新视频超分算法来了!CVPR 2021 & NTIRE2021冠军方案
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:OpenMMLab | 来源:知乎
https://zhuanlan.zhihu.com/p/364872992
Hello, 小伙伴们~ 今天给大家带来的干货是新鲜出炉的 CVPR 2021,并斩获 比赛冠军。目前代码已经 Merge 到 MMEditing 中,欢迎大家尝鲜
论文题目:BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
论文:https://arxiv.org/abs/2012.02181
主页:https://ckkelvinchan.github.io/projects/BasicVSR/
代码:https://github.com/ckkelvinchan/BasicVSR-IconVSR
0 概括
与图像超分辨率相比,视频超分辨率(VSR)带来了一个额外的挑战,因为它涉及从视频序列中多个高度相关但未对齐的帧中聚集信息。现今已经有不同方法[1,2,3]来应对这一挑战,但是VSR方法复杂和不相容的设计给实施和扩展现有方法带来了困难,从而阻碍了未来的发展。因此,我们有必要重新考虑VSR模型的多样化设计,以为VSR寻找更通用,有效和易于实现的基线。
在这项工作中,我们首先将流行的VSR方法分解。我们观察到,大多数现有方法需要四个相互关联的组成部分,即传播,对齐,聚合和上采样。根据我们的分析,我们提出了BasicVSR,并证明只需对现有选件进行最小程度的重新设计,就可以得到一个强大而有效的基线。此外,通过information-refill mechanism和coupled-propagation来,我们进一步展示了BasicVSR的可扩展性。
BasicVSR及其扩展IconVSR可以作为将来VSR方法的牢固基线。请参见下图进行比较。值得注意的是,BasicVSR可以推广到各种视频还原任务。我们最近扩展了BasicVSR,并参与了NTIRE2021视频挑战。我们的模型在视频超分辨率和压缩视频增强挑战中获得了两个冠军。为了促进未来的发展,我们发布了代码和模型 MMEditing.

1 VSR方法的分析
通过我们的研究,我们得出结论,常见的VSR管道可以分解为四个部分:传播,对齐,聚合和上采样。下图显示了一些代表性方法的分解。

我们看到,许多现有方法将聚合的特征拼接起来,并采用pixel-shuffle进行上采样,它们主要在传播和对齐方式上有所不同。在这项工作中,我们将注意力集中在传播和对齐分析上。
传播: 传播可以大致分为三类:局部,单向和双向。为了了解它们的差异和贡献,我们进行了实验并观察了性能。
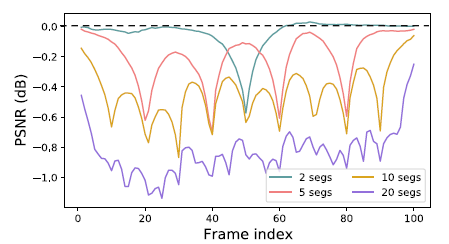
1. 我们证实采用全局传播的重要性。我们从(在时间维度上)全局感受野开始,然后逐渐减小感受野。我们将测试序列分为K个部分,并使用BasicVSR独立还原每个部分。如下图所示,当K减少时,PSNR的差异(对于K = 1的情况)减小。这表明远距离帧中的信息有利于恢复,因此不应忽略。此外,可以观察到,在每个段的两端,PSNR的差异最大,这表明需要采用长序列来积累长期信息。
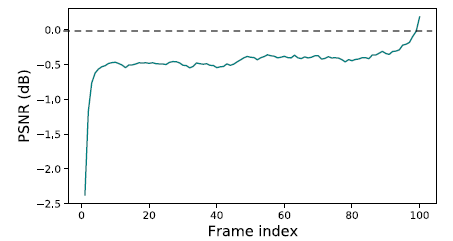
2. 然后,我们比较单向和双向传播。我们将BasicVSR(使用双向传播)与其单向变体进行了比较。从下图可以看出,单向模型在早期获得的PSNR明显低于双向传播,随着帧数量的增加,更多信息的聚集使差异逐渐减小。而且,仅采用部分信息,我们可以观察到稳定的性能下降。这些观察结果揭示了单向传播的次不足,而双向传播可以更有效利用视频中的信息,从而提高输出质量。
对齐: 现有的循环网络[4,5]通常在传播过程中不执行对齐。不对齐的特征/图像会阻止聚合,并最终导致性能下降。这种次优性可以通过我们的实验得到反映,我们在BasicVSR中删除了对齐模块。如果没有正确对齐,传播的特征将不会与输入图像在空间上对齐。结果,诸如卷积之类的局部运算未能有效地在对应的位置聚集信息。我们观察到PSNR下降了1.19 dB。该结果表明,采用具有足够大的感受野以聚集来自遥远空间位置的信息的操作是非常重要的。
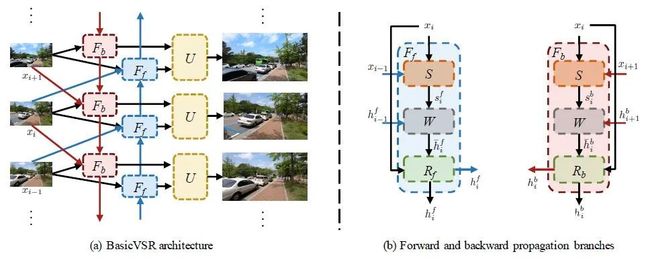
BasicVSR
从以上研究中,我们看到选择合适的组件设计的重要性。基于此,我们提出了BasicVSR,它包含了上述设计。在BasicVSR中,我们仅采用通用组件。这种简单性使BasicVSR可以用作强大而又易于扩展的基线。BasicVSR采用双向传播来充分利用视频序列中的信息,并使用光流进行特征对齐。然后,使用残差块对对齐的特征进行汇总,并通过pixel-shuffle对其进行上采样。
从BasicVSR到IconVSR
我们以BasicVSR为骨干,介绍了两个新颖的组件-Information-refill和coupled propagation(IconVSR),以减轻传播过程中的误差累积,并促进信息聚合。

Information-Refill: 遮挡区域和图像边界上的不正确对齐是一个严峻的挑战,可能导致误差累积,尤其是如果我们在框架中采用长期传播的话。为了减轻这种错误特征带来的不良影响,我们提出了一种信息补充机制,用于特征优化。附加的特征提取器用于从输入帧(关键帧)及其各自的邻域的子集中提取深层特征。然后通过卷积将提取的特征与对齐的特征融合。
Coupled Propagation: 在双向设置中,特征通常在两个相反的方向上独立传播。在这种设计中,每个传播分支中的特征都是根据部分信息(来自先前的帧或将来的帧)来计算的。为了利用序列中的信息,我们提出了coupled propagation。在coupled propagation中,传播模块是相互连接的,将后向传播的特征作为前向传播模块的输入。结果,前向传播分支从过去和将来的帧中接收信息,从而导致更高质量的特征,并因此获得更好的输出。更重要的是,由于coupled propagation只需要改变分支连接,我们可以在不引入计算开销的情况下获得性能增益。
实验结果
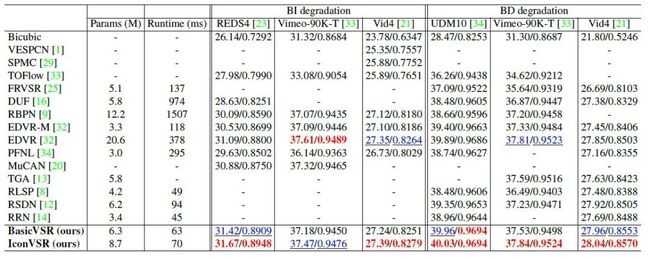
我们在四个数据集上,两个退化上测试BasicVSR和IconVSR。我们看到,没有复杂的模槐,BasicVSR就已经可以在多个数据集上胜过现有技术。借助我们提出的部件,IconVSR可以进一步提高性能,并在大多数数据集上实现最先进的性能。以下结果表明,BasicVSR和IconVSR通过利用长期信息成功地重建了细节。

结语
通过分解和分析现有元素,我们提出了BasicVSR,这是一个简单而有效的网络,可以高效地胜过现有技术。我们提出了两个新颖的组件来进一步提高性能。BasicVSR和IconVSR可以作为将来工作的牢固基线。
作者介绍:
陈焯杰 (Kelvin C.K. Chan) | 南洋理工大学S-Lab和MMLab@NTU三年级博士生。在顶级会议上发表过五篇论文,在NTIRE视频复原比赛中共获得六个冠军。导师是吕健勤(Chen Change Loy)副教授。当前主要研究兴趣为图像和视频复原,主要包括超分辨率和去模糊等。
个人主页:ckkelvinchan.github.io/
实验室主页:mmlab-ntu.github.io
References
[1] Tian, Yapeng, et al. "TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[2] Wang, Xintao, et al. "EDVR: Video Restoration with Enhanced Deformable Convolutional Networks." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2019.
[3] Xue, Tianfan, et al. "Video Enhancement with Task-Oriented Flow." International Journal of Computer Vision 127.8 (2019): 1106-1125.
[4] Huang, Yan, Wei Wang, and Liang Wang. "Video Super-Resolution via Bidirectional Recurrent Convolutional Networks." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 1015-1028.
[5] Isobe, Takashi, et al. "Video Super-Resolution with Recurrent Structure-Detail Network." European Conference on Computer Vision. Springer, Cham, 2020.
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-超分辨率交流群成立
扫码添加CVer助手,可申请加入CVer-超分辨率 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如超分辨率+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看