K8S学习(一)概念
目录
1.K8S相关概念
Cluster
Master
Node
Pod
Controller Manager
Service
NameSpace
2.K8S架构和集群规划
K8S架构
K8S架构拆解图
K8S Master节点
K8S Node节点
K8S中Pod的创建流程
1.K8S相关概念
-
Cluster
Cluster由多台虚拟机或者物理设备组成,是计算、存储和网络等资源的集合,K8S利用这些资源运行各种基于容器的应用。
-
Master
Master是Cluster集群的大脑,它的主要职责是调度、即决定将应用放在哪个节点运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master。
-
Node
Node是用于运行容器应用的节点。Node由Master管理,Node主要负责监控并汇报容器的状态,并根据Master的要求管理容器的生命周期。Node运行在Linux操作系统上,可以是物理机或者虚拟机。
-
Pod
Pod是K8S的最小工作单元。每个Pod可以包含一个或者多个有紧密联系的容器应用。Pod中的容器回作为一个整体被Master调度到一个Node上运行。(Pod如何创建?通过Master上的Controller Manager)
K8S引入Pod主要基于下面两个目的:
-
可管理性。
有些容器天生就是需要紧密联系,一起工作。Pod 提供了比容器更高层次的抽象,将它们封装到一个部署单元中。Kubernetes 以 Pod 为最小单位进行调度、扩展、共享资源、管理生命周期。 -
通信和资源共享。
Pod 中的所有容器使用同一个网络 namespace,即相同的 IP 地址和 Port 空间。它们可以直接用 localhost 通信。同样的,这些容器可以共享存储,当 Kubernetes 挂载 volume 到 Pod,本质上是将 volume 挂载到 Pod 中的每一个容器。
Pods的使用方式:
-
运行单一容器。
one-container-per-Pod是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod。即便是只有一个容器,Kubernetes 管理的也是 Pod 而不是直接管理容器。 -
运行多个容器。
但问题在于:哪些容器应该放到一个 Pod 中?
答案是:这些容器联系必须 非常紧密,而且需要 直接共享资源。
Example:
下图的Pod包含两个容器:一个File Puller,一个是Web Server。
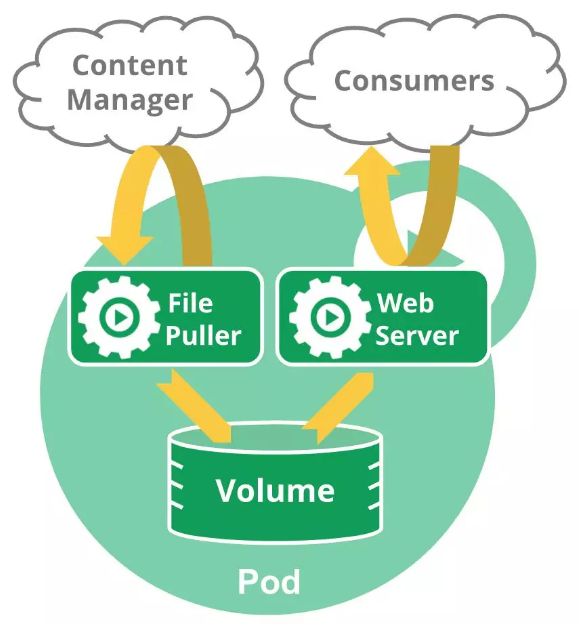
File Puller 会定期从外部的 Content Manager 中拉取最新的文件,将其存放在共享的 volume 中。Web Server 从 volume 读取文件,响应 Consumer 的请求。这两个容器是紧密协作的,它们一起为 Consumer 提供最新的数据;同时它们也通过 volume 共享数据。所以放到一个 Pod 是合适的。
再来看一个反例:是否需要将 Tomcat 和 MySQL 放到一个 Pod 中?
Tomcat 从 MySQL 读取数据,它们之间需要协作,但还不至于需要放到一个 Pod 中一起部署,一起启动,一起停止。同时它们是之间通过 JDBC 交换数据,并不是直接共享存储,所以放到各自的 Pod 中更合适。
-
Controller Manager
Controller Manager作为集群内部的管理控制中心,负责集群内的Node,Pod副本,服务端点(endpoint),命名空间(namespace)等的管理,当某个Node意外宕机,CM会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。
K8S通常不会直接创建Pod。而是通过CM来管理Pods的,Controller Manager中定义了Pod的部署特性,比如有几个副本,在哪个Node上运行等,CM有许多不同的Controller,用来提供各种功能。如下图:
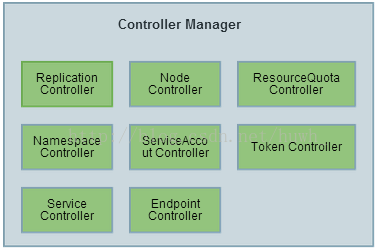
每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。
-
Service
Deployment Controller为Pod和Replication Set通过声明示更新,通过它够可以创建出多个Pod,每个Pod都有自己的IP,那么外界如何去访问这些Pod呢?通过Pod的IP吗?这肯定是不行对的,Pod可能会被频繁地创建,销毁,或者重启,它们的IP会频繁地变化,用Pod的IP去访问不太现实。
答案是使用Service。
Service在K8S中主要提供的功能是负载均衡和服务自动发现,它提供了我们访问单个或者多个容器应用的能力。每个Service在其生命周期内,都拥有一个固定的IP地址和端口(所以Pod的IP变化,不会影响到这个Pod的上层Service的IP地址变化)。这样也方便后端进行Pod的弹性伸缩等操作。
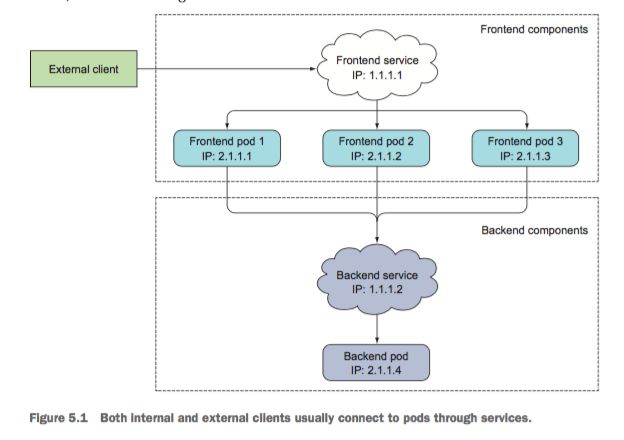
所有说K8S运行Pod和访问Pod这两项任务分别由Controller和Service执行。
-
NameSpace
我们可以认为NameSpace是K8S Cluster中的虚拟化集群。在一个K8S集群中可以有多个命名空间,这些命名空间在逻辑上彼此隔离。常见的pods, services, replication controllers和deployments等都是属于某一个NameSpace的(默认是default)。
类似于default这样的默认NameSpace,K8S集群共有三个:
- default:创建资源时如果不指定NameSpace的话,默认将被放到default中
- kube-system:kubernetes系统组件使用。
- kube-public:公共资源使用。但实际上现在并不常用。
2.K8S架构和集群规划
-
K8S架构
-
K8S架构拆解图
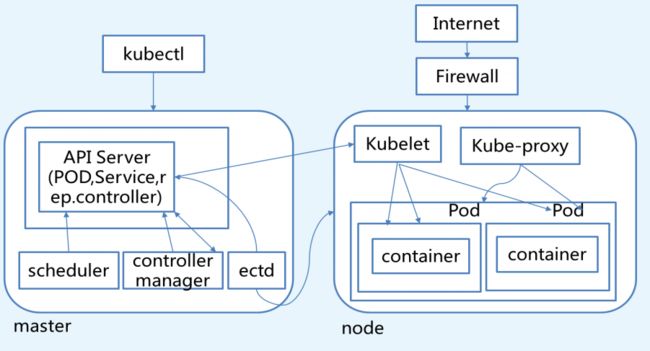
K8S Master节点
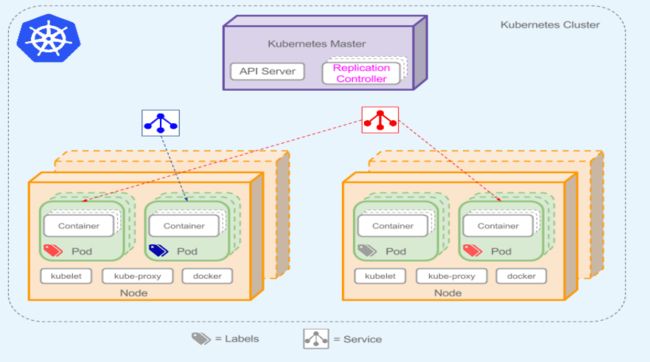
从上图可以看到K8S Cluster的大脑,运行着的Daemon服务包括kube-apiserver、kube-scheduler、kube-controller-manager、etcd和Pod网络(例如flannel)。
1. API Server (kube-apiserver)
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API。API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源。
2. Scheduler(kube-scheduler)
Scheduler负责决定将Pod放在哪个Node上运行。Scheduler在调度时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
3. Controller Manager(kube-controller-manager)
Controller Manager负责管理Cluster各种资源,保证资源处于预期的状态。Controller Manager 由多种Controller组成,包括replication controller、endpoint controller、namespace controller、serviceaccounts controller等。
不同的controller管理不同的资源。例如,replication controller管理Deployment、StatefulSet、DaemonSet的生命周期,namespace controller管理Namespace资源。
4. etcd
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速通知Kubernetes相关组件。
5. Pod网络
Pod要能够相同通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案。
K8S Node节点
Node是Kubernetes集群架构中运行Pod的服务节点(亦叫agent或minion)。Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。关联Master管理节点,拥有名称和IP、系统资源信息。运行docker eninge服务,守护进程kunelet及负载均衡器kube-proxy.
- 每个Node节点都运行着以下一组关键进程
- kubelet:负责对Pod对于的容器的创建、启停等任务
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
- Docker Engine(Docker):Docker引擎,负责本机容器的创建和管理工作
Node节点可以在运行期间动态增加到Kubernetes集群中,默认情况下,kubelet会向master注册自己,这也是Kubernetes推荐的Node管理方式,kubelet进程会定时向Master汇报自身情报,如操作系统、Docker版本、CPU和内存,以及有哪些Pod在运行等等,这样Master可以获知每个Node节点的资源使用情况,冰实现高效均衡的资源调度策略。
1. Kubelet:kubelet是node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet会根据这些信息创建和运行容器,并向master报告运行状态。
2. Kube-proxy: service在逻辑上代表了后端的多个Pod,外借通过service访问Pod。service接收到请求就需要kube-proxy完成转发到Pod的。每个Node都会运行kube-proxy服务,负责将访问的service的TCP/UDP数据流转发到后端的容器,如果有多个副本,kube-proxy会实现负载均衡,有2种方式:LVS或者Iptables。
3. 容器运行时环境,如Docker, rkt, runc等:负责节点的容器的管理工作。
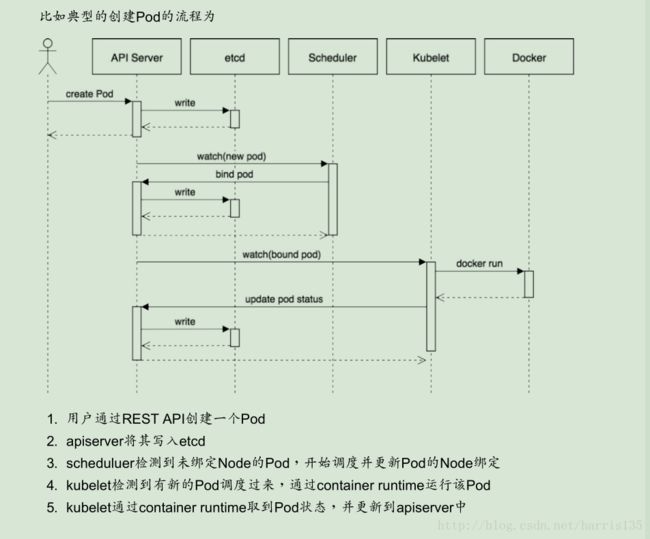
K8S中Pod的创建流程
创建Pod 的流程
1. 用户通过REST API创建一个Pod
2. apiserver将其写入etcd
3. scheduluer检测到未绑定Node的Pod,开始调度并更新Pod的Node绑定
4. kubelet检测到有新的Pod调度过来,通过container runtime运行该Pod
5. kubelet通过container run
参考:《每天5分钟玩转Kubernetes》、https://www.cnblogs.com/linuxk/