Python之音频信号处理(一)音频基础知识
文章目录
- 一、音频基础知识
-
- 1、声音的三要素
- 2、音频的量化与编码
- 3、音频压缩技术
- 二、音频信号的读写
-
- 1、python读取.wav音频
- 2、python写.wav音频文件
一、音频基础知识
1、声音的三要素
(1)音调
人耳对声音高低的感觉称为音调(也叫音频)。音调主要与声波的频率有关。声波的频率高,则音调也高。一般音频 儿童>女生>男生。
人耳听觉音频范围是20Hz-20000Hz(做音频压缩时不在这个范围内的数据就可以砍掉)。
(2)音量
也就是响度。人耳对声音强弱的主观感觉称为响度。响度和声波振动的幅度有关。一般说来,声波振动幅度越大则响度也越大。
人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。
(3)音色
也就是音品。音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。音色与声波的振动波形有关,或者说与声音的频谱结构有关。
2、音频的量化与编码
(1)音频的量化过程
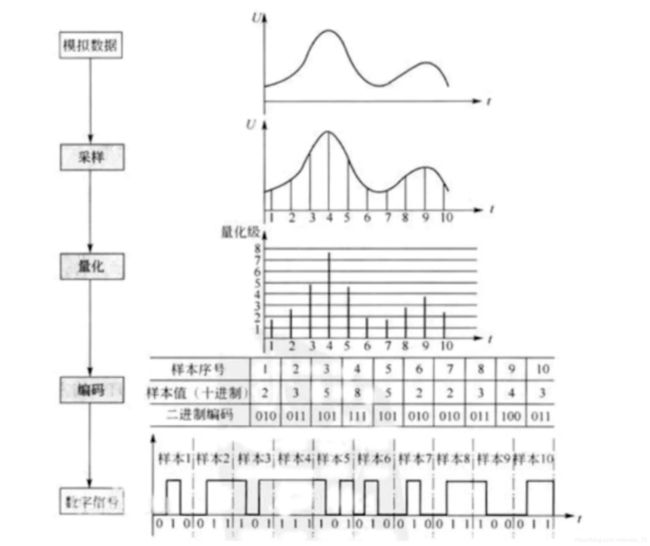
现实生活中,我们听到的声音都是时间连续的,我们把这种信号叫模拟信号。模拟信号(连续信号)需要量化成数字信号(离散的、不连续的信号)以后才能在计算机中使用。如下所示量化过程分为5个步骤:
- 模拟信号
现实生活中的声音表现为连续的、平滑的波形,其横坐标为时间轴,纵坐标表示声音的强弱。 - 采样
按照一定的时间间隔在连续的波上进行采样取值,如下图所示取了10个样。 - 量化
将采样得到的值进行量化处理,也就是给纵坐标定一个刻度,记录下每个采样的纵坐标的值。 - 编码
将每个量化后的样本值转换成二进制编码。 - 数字信号
将所有样本二进制编码连起来存储在计算机上就形成了数字信号。
(2)量化的基本概念
1)采样大小
一个采样用多少个bit存放,常用的是16bit(这就意味着上述的量化过程中,纵坐标的取值范围是0-65535,声音是没有负值的)。
2)采样率
也就是采样频率(1秒采样次数),一般采样率有8kHz、16kHz、32kHz、44.1kHz、48kHz等,采样频率越高,声音的还原就越真实越自然,当然数据量就越大。
模拟信号中,人类听觉范围是20-20000Hz,如果按照44.1kHz的频率进行采样,对20HZ音频进行采样,一个正玄波采样2200次;对20000HZ音频进行采样,平均一个正玄波采样2.2次。
3)声道数
为了播放声音时能够还原真实的声场,在录制声音时在前后左右几个不同的方位同时获取声音,每个方位的声音就是一个声道。声道数是声音录制时的音源数量或回放时相应的扬声器数量,有单声道、双声道、多声道。
4)码率
也叫比特率,是指每秒传送的bit数。单位为 bps(Bit Per Second),比特率越高,每秒传送数据就越多,音质就越好。
码率计算公式:
码率 = 采样率 * 采样大小 * 声道数
比如采样率44.1kHz,采样大小为16bit,双声道PCM编码的WAV文件:
码率=44.1hHz16bit2=1411.2kbit/s。
那么录制1分钟的音乐的大小为(1411.2 * 1000 * 60) / 8 / 1024 / 1024 = 10.09M。
3、音频压缩技术
音频压缩主要包括2种方法:
(1)消除冗余数据
这种压缩的主要方法是去除采集到的音频冗余信息,这些被删除掉的音频信号是没法恢复的,所以称为有损压缩。
冗余信息包括人类听觉范围之外的音频信号和被掩蔽掉的音频信号。什么是被掩蔽的信号呢?信号的掩蔽分为频域掩蔽和时域掩蔽。
1)频域掩蔽效应
人类听觉范围是20-20000Hz,但这并不意味着只要是这个频率范围内的声音都可以听到,能否听到还与声音的分贝大小有关,有个分贝临界值,高于这个临界值的声音才能听到,低于这个临界值的声音就听不到,在不同的频率下这个临界值是不一样的。
还有一种情况,比如2个音调差不多的人同时说话,一个声音很大,一个声音很小,声音小的会受到声音大的影响,导致声音小的无法被听到。
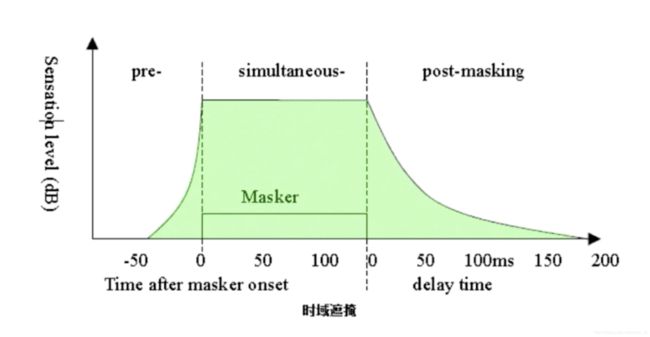
2)时域掩蔽效应
除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,称为时域掩蔽。时域掩蔽又分为超前掩蔽和滞后掩蔽,如下图所示。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。一般来说,超前掩蔽很短,只有大约5~20ms,而滞后掩蔽可以持续50~200ms。
(2)哈夫曼无损编码
将人类无法识别的声音信号删除掉后,对剩余的声音信号继续进行压缩编码,经过这种压缩后再还原时是可以复原到和原来一样的数据的(当然,复原也只是复原到压缩前的状态,那些删除的人类无法识别的部分是不能复原的),所以称为无损压缩。
二、音频信号的读写
标准的python已经支持WAV格式的书写,而实时的声音输入输出需要安装pyAudio(http://people.csail.mit.edu/hubert/pyaudio)。
音频信号是模拟信号,我们需要将其保存为数字信号,才能对语音进行算法操作,WAV是Microsoft开发的一种声音文件格式,通常被用来保存未压缩的声音数据。
语音信号有三个重要的参数:声道数、取样频率和量化位数。
- 声道数:可以是单声道或者是双声道。
- 采样频率:一秒内对声音信号的采集次数,44100Hz采样频率意味着每秒钟信号被分解成44100份。换句话说,每隔1/44100秒就会存储一次,如果采样率高,那么媒体播放音频时会感觉信号是连续的。
- 量化位数:用多少bit表达一次采样所采集的数据,通常有8bit、16bit、24bit和32bit等几种。
1、python读取.wav音频
下面是python读取音频代码
import wave
import struct
wave_file=wave.open("./sound111.wav", 'r')
channels=wave_file.getnchannels()#声道数
samp_width=wave_file.getsampwidth()#采样大小
frame_rate=wave_file.getframerate()#帧率
numframes=wave_file.getnframes()#总帧数
print("channel",channels)#声道数
print('samp_width',samp_width)#采样大小2B 16bit
print('frame_rate',frame_rate)#8000 帧率8000fps
print('numframes',numframes)#总帧数=帧率*时间=8000fps*10s=80000f
#输出
#channel 1
#samp_width 2
#frame_rate 8000
#numframes 80000
for i in range(500):
frame=wave_file.readframes(1)#读取1帧音频数据,可能包含多个声道信息
print(frame,struct.unpack("h",frame[0:2])[0])#struct.unpack("h",frame[0:2])将二进制数据转化成10进制(16bit有符号整数)因为这里采样大小是16bit
#输出
#b'\xd4\xfc' -812
#...
#b'\x07\xff' -249
#b'\x05\xff' -251
#b'X\xff' -168
#b'\xf2\xff' -14
#b'0\x00' 48
#b'#\x00' 35
wave_file.close()
2、python写.wav音频文件
在写入第一帧数据时,先通过调用setnframes()设置好帧数,setnchannels()设置好声道数,setsampwidth()设置量化位数,setframerate()设置好采样频率,然后writeframes(wave.tostring())用于写入帧数据。
Wave_write = wave.open(file,mode="wb")
Wave_write是写文件流,
Wave_write.setnchannels(n) 设置通道数。Wave_write.setsampwidth(n) 将样本宽度设置为n个字节,量化位数
Wave_write.setframerate(n) 将采样频率设置为n。Wave_write.setnframes(n) 将帧数设置为n
Wave_write.setparams(tuple) 以元组形式设置所有参数(nchannels, sampwidth, framerate, nframes,comptype, compname)
Wave_write.writeframes(data) 写入data个长度的音频,以采样点为单位
Wave_write.tell() 返回文件中的当前位置
写wav文件:
# -*- coding: utf-8 -*-
import wave
import numpy as np
import scipy.signal as signal
framerate = 44100 # 采样频率
time = 10 # 持续时间
t = np.arange(0, time, 1.0/framerate)
# 调用scipy.signal库中的chrip函数,
# 产生长度为10秒、取样频率为44.1kHz、100Hz到1kHz的频率扫描波
wave_data = signal.chirp(t, 100, time, 1000, method='linear') * 10000
# 由于chrip函数返回的数组为float64型,
# 需要调用数组的astype方法将其转换为short型。
wave_data = wave_data.astype(np.short)
# 打开WAV音频用来写操作
f = wave.open(r"sweep.wav", "wb")
f.setnchannels(1) # 配置声道数
f.setsampwidth(2) # 配置量化位数
f.setframerate(framerate) # 配置取样频率
comptype = "NONE"
compname = "not compressed"
# 也可以用setparams一次性配置所有参数
# outwave.setparams((1, 2, framerate, nframes,comptype, compname))
# 将wav_data转换为二进制数据写入文件
f.writeframes(wave_data.tostring())
f.close()