MySQL高级-存储引擎+存储过程+索引(详解01)
目录
1.mysql体系结构
2.存储引擎
2.1.存储引擎概述
2.2.1.InnoDB
2.2.2.MyISAM
2.2.3.存储引擎选择
3.存储过程
3.1.存储过程和函数概述
3.2.创建存储过程
3.3.调用存储过程
3.4.查看存储过程
3.5.删除存储过程
3.6.语法
3.6.1.变量
3.6.2.if条件判断
3.6.3.传递参数
3.6.4.case结构
3.6.5.while循环
3.6.6.repeat结构
3.6.7.游标/光标
3.7.存储函数 ---存储过程 函数:函数有返回值
4.索引
4.1.索引概述
4.2.索引优势劣势
4.3.索引结构
4.3.1.二叉树
4.3.2.B-TREE 结构
4.3.3.B+Tree结构-->Mysql
4.3.4.数据库中B+tree的结构
4.4.索引分类
4.5.索引的语法
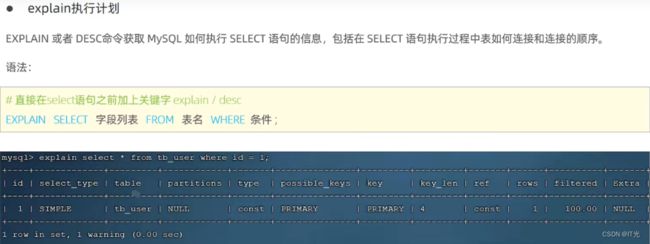
4.6.性能分析
4.7.索引使用规则
1.mysql体系结构
1) 连接层
主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
2) 服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3) 引擎层 [存储引擎]
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。 在之前[MyISAM]: MySQL5.5之后,MySQL默认的存储引擎就是InnoDB,InnoDB默认使用的索引结构就是B+树,上面的服务层就是通过API接口与存储引擎层进行交互的
4)存储层
数据存储层, 主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
和其他数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎上,插件式的存储引擎架构,将查询处理和其他的系统任务以及数据的存储提取分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。

2.存储引擎
2.1.存储引擎概述
和大多数的数据库不同, MySQL中有一个存储引擎的概念, 针对不同的存储需求可以选择最优的存储引擎。
存储引擎就是存储数据,建立索引,更新查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的。
Oracle,SqlServer 等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎。
可以通过指定 show engines , 来查询当前数据库支持的存储引擎 :\
创建新表时如果不指定存储引擎,那么系统就会使用默认的存储引擎,MySQL5.5之前的默认存储引擎是MyISAM,5.5之后就改为了InnoDB。
查看Mysql数据库默认的存储引擎 , 指令 :
show variables like '%storage_engine%' ;
2.2.1.InnoDB
InnoDB存储引擎是Mysql的默认存储引擎。InnoDB存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎不同于其他存储引擎的特点 :
事务控制
-- 创建表 create table goods_innodb( id int NOT NULL AUTO_INCREMENT, name varchar(20) NOT NULL, primary key(id) )ENGINE=innodb DEFAULT CHARSET=utf8;-- innodb支持事务 start transaction; -- 开启事务 INSERT INTO goods_innodb VALUES (1,'aaa'); -- 添加数据 commit; -- 提交事务 因为支持事务所以不提交则添加失败测试,发现在InnoDB中是存在事务的
外键约束
MySQL支持外键的存储引擎只有InnoDB, 在创建外键的时候, 要求父表必须有对应的索引 , 子表在创建外键的时候, 也会自动的创建对应的索引。
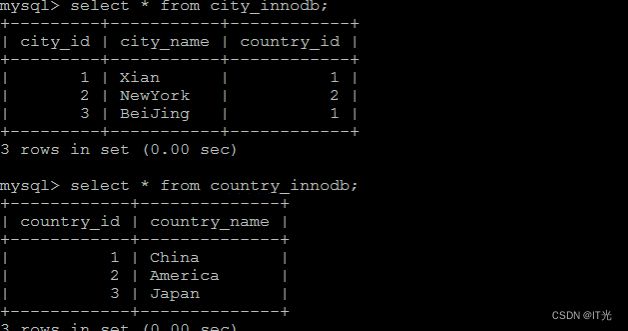
下面两张表中 , country_innodb是父表 , country_id为主键索引,city_innodb表是子表,country_id字段为外键,对应于country_innodb表的主键country_id 。
-- 创建表 测试是否支持外键 create table country_innodb( country_id int NOT NULL AUTO_INCREMENT, country_name varchar(100) NOT NULL, primary key(country_id) )ENGINE=InnoDB DEFAULT CHARSET=utf8; create table city_innodb( city_id int NOT NULL AUTO_INCREMENT, city_name varchar(50) NOT NULL, country_id int NOT NULL, -- 外键 primary key(city_id), key idx_fk_country_id(country_id), CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_innodb(country_id) ON DELETE RESTRICT ON UPDATE CASCADE )ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into country_innodb values(null,'China'),(null,'America'),(null,'Japan'); insert into city_innodb values(null,'Xian',1),(null,'NewYork',2),(null,'BeiJing',1);在创建索引时, 可以指定在删除、更新父表时,对子表进行的相应操作,包括 RESTRICT、CASCADE、SET NULL 和 NO ACTION。
- RESTRICT和NO ACTION相同, 是指限制在子表有关联记录的情况下, 父表不能更新;
- CASCADE表示父表在更新或者删除时,更新或者删除子表对应的记录;
- SET NULL 则表示父表在更新或者删除的时候,子表的对应字段被SET NULL 。
针对上面创建的两个表, 子表的外键指定是ON DELETE RESTRICT ON UPDATE CASCADE 方式的, 那么在主表删除记录的时候, 如果子表有对应记录, 则不允许删除, 主表在更新记录的时候, 如果子表有对应记录, 则子表对应更新 。
表中数据如下图所示 :
删除country_id为1 的country数据:
delete from country_innodb where country_id = 1;有外键约束,删除失败
更新主表country表的字段 country_id :
update country_innodb set country_id = 100 where country_id = 1;更新后, 子表的数据信息为 :
2.2.2.MyISAM
MyISAM 不支持事务、也不支持外键,其优势是访问的速度快,对事务的完整性没有要求或者以SELECT、INSERT为主的应用基本上都可以使用这个引擎来创建表 。有以下两个比较重要的特点:
不支持事务
-- 创建表 create table goods_myisam( id int NOT NULL AUTO_INCREMENT, name varchar(20) NOT NULL, primary key(id) )ENGINE=myisam DEFAULT CHARSET=utf8;-- MyISAM不支持事务 start transaction; -- 开启事务 insert into goods_MyISAM VALUES (1,'aaa'); -- 添加数据通过测试,我们发现,在MyISAM存储引擎中,是没有事务控制的 ;
不支持外键
create table country_myisam( country_id int NOT NULL AUTO_INCREMENT, country_name varchar(100) NOT NULL, primary key(country_id) )ENGINE=MyISAM DEFAULT CHARSET=utf8; create table city_myisam( city_id int NOT NULL AUTO_INCREMENT, city_name varchar(50) NOT NULL, country_id int NOT NULL, primary key(city_id), key idx_fk_country_id(country_id), CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_myisam(country_id) ON DELETE RESTRICT ON UPDATE CASCADE )ENGINE=MyISAM DEFAULT CHARSET=utf8; insert into country_myisam values(null,'China'),(null,'America'),(null,'Japan'); insert into city_myisam values(null,'Xian',1),(null,'NewYork',2),(null,'BeiJing',1);
通过删除测试,我们发现,在MyISAM存储引擎中,是没有外键约束的
- innodb: 支持事务和外键,而且表结构存在一个文件中,索引和数据存储在idb文件中
- myisam: 不支持事务和外键,它的表结构存在在frm中,索引和数据分别存在在myi和myd文件中
2.2.3.存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
- InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。






3.存储过程
3.1.存储过程和函数概述
存储过程和函数是 事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程和函数可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程和函数的区别在于函数必须有返回值,而存储过程没有。
函数 : 是一个有返回值的过程 ;
过程 : 是一个没有返回值的函数 ;
3.2.创建存储过程
语法:
CREATE PROCEDURE procedure_name ([proc_parameter[,...]]) begin -- SQL语句 end ;示例 :
-- 存储过程入门01 delimiter $ -- 定义结束符 CREATE PROCEDURE p01() BEGIN select 'Hello 存储过程' ; END $ delimiter ;DELIMITER:该关键字用来声明SQL语句的分隔符 , 告诉 MySQL 解释器,该段命令是否已经结束了,mysql是否可以执行了。默认情况下,delimiter是分号;。在命令行客户端中,如果有一行命令以分号结束,那么回车后,mysql将会执行该命令。
3.3.调用存储过程
CALL p01();3.4.查看存储过程
-- 查询mysqlg数据库中的所有的存储过程 select name from mysql.proc where db='mysqlg'; -- 查询存储过程的状态信息 show procedure status;3.5.删除存储过程
DROP PROCEDURE p01
3.6.语法
存储过程是可以编程的,意味着可以使用变量,表达式,控制结构 , 来完成比较复杂的功能。
3.6.1.变量
DECLARE:
通过 DECLARE 可以定义一个局部变量,该变量的作用范围只能在 BEGIN…END 块中。
DECLARE var_name[,...] type [DEFAULT value]示例 :
-- 声明变量 delimiter $ create procedure p02() -- 创建存储过程 begin declare num int default 5; -- 声明num,默认为5 select num+ 10; -- 输出加10 end $ delimiter ; CALL p02(); -- 调用存储过程SET:直接赋值使用 SET,可以赋常量或者赋表达式,具体语法如下:
SET var_name = expr [, var_name = expr] ...示例 :
-- 为变量重新赋值 DELIMITER $ CREATE PROCEDURE p03() BEGIN declare num int default 5; -- 设置变量nun默认为5 SET num = 20; -- 重新赋值num为20 SELECT num ; -- 输出 END$ DELIMITER ; CALL p03(); -- 调用存储过程也可以通过select ... into 方式进行赋值操作 :
-- 通过select ... into 方式进行赋值操作 : DELIMITER $ CREATE PROCEDURE p04() BEGIN declare num int default 5; -- num默认为5 select count(*) into num from city_innodb; -- 将表city_innodb中共几条数据赋值给num select num; -- 输出 END$ DELIMITER ; CALL p04(); -- 调用存储过程
3.6.2.if条件判断
语法结构 :
if search_condition then statement_list [elseif search_condition then statement_list] ... [else statement_list] end if;需求:
根据定义的身高变量,判定当前身高的所属的身材类型 并输出该身材 180 及以上 ----------> 身材高挑 170 - 180 ---------> 标准身材 170 以下 ----------> 一般身材示例 :
delimiter $ create procedure p05() begin declare height int default 175; declare description varchar(50); if height >= 180 then set description = '身材高挑'; elseif height >= 170 and height < 180 then set description = '标准身材'; else set description = '一般身材'; end if; select description ; end$ delimiter ; call p05();
3.6.3.传递参数
语法格式 :
create procedure procedure_name([in/out/inout] 参数名 参数类型) ... IN : 该参数可以作为输入,也就是需要调用方传入值 , 默认 OUT: 该参数作为输出,也就是该参数可以作为返回值 INOUT: 既可以作为输入参数,也可以作为输出参数IN - 输入
需求 :根据定义的身高变量,判定当前身高的所属的身材类型
示例 :
delimiter $ create procedure p06(in height int) begin declare description varchar(50) default ''; if height >= 180 then set description='身材高挑'; elseif height >= 170 and height < 180 then set description='标准身材'; else set description='一般身材'; end if; select concat('身高 ', height , '对应的身材类型为:',description); end$ delimiter ; call p06(200);OUT-输出
需求 :根据传入的身高变量,获取当前身高的所属的身材类型
示例:
delimiter $ CREATE PROCEDURE p07(in height int ,out description VARCHAR(50)) BEGIN if height >= 180 then set description = '111' ; ELSEIF height >= 170 and height < 180 THEN set description = '222' ; ELSE set description = '333' ; END if ; end $ delimiter ;调用:
CALL p07(180,@a); -- @代表定义一个局部变量 SELECT @a;@a: 这种变量要在变量名称前面加上“@”符号,叫做用户会话变量,代表整个会话过程他都是有作用的,这个类似于全局变量一样。
@@global.sort_buffer_size : 这种在变量前加上 "@@" 符号, 叫做 系统变量
3.6.4.case结构
语法结构 :
方式一 : CASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] ... [ELSE statement_list] END CASE; ----传递一个int类型的数字 如果为1 则输出星期一 方式二 : 返回 CASE WHEN search_condition THEN statement_list [WHEN search_condition THEN statement_list] ... [ELSE statement_list] END CASE;需求: 给定一个月份, 然后计算出所在的季度
示例 :两种方式
delimiter $ create procedure p08(month int) begin declare result varchar(20); case when month >= 1 and month <=3 then set result = '第一季度'; when month >= 4 and month <=6 then set result = '第二季度'; when month >= 7 and month <=9 then set result = '第三季度'; when month >= 10 and month <=12 then set result = '第四季度'; end case; select concat('您输入的月份为 :', month , ' , 该月份为 : ' , result) as content ; end$ delimiter ; call p08(12); -- /// delimiter $ create procedure p09(in m int) begin case m when 1 then SELECT '第一季度'; when 2 then SELECT '第一季度'; when 3 then SELECT '第一季度'; when 4 then SELECT '第二季度'; when 5 then SELECT '第二季度'; when 6 then SELECT '第二季度'; when 7 then SELECT '第三季度'; when 8 then SELECT '第三季度'; when 9 then SELECT '第三季度'; when 10 then SELECT '第四季度'; when 11 then SELECT '第四季度'; when 12 then SELECT '第四季度'; else SELECT '输入有误' ; END case ; end$ delimiter ; CALL p09(10);
3.6.5.while循环
语法结构:
while search_condition do statement_list end while; --别忘记分号需求: 计算从1加到n的数的和值
示例 :
delimiter $ create procedure p10(n int) begin declare total int default 0; declare num int default 1; while num<=n do set total = total + num; set num = num + 1; end while; select total; end$ delimiter ; CALL p10(100);
3.6.6.repeat结构
有条件的循环控制语句, 当满足条件的时候退出循环 。while 是满足条件才执行,repeat 是满足条件就退出循环。
语法结构 :
REPEAT statement_list UNTIL search_condition --不要加分号 END REPEAT;需求: 计算从1加到n的值
示例 :
-- repeat 结构 delimiter $ create procedure p11(n int) begin declare total int default 0; repeat set total = total + n; set n = n - 1; until n=0 end repeat; select total ; end$ delimiter ; call p11(100);
3.6.7.游标/光标
游标是用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH 和 CLOSE,其语法分别如下。
声明游标:
DECLARE cursor_name CURSOR FOR select_statement ; -- select语句OPEN 游标:
OPEN cursor_name ;FETCH 游标:
FETCH cursor_name INTO var_name [, var_name] ...CLOSE游标:
CLOSE cursor_name ;示例 :
初始化脚本:
create table emp( id int(11) not null auto_increment , name varchar(50) not null comment '姓名', age int(11) comment '年龄', salary int(11) comment '薪水', primary key(`id`) )engine=innodb default charset=utf8 ; insert into emp(id,name,age,salary) values(null,'金毛狮王',55,3800),(null,'白眉鹰王',60,4000),(null,'青翼蝠王',38,2800),(null,'紫衫龙王',42,1800);create PROCEDURE p13() begin DECLARE n varchar(20); DECLARE s int; DECLARE has_data int default 1; -- 判断游标中是否还有数据 -- 声明游标 DECLARE my CURSOR for select name,salary from emp; -- DECLARE EXIT HANDLER FOR NOT FOUND set has_data = 0; create table if not EXISTS tb_my( id int primary key auto_increment, name varchar(20), salary int ); -- 开启游标-- open my; while has_data=1 do -- 取出游标的数据 FETCH my INTO n,s; insert into tb_my(name,salary) values(n,s); end while; close my; end; call p13();
使用mybatis调用到存储过程。
通过循环结构 , 获取游标中的数据 :
DELIMITER $ create procedure pro_test12() begin DECLARE id int(11); DECLARE name varchar(50); DECLARE age int(11); DECLARE salary int(11); DECLARE has_data int default 1; DECLARE emp_result CURSOR FOR select * from emp; -- 若没有数据返回,程序继续,并将变量has_data设为0 DECLARE EXIT HANDLER FOR NOT FOUND set has_data = 0; open emp_result; repeat fetch emp_result into id , name , age , salary; select concat('id为',id, ', name 为' ,name , ', age为 ' ,age , ', 薪水为: ', salary); until has_data = 0 end repeat; close emp_result; end$ DELIMITER ;
java如何调用存储过程

3.7.存储函数 ---存储过程 函数:函数有返回值
注意:mysql5.8需要设置如下内容
SET GLOBAL log_bin_trust_function_creators = 1;语法结构: public 返回类型 函数名(参数){}
CREATE FUNCTION function_name([param type ... ]) RETURNS type BEGIN ... END;案例 :
定义一个存储函数, 请求满足条件的总记录数 ;
delimiter $ create function count_city(countryId int) returns int begin declare cnum int ; select count(*) into cnum from city where country_id = countryId; return cnum; end$ delimiter ;调用:
select count_city(1); select count_city(2);
4.索引
4.1.索引概述
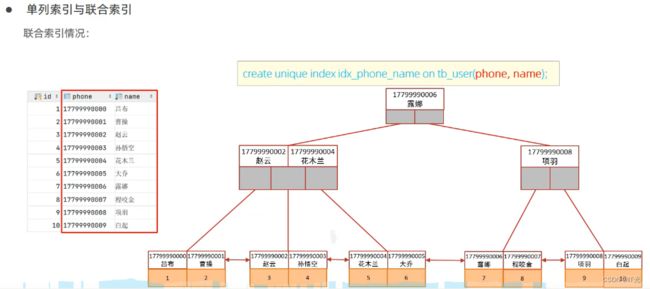
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高效查找算法,这种数据结构就是索引。如下面的示意图所示 :
索引就是一种数据结构B+Tree,为了提高数据库查询数据的效率。
左边是数据表,一共有三列10条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快age的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性能的最常用的手段。
4.2.索引优势劣势
4.3.索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引结构算法:
MyISAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
B+TREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
HASH 索引:只有Memory引擎支持 , 使用场景简单 。
R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
Full-text (全文索引 倒排索引--ES) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
索引 NNODB引擎 MYISAM引擎 MEMORY引擎 B+TREE索引 支持 支持 支持 HASH 索引 不支持 不支持 支持 R-tree 索引 不支持 支持 不支持 Full-text 5.6版本之后支持 支持 不支持 我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引结构,统称为 索引。
4.3.1.二叉树
4.3.2.B-TREE 结构
动态演示
树演示地址
什么是B-树
4.3.3.B+Tree结构-->Mysql
什么是B+树
4.3.4.数据库中B+tree的结构
BTree: n阶 存放n-1个元素,可以有n个孩子。 每个元素中挂载相应的数据。
B+Tree: n阶 存放n-1个元素,可以有n个孩子。 所有元素都在叶子节点,而且叶子节点是一个闭环双向链表








4.4.索引分类
例如:
思考:

id查询更快,根据id可以直接查询到所有数据;根据name还需要回表查询id
4.5.索引的语法
例子:
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for student -- ---------------------------- DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `id` int(11) NOT NULL, `name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `phone` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `email` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `profession` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `age` int(11) NULL DEFAULT NULL, `gender` tinyint(4) NULL DEFAULT NULL, `status` tinyint(4) NULL DEFAULT NULL, `createtime` datetime(0) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of student -- ---------------------------- INSERT INTO `student` VALUES (1, '吕布', '17799990000', '[email protected]', '软件工程', 23, 1, 6, '2001-02-02 00:00:00'); INSERT INTO `student` VALUES (2, '曹操', '17799990001', '[email protected]', '通信工程', 33, 1, 0, '2001-03-05 00:00:00'); INSERT INTO `student` VALUES (3, '赵云', '17799990002', '[email protected]', '英语', 34, 1, 2, '2002-03-02 00:00:00'); INSERT INTO `student` VALUES (4, '孙悟空', '17799990003', '[email protected]', '工程造价', 54, 1, 0, '2001-07-02 00:00:00'); INSERT INTO `student` VALUES (5, '花木兰', '17799990004', '[email protected]', '软件工程', 23, 2, 1, '2001-04-22 00:00:00'); INSERT INTO `student` VALUES (6, '大乔', '17799990005', '[email protected]', '舞蹈', 22, 2, 0, '2001-02-07 00:00:00'); INSERT INTO `student` VALUES (7, '露娜', '17799990006', '[email protected]', '应用数学', 24, 2, 0, '2001-02-08 00:00:00'); INSERT INTO `student` VALUES (8, '程咬金', '17799990007', '[email protected]', '化工', 38, 1, 5, '2001-05-23 00:00:00'); INSERT INTO `student` VALUES (9, '项羽', '17799990008', '[email protected]', '金属材料', 43, 1, 0, '2022-08-25 17:00:45'); INSERT INTO `student` VALUES (10, '白起', '17799990009', '[email protected]', '机械工程及其自动化', 27, 1, 2, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (11, '韩信', '17799990010', '[email protected]', '无机非金属材料工程', 27, 1, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (12, '荆轲', '17799990011', '[email protected]', '会计', 29, 1, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (13, '兰陵王', '17799990012', '[email protected]', '工程造价', 44, 1, 1, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (14, '狂铁', '17799990013', '[email protected]', '应用数学', 43, 1, 2, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (15, '貂蝉', '17799990014', '[email protected]', '软件工程', 40, 2, 3, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (16, '妲己', '17799990015', '[email protected]', '软件工程', 31, 2, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (17, '芈月', '17799990016', '[email protected]', '工业经济', 35, 2, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (18, '嬴政', '17799990017', '[email protected]', '化工', 38, 1, 1, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (19, '狄仁杰', '17799990018', '[email protected]', '国际贸易', 30, 1, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (20, '安琪拉', '17799990019', '[email protected]', '城市规划', 51, 2, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (21, '典韦', '17799990020', '[email protected]', '城市规划', 52, 1, 2, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (22, '廉颇', '17799990021', '[email protected]', '土木工程', 19, 1, 3, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (23, '后裔', '17799990022', '[email protected]', '城市园林', 20, 1, 0, '2022-08-25 17:23:51'); INSERT INTO `student` VALUES (24, '姜子牙', '17799990023', '[email protected]', '工程造价', 29, 1, 4, '2022-08-25 17:23:51'); SET FOREIGN_KEY_CHECKS = 1;需求:
-- 1. name字段为姓名字段,该字段的值可能会重复,为该字段创建索引。 CREATE INDEX name_index on student(name); -- 单值索引【普通索引】 -- 2. phone手机号字段的值,是非空,且唯一的,为该字段创建唯一索引。 CREATE UNIQUE INDEX phone_index on student(phone); -- 唯一索引 -- 3. 为profession、age、status创建联合索引。 CREATE INDEX pro_age_status_index on student(profession,age,status); -- 复合索引【组合索引】 -- 4. 为email建立合适的索引来提升查询效率。 CREATE INDEX email_index on student(email); -- 普通索引SQL优化:为相应的列添加索引
4.6.性能分析
Windows---》my.ini中修改
查看慢查询日志是否开启
show VARIABLES like 'slow_quert_log'
查询慢查询日志就可以知道那条sql语句执行速度慢
环境准备
CREATE TABLE `t_role` ( `id` varchar(32) NOT NULL, `role_name` varchar(255) DEFAULT NULL, `role_code` varchar(255) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_role_name` (`role_name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `t_user` ( `id` varchar(32) NOT NULL, `username` varchar(45) NOT NULL, `password` varchar(96) NOT NULL, `name` varchar(45) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `user_role` ( `id` int(11) NOT NULL auto_increment , `user_id` varchar(32) DEFAULT NULL, `role_id` varchar(32) DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_ur_user_id` (`user_id`), KEY `fk_ur_role_id` (`role_id`), CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','超级管理员'); insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','系统管理员'); insert into `t_user` (`id`, `username`, `password`, `name`) values('3','ykq','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02'); insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','学生1'); insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','学生2'); insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老师1'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','学生','student','学生'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老师','teacher','老师'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教学管理员','teachmanager','教学管理员'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管理员','admin','管理员'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超级管理员','super','超级管理员'); INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
4.7.索引使用规则
注意: 根据id查询为什么没有执行覆盖索引。
如何避免索引失效---措施。
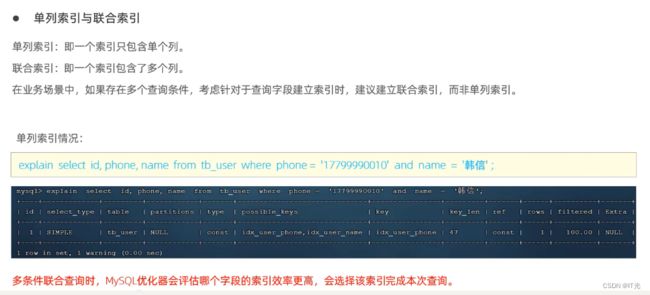
联合索引要遵循最左前缀法则
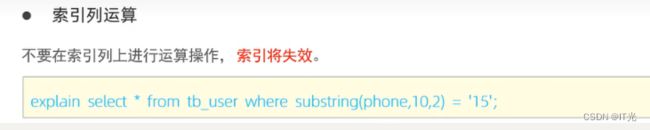
不要再索引列上进行运算
模糊查询时尽量右匹配
不要select *
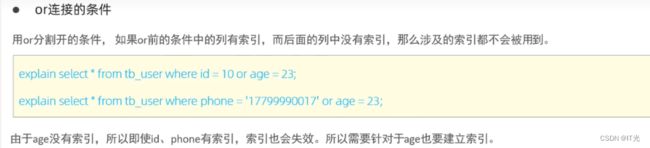
or连接时如果右侧没有索引会导致所有的索引失效
字符串类型的索引一定要加''号