高德地图爬虫
高德地图爬虫
工具:Pycharm,win10,Python3.6.4
1.需求分析
这篇爬虫和上一篇百度地图爬虫要求一样,百度地图爬虫我发现有一个auth参数会一直变化,一旦变化则获取的数据是不准确的,所以我上高德地图看了一下,高德地图没有这个反爬机制。但是高德地图大概爬取120个页面就会跳一次验证码,我这里是通过换IP解决这个问题的。
2.数据准备
同样我们需要全国地级市信息,用之前的数据即可
3.爬虫思路
首先打开高德地图搜索一个城市的养老院数量,看看需要的参数有哪些,已经我们要的信息在什么地方。
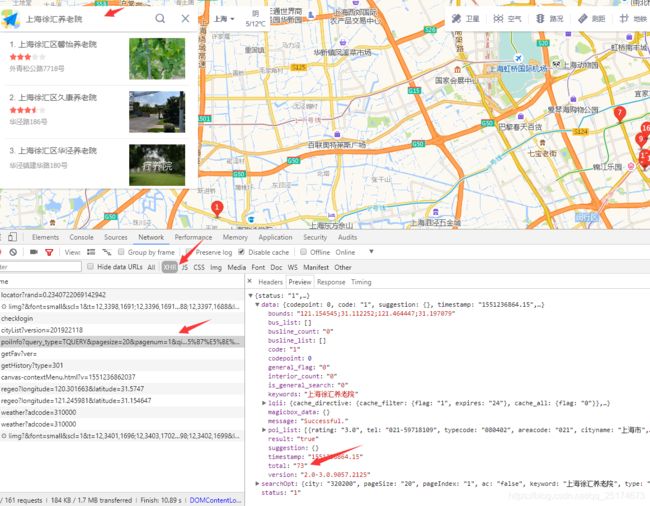
按照这个步骤我们就能看到我们要的养老院数量就存放在这个位置,我们只需要获取该网页即可获取信息。网页参数如下

红色方框即为我们需要的参数,有些参数可以省略,这个自行尝试。
代码如下:
import requests
import json
import xlwt
from urllib.parse import urlencode
import xlrd
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def get_page(keyword1, keyword2):
try:
data = {
# 'wd': keyword1+keyword2, # 修改关键字
'query_type': 'TQUERY',
'pagesize': '20',
'pagenum': '1',
'qii': 'true',
'cluster_state': '5',
'need_utd': 'true',
'utd_sceneid': '1000',
'div': 'PC1000',
'addr_poi_merge': 'true',
'is_classify': 'true',
'zoom': '12',
# 'city': '310000',
# 'geoobj': '121.184146|31.118573|121.678531|31.212581',
'keywords': keyword1 + keyword2,
}
# 把字典对象转化为url的请求参数
url = 'https://www.amap.com/service/poiInfo?' + urlencode(data)
# print(url)
response = requests.get(url, headers=headers, timeout=60)
response.encoding = 'utf-8'
html = response.text
# print(html)
return html
except:
get_page(keyword1, keyword2)
def parse_page(html):
try:
html = json.loads(html)
# print(html)
num = html['data']['total']
# print(num)
return num
except:
return '0'
def write2excel(keywords1, nums, keyword2):
book = xlwt.Workbook()
sheet = book.add_sheet('sheet1')
hang = 0
for i in range(len(keywords1)):
lie = 0
sheet.write(hang, lie, keywords1[i])
lie += 1
sheet.write(hang, lie, str(nums[i]))
hang += 1
book.save(keyword2 + '.xls')
def readExcel(filename):
keywords = []
# 打开文件
wordbook = xlrd.open_workbook(filename)
# 获取sheet4
Sheet4 = wordbook.sheet_by_name('Sheet4')
# 获取sheet4的第一列
cols = Sheet4.col_values(0)
for col in cols:
keywords.append(col.strip())
return keywords
if __name__ == '__main__':
keywords2 = ['养老院', '敬老院', '养老中心', '养老公寓']
# keywords2 = ['养老院']
for keyword2 in keywords2:
nums = []
keywords1 = readExcel('2.xls')
# keywords1 = ['合肥市肥西县']
for i in range(len(keywords1)):
html = get_page(keywords1[i], keyword2)
num = parse_page(html)
nums.append(num)
# print(type(nums[0]))
print(keywords1[i], num)
write2excel(keywords1, nums, keyword2)