Spark 指定分区数、文件并行读写、Spark IO读写常用处理方法
一、小文件管理 之指定分区数
1、配置 spark.sql.shuffle.partitions,适用场景spark.sql()合并分区
spark.conf.set("spark.sql.shuffle.partitions", 5) #后面的数字是你希望的分区数这样配置后,通过spark.sql()执行后写出的数据分区数就是你要求的个数,如这里5。
2、配置 coalesce(n),适用场景spark写出数据到指定路径下合并分区,不会引起shuffle
df = spark.sql(sql_string).coalesce(1) #合并分区数
df.write.format("csv")
.mode("overwrite")
.option("sep", ",")
.option("header", True)
.save(hdfs_path)3、配置repartition(n), 重新分区,会引发shuffle
df = spark.sql(sql_string).repartition(1) #重新分区,会引发全局shuffle
df.write.format("csv")
.mode("overwrite")
.option("sep", ",")
.option("header", True)
.save(hdfs_path)二、文件的并行读取和写出
1、并行写出之 partitionBy() 指定分区列 , 会根据分区列创建子文件夹,并行写出数据
df.write.mode("overwrite")
.partitionBy("day")
.save("/tmp/partitioned-files.parquet")2、并行写出之 repartition() ,一般spark中有几个分区就会有几个并行的IO写出
df.repartition(5)
.write.format("csv")
.save("/tmp/multiple.csv")3、分桶写出,好处是后续读入的时候数据就不会做shuffle了,因为相同分桶的数据会被划分到同一个物理分区中
csvFile.write.format("parquet")
.mode("overwrite")
.bucketBy(5, "gmv") #第一个参数:分成几个桶,第二个参数:按哪列进行分桶
.saveAsTable("bucketedFiles")
三、Spark IO
参考:Spark官方API文档Input and Output
1、DataFrame调用.read/write.format() API文件写入-覆盖和追加
(1)spark.read.format() 对文件进行读取的通用代码格式
spark.read.format('csv') #说明文件格式是CSV还是JSON还是TEXT等
.option("mode", "FAILFAST") #读取遇到格式错误时怎么处理
.option("inferSchema", "true") #option中("Key","value") 形式配置参数
.option("path", "path/to/file(s)")
.schema(someSchema)
.load()
#读取遇到格式错误时处理选项参数:
'''
permissive :将损坏的数据记录成null, 并将损坏的列命名为 _corrupt_record 标记出来
dropMalformed :删掉损坏的数据
failFast:报错失败
'''(2)df.write.format() 将DataFrame中数据写入到文件的通用代码格式
#抽象的DF写出代码格式
DataFrameWrite.format(...)
.option(...)
.partitionBy(...)
.bucketBy(...)
.sortBy(...)
.save()
#一个具体的DF写出的代码格式
df.write.format("csv")
.option("mode", "OVERWRITE") #覆盖还是追加数据
.option("sep",",") #分隔符
.option("header",true) #第一行是否是列名
.option("inferSchema",true) #是否自动推断列类型
.option("dateFormat", "yyyy-MM-dd") #日期数据的格式
.option("timestampFormat","yyyy-MMdd’T’HH:mm:ss.SSSZZ") #时间戳数据的格式
.option("nullValue","null") #数据中的null值用什么表示,默认是“”,也可以设置成NA或NULL
.option("nanValue","unknown") #数据中的NaN或缺失值用什么表示,默认是"NaN",也可以设置成其他
.option("positiveInf","Inf") #正无穷怎么表示
.option("negativeInf","-Inf") #负无穷怎么表示
.option("compression","gzip") #压缩方式,uncompressed、snappy、lz4等
.option("path", "path/to/file(s)") #保存地址
.save()
'''
写出 mode可选参数有:
append 在写出路径下追加数据文件
overwrite 覆盖写出路径下的所有文件
errorIfExists 如果在写出路径下已经有数据了,则报错误并失败掉任务
ignore 如果在写出路径下有数据或文件,不做任何处理,即忽略这个数据的写出,直接跳过
'''(3)spark.read.format()、df.write.format() 的应用举例
#DataFrame调用write.format API
#spark读取
df = spark.read.format('json').load('python/test_support/sql/people.json')
#df覆盖写入,mode("overwrite")
df.write.format("csv").mode("overwrite").option("sep", ",").option("header", True).save(hdfs_path)
#df追加写入,mode("append")
df.write.format("csv").mode("append").option("sep", ",").option("header", True).save(hdfs_path)2、DataFrame调用 .write.csv(/parquet/orc) API读取写出文件
(1)spark.read.{文件类型} 读取文件的通用代码格式
#1、spark.read.csv()
spark.read.csv(path='foo.csv', mode='failfast' ,header=True).show()
#2、spark.read.parquet()
df.write.parquet('bar.parquet')
#3、spark.read.orc()
spark.read.orc('zoo.orc').show()
(2)df.write.{文件类型} 将DataFrame中数据写入到文件的通用代码格式
#1、df读写csv
df.write.csv('foo.csv', header=True)
#2、df读写parquet
df.write.parquet('bar.parquet')
#3、df读写ORC
df.write.orc('zoo.orc')
#4、覆盖写入
df.write.csv(path, mode='overwrite',sep=',',header=True)
#5、追加写入
df.write.csv(path, mode='append',sep=',',header=True)注意: 不管是用format()的方式,把文件类型写在format的里面作为参数,还是用调用文件类型的读写,它们在option配置选项上是通用的。
3、textFile读写
(1)spark.read.textFile() 和 spark.read.wholeTextFile()
#spark.read.textFile() 会忽略读入文件的分区
spark.read.textFile("/data/flight-data/csv/2010-summary.csv")
.selectExpr("split(value, ',') as rows").show()
#spark.read.text() 会保留读入文件的分区
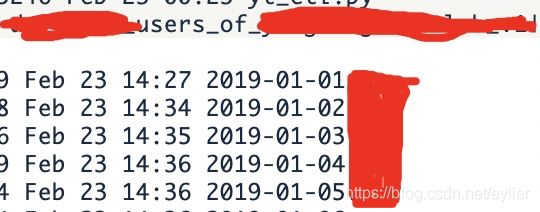
'''
如果有一个目录,下面按日期分了多个子目录,每个目录下存放着日期当天的一些数据,
是否用spark.read.text()读取目录就能获取日期分区呢?
'''
(2)df.write.text() 写出只能有一列
当写出的不是一列的时候,否则会报错。
df.select("A_COLUMN_NAME").write.text("/tmp/simple-text-file.txt")
但如果其他列作为分区的话,是可以选择多列的。但作为分区的列是作为分区的子路径文件名存在的,并不是输出的多列,输出还是只有一列。
#指定一个分区列,文件中输出的还是只有一列
df.select("A_COLUMN_NAME", "count")\
.write.partitionBy("count").text("/tmp/five-csv-files2py.csv")如果先用concat_ws(',',col1,col2) as col 把要输出的列进行了连接,然后再按照要分区的列(比如日期)来目录写出,岂不是很实用?
#链接要输出的列,并按照日期列分区写出
df.select("concat_ws(',',col1,col2) as col", "day")
.write.partitionBy("day")
.text("/tmp/five-csv-files2py.csv")