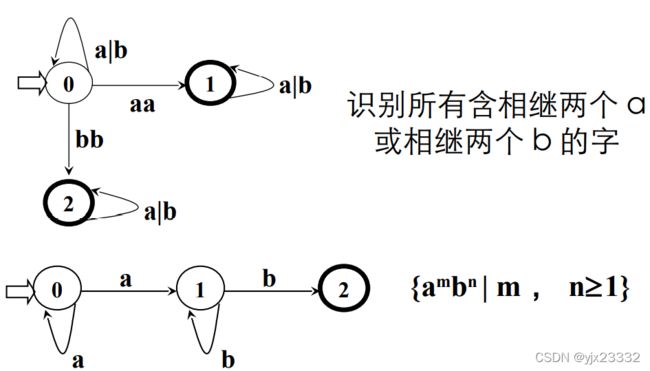
3.区别
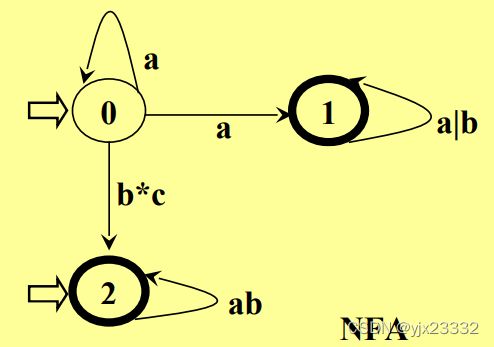
DFA:
- 如有后继状态,则其后继状态是唯一的
- 只有一个初态
- 弧上标记仅能为长度为1的字或单个字符
- 易于程序实现
NFA:
- 给定当前状态,其后继状态不是唯一的。
- 可有多个初态。
- 弧上的标记可以是字符、字,还可以是正规式。
- 同一个字可以出现在同状态的多条弧上
- 易于人工设计
DFA是NFA的特例
4.NFA与DFA
定义:对于任何两个有限自动机M和M’ ,如果L(M)=L(M’),则称 M 与 M’ 等价
自动机理论中一个重要的结论:判定两个自动机等价性的算法是存在的
对于每个NFA M 存在一个DFA M’,使得L(M)=L(M’)
DFA 与 NFA 描述能力相同
5.将NFA等价转换为DFA
1.假定 NFA M=<![]() >,我们对M的状态转换图进行以下改造:
>,我们对M的状态转换图进行以下改造:
1) 引进新的初态结点X和终态结点Y,X,Y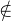 S,从X到
S,从X到![]() 中任意状态结点连一条箭弧,从F中任意状态结点连一条箭弧到 Y 。
中任意状态结点连一条箭弧,从F中任意状态结点连一条箭弧到 Y 。
(即,我们给一个NFA M多个初态前加了一个状态,使得其有唯一初态,末态同理)

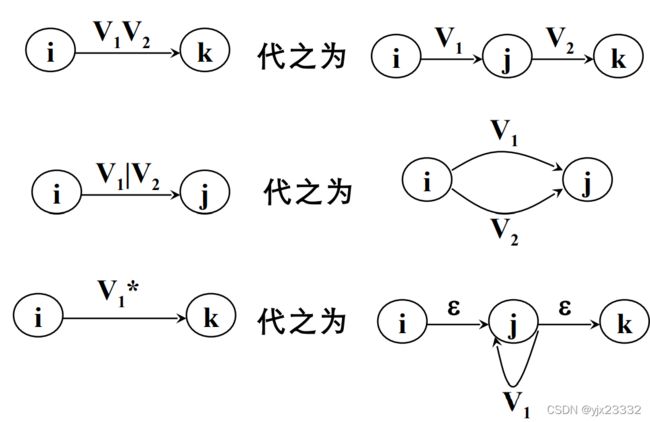
2) 对M的状态转换图进一步施行替换,其中k是新引入的状态。
(即,我们将aa,bb这样的换位下图3,4过程)

替换方法



通过上述过程,逐步把这个图转变为每条弧只标记为上的 一个字符或,
最后得到一个 NFA M’ , 显然 L(M’)=L(M)
2.接着我们再把把上述 NFA 确定化——采用子集法
概念
设 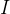 是的状态集的一个子集,定义 的 - 闭包, - closure() 为 :
是的状态集的一个子集,定义 的 - 闭包, - closure() 为 :
i) 若 s ,则 s
,则 s![]() -closure(I) ;
-closure(I) ;
ii) 若 s ,则从 s 出发经过任意条弧而能到达的任 何状态 s’ 都属于 -closure() 即
-closure()= {s’| 从某个 s‘| 出发经过任意条弧 能到达 s’
{s’| 从某个 s‘| 出发经过任意条弧 能到达 s’
设 是中的一个字符,定义
 = -closure(J)
= -closure(J)
其中, J 为 中的某个状态出发经过一条 弧而到达的状态集合。

比如

-closure({1}) = {1 , 2} = (从1出发,看与它距离一个的状态,就为)
J = {5 , 4 , 3}(从 -closure({1}) 出发,需要经过一个距离的状态就是J)
= -closure(J) = -closure({5 , 4 , 3}) = {5 , 4 , 3 , 6 , 2 , 7 , 8}




6.正规式与有限自动机的等价性
- 对任何 FA M ,都存在一个正规式 r , 使得 L(r)=L(M) 。
- 对任何正规式 r ,都存在一个 FA M , 使得 L(M)=L(r) 。
证明:
1.对上任一 NFA M ,构造一个上的正规 式 r ,使得 L(r)=L(M) 。

- 首先,在 M 的转换图上加进两个状态 X 和 Y ,从 X 用弧连接到 M 的所有初态结点,从 M 的所有终态结点用弧连接到 Y ,从而形成一 个新的 NFA ,记为 M’ ,它只有一个初态 X 和一个终态 Y ,显然 L(M)=L(M’) 。
- 然后,反复使用下面的一条规则,逐步消去的 所有结点,直到只剩下 X 和 Y 为止
- 最后, X 到 Y 的弧上标记的正规式即为所 构造的正规式 r
- 显然 L(r)=L(M)=L(M’)
替换方式即为之前的相反方向。
注意,要保留下每一个状态。比如下图,我们将1.左上的图变换至右上的图,2.再将右上的图变为最下面的图。

证明:
2.对于上的正规式r,构造一个 NFA M,使 L(M)=L(r),并且 M 只有一个终态,而且没有从该终态出发的箭弧。
下面使用关于 r 中运算符数目的归纳法证明上述结论。
1)若 r 具有零个运算符,则 r= 或 r=![]() 或 r=a ,其中 a
或 r=a ,其中 a![]() 。此时下图所示的三个有限自动机显然符合上述要求。
。此时下图所示的三个有限自动机显然符合上述要求。
左:识别
中:识别空
右:长度为1的字符

2)假设结论对于少于 k(k 1) 个运算符的正规式成立。当 r 中含有 k 个运算符时, r 有三种情形:
1) 个运算符的正规式成立。当 r 中含有 k 个运算符时, r 有三种情形:
情形 1 : ![]()
 和
和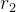 中运算符个数少于k 。从而,由归纳假设,对
中运算符个数少于k 。从而,由归纳假设,对  存在
存在![]() ,使得
,使得 ![]() , 并且 没有从终态出发的箭弧( i=1,2 )。 不妨设
, 并且 没有从终态出发的箭弧( i=1,2 )。 不妨设 ![]() =
=![]() ,在
,在 ![]() 中加入两个新 状态
中加入两个新 状态![]() 。
。

情形 2 : ![]()
设 同情形 1(i=1,2)

情形 2 :
设![]() 同情形1
同情形1
7.将正规表达式转换为有限自动机的算法
1)构造上的 NFA M’ 使得 L(V)=L(M’)
把 V 表示成
一样的替换逻辑
2)逐步把这个图转变为每条弧只标记为上的 一个字符或,最后得到一个 NFA M’ , 显然 L(M’)=L(V)
比如:
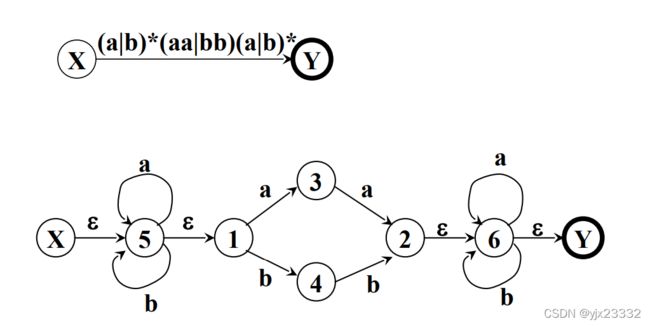
四、确定有限自动机的化简
是指:对DFA M的化简 : 寻找一个状态数比 M 少的 DFA M’ ,使得 L(M)=L(M’)
假设 s 和 t 为 M 的两个状态,称 s 和 t 等价:如果从状态 s 出发能读出某个字(任意)而 停止于终态,那么同样,从 t 出发也能读出而停止于终态;反之亦然
两个状态不等价,则称它们是可区别的(存在一个,使得从状态 s 出发能读出某个字(任意)停止于终态,从 t 出发读出停止于非终态,或者反过来)
DFA M 最少化的基本思想
把 M 的状态集划分为一些不相交的子集, 使得任何两个不同子集的状态是可区别的 ,而同一子集的任何两个状态是等价的。 最后,让每个子集选出一个代表,同时消去其他状态
按照上述原则,对 DFA 的状态集合 S 进行第 一次划分,将集合分为:终态和非终态。即找到一个字,划分连个状态(比如空字)
对 M 的状态集进行划分
1 首先,把 S 划分为终态和非终态两个子集 ,形成基本划分 。
。
2 假定到某个时候,已含 m 个子集,记为![]() ,检查中的每个子集看是否能进一步划分:
,检查中的每个子集看是否能进一步划分:
- 对某个
 ,令
,令 ,若存在 一个输入字符 a 使得
,若存在 一个输入字符 a 使得 不会包含在现行的某个子集
不会包含在现行的某个子集 中,则至少应把 分为两个部分。
中,则至少应把 分为两个部分。
2.1 如何划分为两个部分:
- 假定状态
 和
和  经 a 弧分别到达
经 a 弧分别到达  和
和  : 和 属于现行中的两个不同子集。说明有一个字 , 读出 后到达终态,而 读出后不能到达终态,或者反之。
: 和 属于现行中的两个不同子集。说明有一个字 , 读出 后到达终态,而 读出后不能到达终态,或者反之。 - 那么对于字 a , 读出 a 后到达终态 ,而 读出 a 不能到达终态,或者反之
- 所以 和 不等价
- 将 I (i) 分成两半,使得一半含有 :,且 s 经 a 弧到达 t, 且 t 与 属于现行 中的同一子集
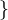 ;另一半含有 :
;另一半含有 : -
一般地,对某个 a 和
,若 落入现行 中 N 个不同子集,则应把 划分成 N 个不相交的组,使得每个组 J 的  都落入的 同 一子集。这样构成新的划分。
都落入的 同 一子集。这样构成新的划分。

3 重复上述过程,直到 所含子集数不再增长。
4 对于上述最后划分 中的每个子集,我们选取每个子集 中的一个状态代表其他状态, 则可得到化简后的 DFA M’ 。
5 若 含有原来的初态,则其代表为新的初态 ,若 含有原来的终态,则其代表为新的终态
我们使用上述算法,对下图优化:

首先把其分为两个集合:非终态和终态集合:

随后,我们判断非终态集合:识别a时,发现3不在当前子集中:

于是将抵达1的与抵达3的分开:

在此判断第一个集合,判断识别a时,抵达状态是否在子集;判断识别b时,状态是否在子集中,发现不在:

于是将抵达2的和抵达4的分开:
![]()
在此判断,发现非终态集合划分完毕。判断终态,发现均在子集中:

由此可以画出:

五、词法分析器的自动产生 --LEX




Yacc 与 Lex 快速入门
http://www.ibm.com/developerworks/cn/linux/sdk/lex/index.html
UNIX, LINUX
The Lex & Yacc Page
http://dinosaur.compilertools.net/
Flex (The Fast Lexical Analyzer):
http://flex.sourceforge.net/
for Windows:
http://gnuwin32.sourceforge.net/packages/flex.htm
六、正规文法与有限自动机的等价性
对于正规文法 G 和有限自动机 M ,如果 L(G) = L(M) ,则称 G 和 M 是等价的
关于正规文法和有限自动机的等价性,有以下结论:
1. 对每一个右线性正规文法 G 或左线性正规文法 G ,都存在一个有限自动机 (FA) M ,使得 ![]()
2. 对每一个 FA M ,都存在一个右线性正规文法 ![]() 和左线性正规文法
和左线性正规文法  ,使得
,使得 ![]()
例子:
右线性文法->NFA:
推导:
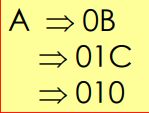

左线性文法->NFA
推导:


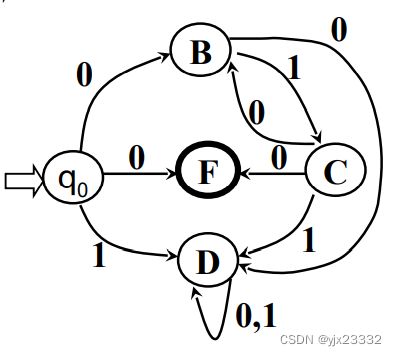
证明:
1.对每一个右线性正规文法 G 或左线性正规文法 G ,都构造一个有限自动机 (FA) M ,使得 L(M) = L(G) 。
(1) 设右线性正规文法 ![]() 。将
。将  中的每一非终结符号视为状态符号, 并增加一个新的终结状态符号 f ,
中的每一非终结符号视为状态符号, 并增加一个新的终结状态符号 f , ![]() 。 令
。 令 ![]() ,其中状态转换函数
,其中状态转换函数 由以下规则定义:
由以下规则定义:
(a)若对某个 ![]() 及
及 ![]() , P 中有产生式 A→a ,则令 (A,a)=f
, P 中有产生式 A→a ,则令 (A,a)=f
(b) 对任意的 ![]() 及
及 ![]() ,设 P 中左端为 A ,右端第一符号为 a 的所有产生式为: A→
,设 P 中左端为 A ,右端第一符号为 a 的所有产生式为: A→![]() |…|
|…|![]() (不包括 A→a ), 则令 (A,a)={
(不包括 A→a ), 则令 (A,a)={![]() ,…,
,…,![]() } 。
} 。
显然,上述 M 是一个 NFA 。
(2) 设左线性正规文法 ![]() 。将 中的每一非终结符号视为状态符号,并 增加一个初始状态符号
。将 中的每一非终结符号视为状态符号,并 增加一个初始状态符号![]() ,
, ![]() 。 令 M=
。 令 M=![]() ,其中状 态转换函数由以下规则定义:
,其中状 态转换函数由以下规则定义:
(a) 若对某个 ![]() 及
及 ![]() ,若 P 中有产生式 A→a,则令 (
,若 P 中有产生式 A→a,则令 (![]() ,a)=A
,a)=A
(b) 对任意的 ![]() 及
及 ![]() ,若 P 中所有右端第一符号为 A ,第二个符号为 a 的产生式为:
,若 P 中所有右端第一符号为 A ,第二个符号为 a 的产生式为:  则令 (A,a)=
则令 (A,a)=![]() 。
。
与 (1) 类似,可以证明 L(G) = L(M)
2.对每一个 DFA M ,都存在一个右线性正规文法 ![]() 和左线性正规文法 GL , 使得 L(M) = L(
和左线性正规文法 GL , 使得 L(M) = L(![]() ) = L() 。
) = L() 。
设 DFA ![]()
(1)若 ![]() ,我们令
,我们令 ![]() ,其中 P 是由以下规则定义的产生式集合:
,其中 P 是由以下规则定义的产生式集合:
对任何 ![]() 及 A,BS ,若有 (A,a)=B ,则:
及 A,BS ,若有 (A,a)=B ,则:
(a)当 BF 时,令 A→aB
(b) 当 BF 时,令 A→a|aB 。
对任何 ![]() ,不妨设
,不妨设 ![]() ,其中
,其中 ![]() (i=1,…k) 。若
(i=1,…k) 。若 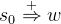 ,则存在一个最左推导 :
,则存在一个最左推导 :

因而,在 M 中有一条从 ![]() 出发依次经过
出发依次经过 ![]() 到达终态的通路,该通路上所有箭弧的标记依次为
到达终态的通路,该通路上所有箭弧的标记依次为  。反之亦然。所 以, wL(GR ) 当且仅当 wL(M) 。
。反之亦然。所 以, wL(GR ) 当且仅当 wL(M) 。
(2)现在考虑 ![]() 的情形,
的情形,
因为![]() ,所以
,所以![]() 。但不属于上面构造的
。但不属于上面构造的 ![]() 所产生的语言 L(
所产生的语言 L(![]() ) 。不难发现, L(
) 。不难发现, L(![]() )=L(M)-{} 。
)=L(M)-{} 。
所以,我们在上述 GR 中添加新的非终结符号 ![]() , (
, (![]() )和产生式
)和产生式 ![]() ,并用
,并用 ![]() 代替
代替 ![]() 作开始符号。这样修正
作开始符号。这样修正 ![]() 后得到的文法
后得到的文法 ![]() 仍是右线性正规文法,并且 L(
仍是右线性正规文法,并且 L(![]() )=L(M) 。
)=L(M) 。
(2) 类似于 (1) ,从 DFA M 出发可构造左线性正规文法 ,使得 L()=L(M) 。 最后,由 DFA 和 NFA 之间的等价性,结论 2 得证明。
小结
