mysql数据库
一.基本语句:
a)库操作:
1.创建数据库:create database [if (not) exists] 数据库名 charset utf8(或者character set utf8);
[]中的语句表示如果存在,就不执行,也不会报错,如果不加,会报错(停止执行).
注意:mysql中utf8是残血的(少了一些emoji表情),utf8mb4是满血的.
2.查看所有数据库:show databases;
3.选择指定数据库:use 数据库名;
4.删除数据库:drop database [if (not) exists] 数据库名;
b)表操作:
1.创建表:create table [if (not) exists] 表名(列名 类型 [属性],......);
类型:
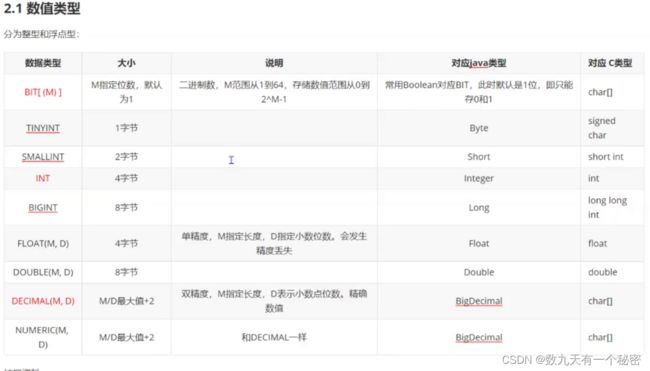


2.查看该数据库的所有表:show tables;
3.查看指定的表结构:desc 表名;
4.删除表:drop table [if (not) exists] 表名;
5.comment是注释,只能在创建表的时候专属使用,不建议使用.
6.注释建议使用#或者--.
C)增删改查(CRUD):
1.新增:insert into 表名 [(列名, 列名......)] values (值, 值......), (值, 值......)......;
注意:sql中字符串使用单引号和双引号都行(没有字符,只有字符串),Python,Js,Php,Linux,Shell也这样.
2.全列查询:select * from 表名;
3.指定列查询:select 列名, 列名...... from 表名;
4.表达式查询:select 表达式 [as 重命名] from 表名;
5.去重查询:select distinct 列名 from 表名;(注意:对查询到的结果进行去重)
6.排序查询:select 列名 from 表名 order by 列名 [asc(升序,默认) / desc(降序)], 列名 [asc(升序,默认) / desc(降序)]......;
7.条件查询:select 列名 [as 别名] from 表名 where 条件;(注意,where后面不能使用前面起的别名)


注意:多使用()手动确立优先级.
8.分页查询:select 列名 from 表名 limit (一页n个数据) offset (从第n个数据开始);
9.修改数据:update 表名 set 修改内容 where 条件;
注意:可以搭配order by 以及 limit 使用.
10.删除数据:delete from 表名 where 条件;
注意:此处删除的是行,如果需要删除列,不要使用alter table操作,而是使用update操作把列置成null.
可以搭配order by 以及 limit 使用.
二.数据库约束:
1.约束类型:

注意:check约束mysql不支持.
2.自增主键:使用关键字auto_increment.
注意:必须是整数类型的主键,自动分配主键id(自增),插入数据的时候,主键列插入null(也可以手动指定,类似枚举).
分布式id生产算法核心思路:把id作为一个字符串,由以下三部分组成a)主机编号/机房编号.b)时间戳.c)随机因子.
3.foreign key(外键):foreign key(非主键列) references 表名(带索引的列).
注意:后面是父表,约束建立外键的表(是指定列受到约束),约束往往是双向的.
a)插入或者修改子表中受约束的列的数据,需要保证在父表中存在.
b)删除或修改父表中的记录,要看子表是否使用,如果使用了,则不能删除或修改.
4.商品下架:不要把数据删除,而是设置一个标记位,标记上架/下架.
三.进阶查询:
a)查询新增(把查询到的数据插入到一个表中):insert into 表名[(列名, 列名......)] select ......;
b)聚合查询:
1.聚合函数:

2.分组查询:select 列名1, 聚合函数(列名2) from 表名 group by 列名1;
注意:分组查询中,select 指定的列,必须是当前group by指定的列,否则必须放到聚合函数中,不然没有意义.
3.分组之前的条件用where.
4.分组之后的条件用having.
注意:having之后的条件搭配聚合函数使用.
c)多表查询(克制使用):
1.等值连接:select from 表名a, 表名b where a.列名1 = b.列名2;
2.内连接:select 列名 from 表名A [as 别名a] [inner] join 表名B [as 别名b] on 条件;
注意:此处的条件可以使用表的别名.
3.外连接:select 列名 from 表名A left/right join 表名B on 条件;
注意:全外连接(outer join)mysql不支持.
4.自连接(极少用,特殊场景):select from 表A as a1, 表B as a2 where a1.列名1 = a2.列名1;
本质上:把行和行之间的关系转换成列和列的关系.
5.子查询(极力克制使用):条件中使用select语句,相当于套娃.
6.合并查询(把多个select查询的结果集合并成一个):select ...... union select ......;
注意:两个select结果集要对应.
union all:不去重.
四:索引(index)
1.优点:提高查询效率.
2.缺点:
a)消耗额外空间.
b)拖慢增删改的速度.
新增:不光要在表里插入数据,还有修改索引.
修改和删除:如果涉及到索引,需要同时修改索引.
3.查看索引:show index from 表名;
4.创建索引:create index 索引名 on 表名(字段名);
主键,外键,unique自动创建索引.
注意: 这个操作很危险,如果表为空,那没事,如果表中数据很多,这个操作会涉及大规模硬盘io操作.
5.删除索引:drop index 索引名 on 表名;
注意:只能删除手动添加的索引,自动生成的索引不能被删除.
这个操作也很危险.
五:索引数据结构
mysql索引的数据结构(Innodb)
六:事务
mysql事务处理
七.JDBC
JDBC编程