算能BM1684X部署手写数字识别模型
大致流程---------------------------------------------------------------

参考《sophon-sail_zh》
移植步骤------------------------------------------------------------------------
首先搭建好自己的网络模型,并导出为onnx格式--具体可以参照-->
GitHub - warren-wzw/MNIST-pytorch
- 将onnx模型使用tpu-mlir工具转化为bmodel格式--具体可以参照---> https://kdocs.cn/l/cdwzqT3Hbyje
拷贝至板端:scp test_output_fp* [email protected]:/data
远程连接另一台linux--->ssh -p 22 [email protected]6
- 在板端搭建好sophon-sail环境----> https://kdocs.cn/l/ce7T9GNtS3D3
python版----------------------------------------------------------------------------------------
在板端新建一个MNIST文件夹,文件目录如下,其中datasets存放测试数据集train-images-idx3-ubyte,test_output_fp16_1b.bmodel以及test_output_fp32_1b.bmodel为onnx转化后的bmodel模型,test.py为测试代码。

- 主要的原理就是使用sophon提供的api加载能够适配于BM1684X的bmodel类型的模型,并使用他们的api进行模型的推理,官方sail的API可以参考-->
3. API 参考 — sophon-sail v23.03.01 文档
- 下面讲解一下测试代码
#import cv2
import numpy as np
import sophon.sail as sail
import time
num = -1
inference_time =[0]
print("--0-5 1-0 2-4 3-1 4-9 5-2 6-1 7-3 8-1 9-4 for example:if num =9 the pic's num is 4")
engine = sail.Engine("./test_output_fp32_1b.bmodel",0,sail.IOMode.SYSIO) #load model-use FP32model on tpu-0 and use sys memery
#engine = sail.Engine("./test_output_fp16_1b.bmodel",0,sail.IOMode.SYSIO) #load model-use FP16 on tpu-0 and use sys memery
graph_name =engine.get_graph_names()[0] #get_graph_names-test_output
input_tensor_name = engine.get_input_names(graph_name)[0] #get_input_names-input.1
output_tensor_name = engine.get_output_names(graph_name)[0] #get_output_names-25_LogSoftmax
batchsize,channel,height,width = engine.get_input_shape(graph_name,input_tensor_name) #get batchsize-1,channel-1,input image's height-28 & width-28
#read image
with open("./datasets/train-images-idx3-ubyte","rb") as f:
file = f.read()
for i in range(8000):
num =num +1
i = 16+784*num
image1 = [int(str(item).encode('ascii'),16) for item in file[i:i+784]]
#reshap input data
input_data = np.array(image1,dtype=np.float32).reshape(1,1,28,28) #reshape the image to 1 1 28 28
input_data_final = {input_tensor_name:input_data} #because the process's parmeter(input_data) must be dictionary so use{}
start_time = time.time()
outputs = engine.process(graph_name,input_data_final) #model inference
end_time = time.time()
inference_time.append(end_time - start_time)
result = outputs[output_tensor_name] #use output_tensor_name to get the tensor
max_value=np.argmax(result) #get the index of the best score
print("----------------------------------the result is ",max_value,"the time is ",inference_time[num]*1000,"ms")
mean = (sum(inference_time) / len(inference_time))*1000
print("-----FP32--","loop ",num+1,"times","average time",mean,"ms")
- 测试结果
FP32

FP16

基本稳定在4%峰值可达8%

C++版本---------------------------------------------------------------------------------------------------------
首先安装好c++交叉编译环境
--> https://kdocs.cn/l/cbe77SdEwLKm
1:采用交叉编译的方式进行编译,新建文件夹MNIST
文件结构
![]()
CMakeFile.txt
main.cpp
#define USE_FFMPEG 1
#define USE_OPENCV 1
#define USE_BMCV 1
#include
#include
#include
#include
#include
#include
#include "spdlog/spdlog.h"
#include "spdlog/fmt/fmt.h"
#include "engine.h"
using namespace std;
using namespace sail;
const std::string& bmodel_path_fp32="./test_output_fp32_1b.bmodel";
const std::string& bmodel_path_fp16="./test_output_fp16_1b.bmodel";
const int MODEL_IN_WIDTH = 28;
const int MODEL_IN_HEIGHT = 28;
const int MODEL_CHANNEL = 1;
const int loop_count = 1000;
int num = -1;
static inline int64_t getCurrentTimeUs()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void Load_data(int num,unsigned char * input_image)
{
int j=16+784*num;
FILE *file = fopen("./datasets/train-images-idx3-ubyte", "rb");
if (file == NULL) {
printf("can't open the file!\n");
}
fseek(file,j,SEEK_SET);
fread(input_image,sizeof(char),784,file);
/* for(int i=0;ibuffer[j+1]){
temp = buffer[j];
buffer[j]=buffer[j+1];
buffer[j+1]=temp;
}
}
}
}
void dump_shape(std::vector shape)
{
cout<<"[ ";
for (const int& value : shape) {
std::cout << value << " ";
}
cout<<"]"< input_shape = {1, 1, 28, 28};
std::map> input_shapes;
input_shapes[input_name] = input_shape;
auto output_shape = engine.get_output_shape(graph_name, output_name);
auto input_dtype = engine.get_input_dtype (graph_name, input_name);
auto output_dtype = engine.get_output_dtype(graph_name, output_name);
cout<<"----------------graph_name is "< input_tensors = {{input_name, &in}};
std::map output_tensors = {{output_name, &out}};
// prepare input and output data in system memory with data type of float32
float* input = nullptr;
float* output = nullptr;
int in_size = std::accumulate(input_shape.begin(), input_shape.end(),
1, std::multiplies());
int out_size = std::accumulate(output_shape.begin(), output_shape.end(),
1, std::multiplies());
if (input_dtype == BM_FLOAT32) {
input = reinterpret_cast(in.sys_data());
}
else {
input = new float[in_size];
}
if (output_dtype == BM_FLOAT32) {
output = reinterpret_cast(out.sys_data());
}
else {
output = new float[out_size];
}
//loop
for(int times=0;times(out.sys_data());
for(int i = 0; i < 10;i++){
buffer_copy[i]=output_data[i];
//printf("output_data is %f \n",output_data[i]);
}
Bubble_sort(output_data,10);
for(int i =0;i<10;i++){
if(buffer_copy[i]==output_data[9]){
printf("------------------------------------------the pic value is %d \n",i);
}
}
/* cout<<"real_output_shape is "<<"[ ";
dump_shape(real_output_shape);*/
printf(": Elapse Time = %.3f ms \n", time[times] / 1000.f);
}
printf("--------loop %d times sum is %.4f ms average time is %.3f ms\n", loop_count,sum / 1000.f,(sum / 1000.f)/loop_count);
return true;
}
int main()
{
int device_id = 0;
int tpu_num=get_available_tpu_num();
printf("the tpu number is %d\n", tpu_num);
bool status = inference(device_id);
return 0;
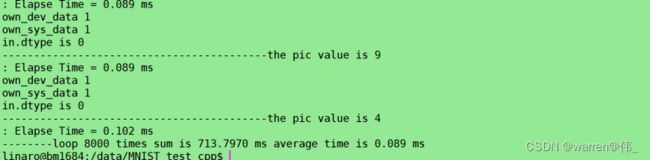
} 打印结果


fp32

fp16

int8
bm-smi
基本稳定在2%,峰值为4
