字符串的性质、相关操作、相关方法
在day08下创建一个名为04-字符串的代码文件。
一、对于计算机来说,字符串是一堆没有意义的符号。只是人根据自然语言,想象出和这一堆符号相关的含义
二、字符串就是由引号引起来的有限个符号的合集
三、字符串的性质
1、字符串是有序的容器型数据类型(下标)
2、字符串是不可变的容器行数据类型(字符串中的元素一旦确定(字符串被定义出来),无法再次修改,没有增删改)
3、字符串是使用引号(单引号、双引号、三引号)作为容器符号
4、字符串的数据类型:str
5、除了特殊符号(转义字符)之外,所有的符号放入到字符串中只能代表其本身
6、字符串分为:普通字符和转义字符
四、创建一个字符串 --> 就把空字符串代表空气
str1 = ''
print(str1, type(str1))
五、字符串的拼接(+)、重复(
)*
str2 = 'abcd'
str3 = '1234'
print(str2 + str3)
print(str2 * 10)
六、字符串的比较大小
1、字符串比较大小比较的是同位置的元素
2、从左向右比较大小,直到比较到第一对不相同元素,来区分大小
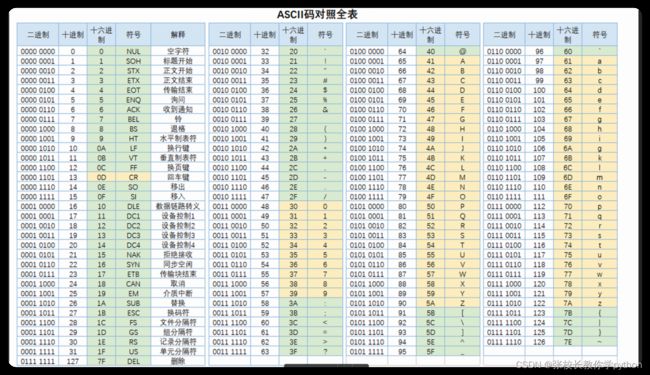
3、字符串比较大小比较的是编码值的大小(python2使用的是ASCII编码表,一共128个符号)(python3使用的是Unicode编码表(万国码,utf-8))
print(str2 > str3)
print('兔' > '虎') # 看编码值
打印结果如下:

数字0 - 9对应的十进制范围:48 - 57;
大写字母A - Z对应的十进制范围:65~90;
小写字母a - z对应的十进制范围:97~122
相同字母大小写之间相差32,小写字母>大写字母
chr:能够将编码值转换为对应的符号
ord:能够将编码表中的符号转换成对应的十进制数值(ord中只能接受长度为1的字符串)
print(ord('兔'), ord('虎'))
print(chr(20820))
打印结果如下:

兔对应的编码值为20820,虎对应的编码值为34382,不用感到惊讶达到那么大的数值,因为我们现在操作的是万国码,世界上有几十万的符号,每天都有新的符号产生。
把所有的Unicode编码表的符号拿出来。直接用死循环,Unicode编码是有终点的,到了终点之后,再拿一个不存在的符号就报错了,所以直接死循环执行。(别轻易试,可能会卡顿,如果要尝试记得注释掉,电脑受不了的)
PS:
有一点千万不要忘了,把print里的end换行(end = ‘/n’)
(篇的末尾)要改掉,不改掉的话,控制台会出现几万行甚至会出现几十万行,所以不要换行了,报错说明到终点了。
i = 0
while True:
print(chr(i), end = '')
i += 1
截取一部分打印结果:

Unicode编码表的关系,Unicode是在ASCII的基础上拓展的。
中文的范围:十六进制范围:\u4e00 ~ \u9fa5
print(ord('\u4e00'), ord('\u9fa5'))
得出中文范围:19968 - 40869

打印所有的汉字:
前面我们讲到range方法是一个左闭右开区间,要把开区间屏蔽掉,所以40869要加1,即是(19968, 40870)
print(ord('\u4e00'), ord('\u9fa5'))
for i in range(19968, 40870):
print(chr(i), end='')
随意截取一部分打印结果:

我们打印出所有的汉字,不会读,怎么办?
在day08下创建一个名为05-查看中文拼音的代码文件。
Python有一个三方模块叫做pypinyin,能够查看汉字的拼音
1、python之所以强大,是因为有许多的模块(实现各种功能的模块)前面我们学过random模块、time模块
2、Python有一个三方模块叫做pypinyin,能够查看汉字的拼音
3、打开python官网可以搜索python内置的标准模块,在浏览器中 ctrl+F 调出搜索框,通过搜索模块关键字即可查看
4、如果想看python常用的三方模块 --> 打开pypi官网
【在pypi官网文档我们可以学习相关知识】
使用示例

那么pypi网站是干嘛的?
1)puthon三方模块使用时需要安装,就像安装插件一样要在python中安装那些小插件,要在网上安装,那么python为什么知道你要安装的是这个模块呢?
2)pypi是存放三方模块的官方仓库,所有安装的模块都会经过这个地方来安装
3)那么,你想学习什么样的三方模块呢?比如说,我们后面学习爬虫,会接触
requests模块,直接在这里搜索即可
注意:
标准形式的安装太麻烦了,下面就是标准安装方式(官网文档中),我们后期再来说

【想看汉字的拼音,python有pypinyin这个模块,直接在搜索框搜索即可
我们先来安装非标准化安装,我们先打开pycharm的设置】
File --> setting --> Project --> Python interpreter --> 点+ --> 搜索pypinyin --> 点击右下角install package
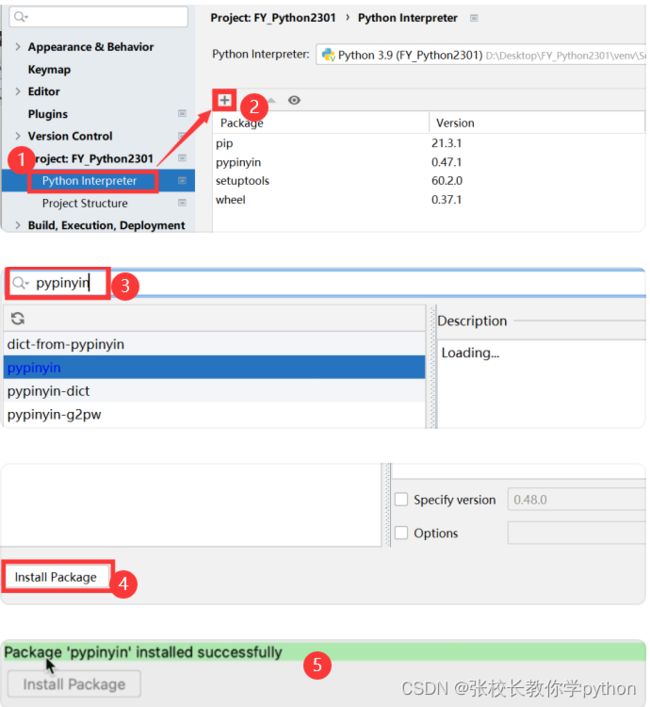
安装成功后退出即可,接下来我们就可以查看拼音啦
from pypinyin import pinyin
print(ord('\u4e00'), ord('\u9fa5'))
for i in range(19968, 40870):
print(chr(i), pinyin(chr(i), heteronym=True), end='')
随意截取一部分打印结果:

在day08下创建一个名为06-字符串的相关操作的代码文件。
一、字符串的遍历
str1 = 'abcdefg'
1、直接遍历
for i in str1:
print(i)
打印结果为:

2、间接遍历(使用下标)
----> 使用下标获取元素,前面是下标,后面是对应的元素
for i in range(len(str1)):
print(i, str1[i])
打印结果为:

二、字符串的下标和切片和列表的是一摸一样
str2 = '王者荣耀和平精英奇迹暖暖'
1、得到:‘王荣和精’
----> 下标从0开始取,到6结束,切片也是左闭右开区间,所以取到7,步长为2,每间隔1个取一个
print(str2[0:7:2])
2、得到:‘和平’
print(str2[4:6])
3、得到:‘英精平和’
----> 倒着取,步长为-1,对于起点和终点的下标怎样取,我们回忆一下切片的性质
print(str2[-5:3:-1])
print(str2[-5:-9:-1])
print(str2[7:3:-1])
打印结果如下:

三、字符串的成员运算 --> not in、in
1、'王者荣耀’在不在str2中
print('王者荣耀' in str2)
2、'和’在不在str2中
print('和' not in str2)
打印结果如下:

再如:
str1 = '王者荣耀和平精英'
print('王' in str1)
print('王者' in str1) # 连续
print('王荣' not in str1) # 不连续
字符串中每个元素都是字符串的子串,连续的元素也属于其字串,但不连续的就不能作为其字串。
打印结果:

字符串的子串(有一段长度 >= 1,<= 原字符串长度的字符串,属于原字符串的)
在day08下创建一个名为07-字符串的相关方法的代码文件。
1、upper:将字符串中的所有小写字母转大写
str1 = '12345abcdeABCDE'
print(str1.upper())
2、lower:将字符串中所有的大写字母转小写字母
str1 = '12345abcdeABCDE'
print(str1.lower())
练习:将给定字符串中所有大写字母变成小写字母,所有小写字母变成大写字母。
str1 = '12345abcdeABCDE'
str2 = ''
for i in str1: # 对字符串做遍历
if 'a' <= i <= 'z': # 证明是小写字母(字符串比较大小)
# str2 += i
str2 = str2 + chr(ord(i) - 32)
elif 'A' <= i <= 'Z':
str2 = str2 + chr(ord(i) + 32)
else:
str2 = str2 + i
print(str2)
ord(i):表示把i转换为十进制,小写字母在大写字母后面(小写字母编码值大于大写字母的编码值)相同字母之间编码值相差32
ord(i) - 32:表示把变量i对应的小写字母的编码值转为相应大写字母的编码值
chr(ord(i) - 32):表示把相应大写字母的编码值再转换为大写字母,这就实现了小写字母转换为大写字母
chr(ord(i) + 32):大写字母转换为小写字母也同样理解
打印结果如下

3、max、min:找出字符串中的最大值和最小值(按照编码值寻找)
str1 = 'abcdeABCDE'
print(min(str1),max(str1))
4、count:计数,统计某个符号的次数
str2 = '12345abcde'
print(str2.count('1'))
5、len:查看字符串中元素个数(字符串的长度)
总结:len方法能够查看容器的长度(字符串、列表、元组、集合、字典)
6、index:查找某个元素的位置(打印的是下标),找到之后结束查找,找不到报错 --> 查找方式:默认是从左向右正序查找(从0开始数下标)
语法一:str1.index(str2) --> 在str1中查找str2第一次出现的位置
str3 = 'abcde123abcde'
print(str3.index('c'))
如果想得到第二个C的位置?
语法二:str1.index( str2,开始下标)
print(str3.index('c', str3.index('c') + 1))
找不到元素就报错:
str3.index('4') # substring not found
7、find:和index方法一样,但是find方法不会报错,找不到元素就返回-1
print('find方法', str3.find('c'))
print('find方法', str3.find('c', str3.find('c') + 1))
print('find方法', str3.find('4'))

8、split:将字符串按照指定的元素进行切割,返回一个列表,列表中的元素便是切割点左右两边的元素
str4 = '1 2 3 4 5 6 7 8'
strList = str4.split(' ')
print(strList)
9、join:将字符串容器(字符串列表、字符串、字符串元组等)中的所有元素按照指定的符号拼接
str5 = '+'.join(strList)
print(str5)
10、replace : 替换、能够将字符串中指定的旧字符串换成新的字符串 --> replace 还可以指定替换次数
str4 = '1 2 3 4 5 6 7 8'
print(str4.replace(' ', '+'))
print(str4.replace(' ', '+', 2))
11、strip:去掉字符串头尾的空白符号(空格、\n、\t等)
print('*************')
str6 = '\t abc 123 \n'
print(str6)
print('*************')
print(str6.strip())
print('*************')
print(str6.strip('\n'))
print('*************')
打印结果如下:

下一期我们讲一讲字符串的练习题,大家先试着做一做!!!
1、输入用户名,判断用户名是否合法(用户名长度6~10位)
2、输入用户名,判断用户名是否合法(用户名中只能由数字和字母组成)
例如: ‘abc’ — 合法 ‘123’ — 合法 ‘abc123a’ — 合法
3、输入用户名,判断用户名是否合法(用户名必须包含且只能包含数字和字母,并且第一个字符必须是大写字母)
例如: ‘abc’ — 不合法 ‘123’ — 不合法 ‘abc123’ — 不合法 ‘Abc123ahs’ — 合法 ‘Abc’ — 不合法
4、输入一个字符串,统计字符串中非数字非字母的字符的个数
例如: 输入’anc2+93-sj胡说’ 输出:4 输入’===’ 输出:3
1、输入一个小于1000的数字,产生对应的学号
例如:
输入’23’,输出’py1901023’
输入’9’, 输出’py1901009’
输入’123’,输出’py1901123’
2、判断一个数字是否是回文数 ----> 什么是回文数,将一个数字反回来依旧是这个数字。
例如:12321、456654
3、输入一个字符串,将字符串中所有的数字字符取出来产生一个新的字符串
例如:输入’abc1shj23kls99+2kkk’ 输出:‘123992’
4、输入一个字符串,打印所有奇数位上的字符(下标是1,3,5,7…位上的字符)
例如: 输入’abcd1234’ 输出’bd24’