postgreSQL源码分析——索引的建立与使用——GIST索引(1)
2021SC@SDUSC
这一篇博客主要讲解GIST索引的相关的介绍,组织结构以及原理的讲解。
目录
- GIST 简介
-
- 介绍
- 扩展性
- 实现
-
- typedef struct GISTSTATE
- GIST的索引结构
- GIST相关数据结构
-
- typedef struct GISTPageOpaqueData
- typedef struct GIST_SPLITVEC
- typedef struct GISTBuildBuffers
GIST 简介
介绍
Gist是generalized search tree的缩写,是一棵平衡的搜索树,和之前介绍的btree类似。但是它和btree不同的是,btree索引常常用来进行例如大于、小于、等于这些操作中,而在实际生活中很多数据其实不适用这种场景,例如地理数据、图像等等。因为Gist索引允许定义规则来将任意类型的数据分布到一个平衡的树中,并且允许定义一个方法使用此表示形式来让某些运算符访问。例如,对于空间数据,GiST索引可以使用 R树,以支持相对位置运算符(位于左侧,右侧,包含等),而对于树形图,R树可以支持相交或包含运算符。GiST 的一个优点是它允许一种自定义的数据类型和合适的访问方法一起开发,并且是由该数据类型范畴里的专家,而不是数据库专家开发。
扩展性
通常,实现一种新的索引访问方法意味着大量的艰苦工作。必须理解数据库的内部工作机制,比如锁的机制和预写日志。GiST 接口有一个高层的抽像,只要求访问方法的实现者实现被访问的数据类型的语意。GiST 层本身会处理并发,日志和搜索树结构的任务。
所以,如果你用PostgreSQL B-tree 索引了一个图像集,那么你就只能发出类似"图像 x 和图像 y 相等吗"、“图像 x 是不是比图像 y 小”、“图像 x 是否大于图像 y”?这样的查询。根据你在这个环境下定义的"等于"、“小于”、“大于"的含义,上面这些查询可能有意义。但是,使用一个基于 GiST 的索引,你可以创建一些方法来发出和域相关的问题,比如"找出所有马的图像"或者"找出所有曝光过头的图像”。
实现
GiST自身只是一个框架,针对不同的数据类型和算法逻辑需要额外实现特定的数据语义。由于GiST屏蔽了数据库的内部工作机制,比如锁的机制和预写日志。所以实现新的GiST索引实例(或称作索引操作符类)的工作相对比较轻松,基于GiST架构的索引操作符类只需提供下面7个方法的实现
consistent
给出一个在树的数据页上的谓词 p 和一个用户查询 q ,如果对于一个给定的数据项,p 和 q 都很明确地不能为真,那么这个方法将返回假。
union
这个方法合并树中的信息。给出一个条目的集合,这个函数生成一个新的谓词,这个谓词对所有这些条目都为真。
compress
将数据项转换成一个适合于在一个索引页里面物理存储的格式。
decompress
compress 方法的反方法。把一个数据项的索引表现形式转换成可以由数据库操作的格式。
penalty
返回一个表示将新条目插入树中特定分支需要的"开销"的数值。项将会按照树中最小 penalty 的路径插下去。
picksplit
如果需要分裂一个页面的时候,这个函数决定页面中哪些条目保存呆旧页面里,而哪些移动到新页面里。
same
如果两个条目相同,返回真,否则返回假。
typedef struct GISTSTATE
与实现密切相关的数据结构如下,它是任何GIST索引操作所需要的信息
typedef struct GISTSTATE
{
MemoryContext scanCxt; /*索引的元组描述符 */
MemoryContext tempCxt; /*函数调用的短期上下文 */
TupleDesc leafTupdesc; /* 叶子节点的截断的元组描述符 */
TupleDesc nonLeafTupdesc; /* 非叶子节点的截断的元组描述符 */
TupleDesc fetchTupdesc; /* 唯一扫描索引 */
FmgrInfo consistentFn[INDEX_MAX_KEYS];//与七个方法的实现有关
FmgrInfo unionFn[INDEX_MAX_KEYS];
FmgrInfo compressFn[INDEX_MAX_KEYS];
FmgrInfo decompressFn[INDEX_MAX_KEYS];
FmgrInfo penaltyFn[INDEX_MAX_KEYS];
FmgrInfo picksplitFn[INDEX_MAX_KEYS];
FmgrInfo equalFn[INDEX_MAX_KEYS];
FmgrInfo distanceFn[INDEX_MAX_KEYS];
FmgrInfo fetchFn[INDEX_MAX_KEYS];
/* Collations to pass to the support functions */
Oid supportCollation[INDEX_MAX_KEYS];
} GISTSTATE;
GIST的索引结构
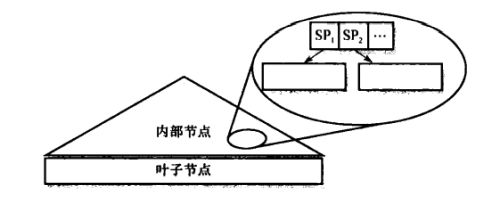
GIST是一颗平衡树,索引项形式为(p, ptr),p是搜索的谓词。在叶子节点中,ptr为指向数据库某元组的指针,在非叶子节点中,ptr为指向子树节点的指针,如下图所示:其中SP1,SP2是用来分割数据的谓词,可以看出GIST与BTree树有很多相似的地方,我理解的就是GIST用来分割的不是具体可以比较大小的数据,而是用户需要自定义的谓词。postgresql则实现了索引项的创建,查找删除等操作,用户需要做的是定义上文中提到的7种方法。
GIST相关数据结构
在gist.h以及gist_private.h定义了关于GIST索引相关的数据结构,我们找出几个重要的来看
typedef struct GISTPageOpaqueData
该结构体与GIST存放页面相关
typedef struct GISTPageOpaqueData
{
PageGistNSN nsn; /* GIST独有的数据类型,在分裂时需要变化 */
BlockNumber rightlink; /*指向下一页的指正 */
uint16 flags; /*位定义 */
uint16 gist_page_id; /* 判定gist的页号 */
} GISTPageOpaqueData;
typedef struct GIST_SPLITVEC
该结构体与GIST分裂有关
typedef struct GIST_SPLITVEC
{
OffsetNumber *spl_left; /* 向左条目的数量*/
int spl_nleft; /* 数组大小*/
Datum spl_ldatum; /* 左侧数目键值的合并 */
bool spl_ldatum_exists; /* 如果spl_ldatum存在为真 */
OffsetNumber *spl_right; /*向右的条目的数量 */
int spl_nright; /* 数组大小*/
Datum spl_rdatum; /* 左侧数目键值的合并*/
bool spl_rdatum_exists; /* 如果spl_rdatum存在为真*/
} GIST_SPLITVEC;
typedef struct GISTBuildBuffers
该结构体与构建GIST缓冲区有关
typedef struct GISTBuildBuffers
{
/* 缓冲区和元页的上下文*/
MemoryContext context;
BufFile *pfile; /*存储缓冲区的临时文件 */
long nFileBlocks; /* 临时文件的当前大小 */
/*
可调整的空闲块数组
*/
long *freeBlocks;
int nFreeBlocks; /* 空闲块数量 */
int freeBlocksLen; /*数组当前分配的长度 */
/* 按照块号对缓冲区进行HASH*/
HTAB *nodeBuffersTab;
/* 空缓冲区的列表 */
List *bufferEmptyingQueue;
int levelStep;
int pagesPerBuffer;
/* 每个级别上的缓冲区列表,用于最后清空*/
List **buffersOnLevels;
int buffersOnLevelsLen;
GISTNodeBuffer **loadedBuffers;
int loadedBuffersCount; /* loadedBuffer中的数量*/
int loadedBuffersLen; /* loadedBuffer分配产固定 */
/* 根节点的级别 */
int rootlevel;//索引树的高度减一
} GISTBuildBuffers;
以上就是GIST的基本算法原理,以及其相关的索引组织结构和数据结构,可见GIST的可扩展性很强,满足用户搜寻查找的不同需求。下一篇博客我们讲解关于GIST的创建函数。