Kubernetes Pod调度策略

Kubernetes Scheduler
上图是k8s的整体架构图,整体上可分为两大部分,组成集群控制器的服务(图左)与运行在工作节点的服务(图右)。运行在工作节点的服务自不必说,控制器相关的模块主要包括:
etcd保存了整个集群的状态;apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
而我们这次关注的,就是scheduler调度器,了解其如何监听新创建、尚未分配到计算节点的Pod,如何为每一个Pod找到最适合其运行的计算节点。调度器的工作听起来很简单,里面的细节问题却是不少,比如,如何保证调度的公平性,确保每个节点都能被分配资源;再比如,如何保证调度的性能,最大化的利用集群的资源,最快的完成调度工作;以及如何允许用户灵活的自定义一些调度需求。k8s的调度器在默认设置下使用的是自带的kube-scheduler,在需要的场景下,我们也可以自定义调度器给k8s使用。如果没有特殊说明,接下来描述的都是kube-scheduler的调度行为。
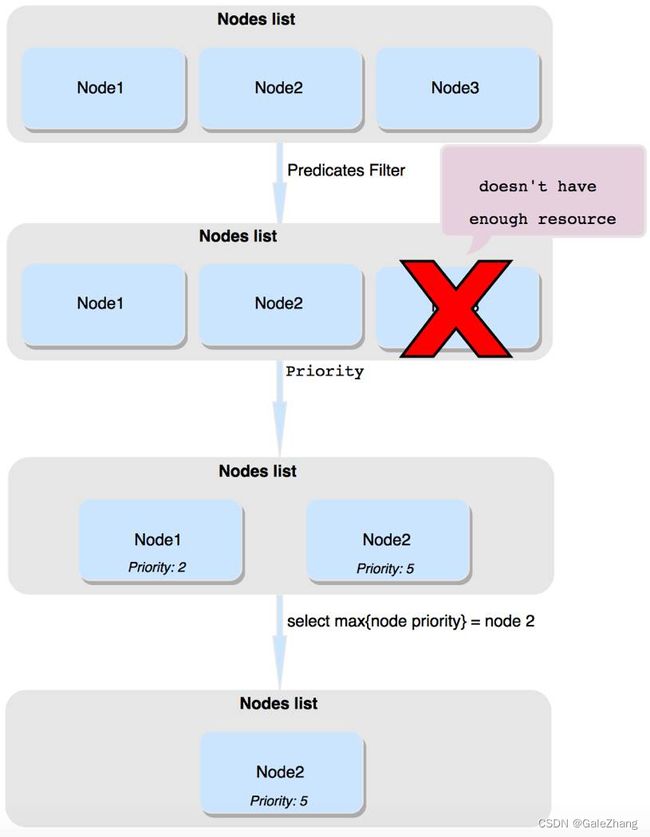
调度器是作为一个独立的服务运行的,在其启动后,其会一直监听apiserver。当调度器发现一个新创建的Pod后,首先要做的就是在当前的节点中,筛选出符合调度条件的节点,这类节点我们称之为Feasible Node,如果没有节点符合条件,那么pod会一直停留在 unscheduled 状态,直到有节点符合条件。这一步筛选的过程叫做predicate。在筛选出Feasible Node后,第二步就是从中选择出最优的节点,为了评价节点的优先级,我们会对所有的Feasible Node进行打分,这一步称之为Priority,如果有多个节点有相同的最高优先级,会从中随机选择一个。最后,我们将选出的最优先节点上报给apiserver,这个过程叫做binding。
有两种方式配置调度器的筛选和打分行为,分别是调度策略和调度配置。
调度策略
调度策略可以指定筛选阶段的断言predicates和打分阶段的优先级priorities。
断言
这一个阶段主要是解决Pod能不能去某个Node的问题,通过各种断言条件,过滤掉不能去的节点。
PodFitsHostPorts
检查 Pod 请求的端口(网络协议类型)在节点上是否可用。
PodFitsHost
检查 Pod 是否通过主机名指定了 Node。
PodFitsResources
检查节点的空闲资源(例如,CPU和内存)是否满足 Pod 的要求。
MatchNodeSelector
检查 Pod 的节点选择算符 和节点的 标签 是否匹配。
以上四种断言,又被合称为GeneralPredicates,主要包含一些基本的筛选规则,考虑 Kubernetes 资源是否充足,比如 CPU 和 内存 是否足够,端口是否冲突、selector 是否匹配等。前三种自不必说,第四种NodeSelector则是一种比较直白的调度方式,通过在配置文件中指定Pod要调度的Node,该匹配规则属于【强制】约束。由于是调度器调度,因此不能越过Taints污点进行调度。
NoVolumeZoneConflict
给定该存储的故障区域限制, 评估 Pod 请求的卷在节点上是否可用。
NoDiskConflict
根据 Pod 请求的卷是否在节点上已经挂载,评估 Pod 和节点是否匹配。
MaxCSIVolumeCount
决定附加 CSI 卷的数量,判断是否超过配置的限制。
CheckNodeMemoryPressure
如果节点正上报内存压力,并且没有异常配置,则不会把 Pod 调度到此节点上。
CheckNodePIDPressure
如果节点正上报进程 ID 稀缺,并且没有异常配置,则不会把 Pod 调度到此节点上。
CheckNodeDiskPressure
如果节点正上报存储压力(文件系统已满或几乎已满),并且没有异常配置,则不会把 Pod 调度到此节点上。
CheckNodeCondition
节点可用上报自己的文件系统已满,网络不可用或者 kubelet 尚未准备好运行 Pod。 如果节点上设置了这样的状况,并且没有异常配置,则不会把 Pod 调度到此节点上。
PodToleratesNodeTaints
检查 Pod 的容忍 是否能容忍节点的污点。
CheckVolumeBinding
基于 Pod 的卷请求,评估 Pod 是否适合节点,这里的卷包括绑定的和未绑定的 PVCs 都适用。
优先级
SelectorSpreadPriority
属于同一 Service、 StatefulSet 或 ReplicaSet 的 Pod,跨主机部署。
InterPodAffinityPriority
实现了 Pod 间亲和性与反亲和性的优先级。
LeastRequestedPriority
偏向最少请求资源的节点。 换句话说,节点上的 Pod 越多,使用的资源就越多,此策略给出的排名就越低。
MostRequestedPriority
支持最多请求资源的节点。 该策略将 Pod 调度到整体工作负载所需的最少的一组节点上。
RequestedToCapacityRatioPriority
使用默认的打分方法模型,创建基于 ResourceAllocationPriority 的 requestedToCapacity。
BalancedResourceAllocation
偏向平衡资源使用的节点。
NodePreferAvoidPodsPriority
根据节点的注解 scheduler.alpha.kubernetes.io/preferAvoidPods 对节点进行优先级排序。 你可以使用它来暗示两个不同的 Pod 不应在同一节点上运行。
NodeAffinityPriority
根据节点亲和中 PreferredDuringSchedulingIgnoredDuringExecution 字段对节点进行优先级排序。 你可以在将 Pod 分配给节点中了解更多。
TaintTolerationPriority
根据节点上无法忍受的污点数量,给所有节点进行优先级排序。 此策略会根据排序结果调整节点的等级。
ImageLocalityPriority
偏向已在本地缓存 Pod 所需容器镜像的节点。
ServiceSpreadingPriority
对于给定的 Service,此策略旨在确保该 Service 关联的 Pod 在不同的节点上运行。 它偏向把 Pod 调度到没有该服务的节点。 整体来看,Service 对于单个节点故障变得更具弹性。
EqualPriority
给予所有节点相等的权重。
EvenPodsSpreadPriority
实现了 Pod 拓扑扩展约束的优先级排序。
调度配置
这里的调度配置是指调度器的配置,上一节中的调度策略,主要是对调度策略中的一些参数的配置,而调度器配置则是对调度器本身的一些配置,影响的是调度器在各个阶段的行为。调度器的行为发生在一系列阶段之中,这些阶段是通过一系列拓展点公开的,调度器有如下扩展点(或者说阶段):
-
QueueSort:这些插件对调度队列中的悬决的 Pod 排序。 一次只能启用一个队列排序插件。 -
PreFilter:这些插件用于在过滤之前预处理或检查 Pod 或集群的信息。 它们可以将 Pod 标记为不可调度。 -
Filter:这些插件相当于调度策略中的断言(Predicates),用于过滤不能运行 Pod 的节点。 过滤器的调用顺序是可配置的。 如果没有一个节点通过所有过滤器的筛选,Pod 将会被标记为不可调度。 -
PreScore:这是一个信息扩展点,可用于预打分工作。 -
Score:这些插件给通过筛选阶段的节点打分。调度器会选择得分最高的节点。 -
Reserve:这是一个信息扩展点,当资源已经预留给 Pod 时,会通知插件。 这些插件还实现了Unreserve接口,在Reserve期间或之后出现故障时调用。 -
Permit:这些插件可以阻止或延迟 Pod 绑定。 -
PreBind:这些插件在 Pod 绑定节点之前执行。 -
Bind:这个插件将 Pod 与节点绑定。绑定插件是按顺序调用的,只要有一个插件完成了绑定,其余插件都会跳过。绑定插件至少需要一个。 -
PostBind:这是一个信息扩展点,在 Pod 绑定了节点之后调用。
对于每一个扩展点,都可以启用kube-scheduler的默认插件,或者启用自己的自定义插件,实际上,一旦对扩展点进行了定制,实际上就是对调度器的修改,这时所使用的调度器也不再是默认的kube-scheduler了,而是个人定制化的调度器。
总结
通过指定调度策略与调度配置,调度器的调度方式从结果上来看可以分为三类。
第一种是定向调度,通过NodeName和NodeSelector强制指定要调度的节点,直接建立Pod与Node的绑定关系,这种调度方式实际上不需要调度器的过多参与。在实现方式上,则是通过指定断言阶段的相关配置来实现。
第二种是亲和性调度,通过亲和性设置,实际上是解决了Pod想去哪里的问题。比如说预判业务场景中的访问可能大多来自于上海,则可将Pod对上海地域的Node的亲和性进行设置。比如说想要做异地容灾,同一个应用的不同Pod要尽可能的分配在不同的Node上,那么就可以设置Pod对同app名的Pod的反亲和性,来避免绑定在相同Node。在实现方式上,则是通过指定nodeaffinity、podaffinity、podantiaffinity的相关配置来实现。
第三种是污点(容忍)调度,被打上污点Taints的Node,默认是不接受调度的,除非Pod的Toleration指明了容忍该污点。换言之,Node可以通过指定污点,来拒绝Pod的绑定,Node可以对Pod说不,这解决了Pod能去哪里的问题。通过这种污点及容忍的定制化配置,我们可以在集群内实现资源的隔离,比如某些应用需要放置在孤立的资源中,不与其他应用共享资源,就可以通过这种方式实现。在实现方式上,则是通过指定Taints、toleration的相关配置来实现。
参考文献:kubernetes中文文档