基于mapreduce的DBSCAN算法实现
东拼西凑拿mapreduce实现了下DBSCAN,很多地方其实并没有很并行,
密度聚类确实不太适合用MR来实现,写都写了整理一下。
算法流程
基于hadoop的MapReduce api实现的分布式DBSCAN算法。该算法实现流程分为七步:
- Similarity相似度计算部分,寻找满足阈值的点对组合。
- FindCore寻找核心点,找到满足最小邻域要求的核心点及其邻域信息。
- CoreList生成核心点列表。
- OnlyCore转换领域信息,将其变为只有核心点的组合。
- FirstCoreMerge按序排列,实现核心点组合第一步合并。
- CoreMerge完成核心点合并。
- FinalMerge 完成核心点和边界点合并,完成聚类。
文件输入与输出
每一步的输出与下一步的输入都用HDFS来存储,给出下面这个表格方便理解。
| 步骤 | 输出或读取文件 | 输出文件 |
|---|---|---|
| Similarity | data.txt | pair.txt |
| FindCore | pair.txt | core_neighbor.txt |
| CoreList | core_neighbor.txt | core_list.txt |
| OnlyCore | core_neighbor.txt;core_list.txt | only_core.txt |
| FirstCoreMerge | only_core.txt | core_cluster_first.txt |
| CoreMerge | core_cluster_first.txt | core_cluster_result.txt |
| FinalMerge | core_neighbor.txt;core_cluster_result.txt | final_merge.txt |
Similarity相似度计算
该部分读入文件为data.txt,即为坐标点数据文件,文件格式为id与空格分隔的坐标点分量。
这一部分MR并没有什么好的办法,总体还是在硬算。如果是文本相似度可能能用矩阵计算来并行处理,坐标就不太好整了。不过可以切片同时算最后汇总。
SimilarityMapper
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().trim();
String[] results = CalUtil.splitElementIntoArrStr(line);
// id为key,坐标为value
context.write(new IntWritable(Integer.parseInt(results[0])), new Text(results[1]));
}
该类实现了相似度计算MR过程中的mapper部分,其利用工具类中的split方法,将读入的data文件中坐标点id与坐标点进行分割,输出的key为坐标点id,value为坐标点分量以空格连接的字符串形式。工具类中的CalUtil.splitElementIntoArrStr()方法如下所示:
public static String[] splitElementIntoArrStr(String line){
String[] results = new String[2];
StringTokenizer tokenizer = new StringTokenizer(line);
String idStr = tokenizer.nextToken();
StringBuilder sb = new StringBuilder();
while (tokenizer.hasMoreTokens()){
sb.append(tokenizer.nextToken()).append(" ");
}
sb.subSequence(0, sb.length() - 1 );
results[0] = idStr;
results[1] = sb.toString();
return results;
}
利用tokenizer进行分割,为了返回两个值,将其存放于字符串字符中回传。
SimilarityReducer
Reducer主要包括两个部分。首先在所有reducer启动前利用setup方法读取一份data信息,以便在相似度计算中使用。并从configuration配置中读取threshold阈值信息。
@Override
protected void setup(Context context) throws IOException{
// reduce过程开始前调用一次,读取一份完整的坐标信息
// 同时读取data信息和
Configuration conf = context.getConfiguration();
String filePath = conf.get("data.filepath");
threshold = conf.getDouble("similarity.threshold", 0.0);
elementArrList = DataUtil.readElementArrList(filePath);
}
其中readElement方法将坐标点以字符串形式读取并存入list中。
在reduce方法中,将当前对应坐标点信息和所有其余点进行距离计算并与阈值进行比较,若其满足阈值条件,则将该点id与对应点id组成对进行输出。
@Override
protected void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 计算相似度信息
int idCal = key.get();
String arr = values.iterator().next().toString();
for(int i=0;i<elementArrList.size();i++){
if(i == idCal)
continue;
boolean isPaired = CalUtil.isDistanceBelowThreshold(arr, elementArrList.get(i), threshold);
if(isPaired){
context.write(new Text(String.valueOf(idCal)), new Text(String.valueOf(i)));
}
}
}
CalUtil.isDistanceBelowThreshold为工具类方法,通过切割两个点向量字符串形成double数组,借助欧氏距离进行距离计算,最后返回阈值比较结果。
public static boolean isDistanceBelowThreshold(String element1, String element2, double thresold){
ArrayList<Double> elementArray1 = splitStringIntoDoubleArr(element1);
ArrayList<Double> elementArray2 = splitStringIntoDoubleArr(element2);
double distance = calDistance(elementArray1, elementArray2);
return distance < thresold;
}
Similarity部分的输出文件每行格式为{ id1 id2 }。
SimilarityRun
该类设定了相似度计算部分的任务设置细节,主要要注意的是其进行了在配置类中的阈值与文件地址。
Configuration hadoopConfig = new Configuration();
// 向工作配置中设置文件地址和阈值信息
hadoopConfig.set("data.filepath", inputPath);
hadoopConfig.setDouble("similarity.threshold", threshold);
FindCore寻找核心点
该部分将上一步中的满足相似度信息的id对进行拆分,并通过将头个id相同的行通过mapper传入reducer,进而确定每个点的邻域中点的个数,判断是否为核心点。
FindCoreMapper
StringTokenizer tokenizer = new StringTokenizer(value.toString());
if(tokenizer.countTokens() == 2){
// 稍微检测一下免得格式出错
// 点对必定只能有两个值
String id1 = tokenizer.nextToken();
String id2 = tokenizer.nextToken();
context.write(new Text(id1), new Text(id2));
}
主要就是对点对进行分割,第一个id为key,第二个id为value进行输出。
FindCoreReducer
首先在setup中利用configuration读入最小邻域元素数量。
protected void setup(Context context) throws IOException, InterruptedException {
// 读取最小数量
Configuration config = context.getConfiguration();
minNum = config.getInt("findcore.minNum", 0);
}
reduce过程中,利用values迭代器遍历value值,将其转变为不重复id集合。通过计算id集合数量,根据DBSCAN定义,将自身也算入邻域信息,满足最小邻域元素数量的点即为核心点。
ArrayList<String> valueList = new ArrayList<String>();
for(Text v:values){
// 防止重复
if(!valueList.contains(v.toString())){
valueList.add(v.toString());
}
}
int num = valueList.size();
// 超过最小数目,为core(包括自己)
if(num + 1 >= minNum){
String idListStr = String.join(" ", valueList);
context.write(new Text(key), new Text(idListStr));
}
}
将其id作为key,其邻域中的点以空格进行连接,作为value输出。
FindCoreRun
该类展示了核心点发现任务的设置细节,主要注意的是设置了核心点邻域元素数量最小值。
Configuration hadoopConfig = new Configuration();
// 向工作配置中设置minNum
hadoopConfig.setInt("findcore.minNum", minNum);
CoreList部分
该部分比较简单,只是利用MapReduce的按行读取来对核心点寻找部分的输出进行处理,将key也就是核心点id存储到同个文件中。
CoreListMapper
该mapper将每行进行空格分割,选取第一个值也就是core id核心点id输出至reducer中。
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 每一行只取最前面的一个token
// 因为不会重复,直接key value相同输出
StringTokenizer tokenizer = new StringTokenizer(value.toString());
String id = tokenizer.nextToken();
context.write(new Text(id), new Text(id));
}
CoreListReducer
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 直接输出,key为空
String value = null;
for(Text t:values){
value = t.toString();
}
context.write(new Text(""), new Text(value));
}
简单进行输出即可,因为key没有意义,直接以一个空格进行输出。输出结果为每行一个核心点id。
OnlyCore部分
该部分主要对第二部分findcore的输出进行处理,将其中的核心点邻域信息中的所有边界点剔除后输出,也就是将核心点邻域中的所有其他核心点id输出。
OnlyCoreMapper
该类处理前先在setup中读取核心点列表信息,方便之后辨认核心点。核心点列表文件地址通过配置类进行获取。
protected void setup(Context context) throws IOException, InterruptedException {
// 先把core读进来
Configuration config = context.getConfiguration();
String filePath = config.get("corelist.core_list_filepath");
coreList = DataUtil.readCoreList(filePath);
}
之后对输入的每行进行分割处理,保留头部的coreid,对后续id集合进行遍历,当其存在于核心点集合中,进行组合输出。若某行对应的coreid对应的核心点邻域中没有其余的核心点,则输出空格意思一下。
StringTokenizer tokenizer = new StringTokenizer(value.toString());
ArrayList<String> core_neighbor_list = new ArrayList<String>();
String coreId = tokenizer.nextToken();
while(tokenizer.hasMoreTokens()){
String token = tokenizer.nextToken();
if(coreList.contains(token)){
// 为核心点,则放入
core_neighbor_list.add(token);
}
}
if(core_neighbor_list.size() > 0){
// 核心点包核心点
String core_neighbor_str = String.join(" ", core_neighbor_list);
context.write(new Text(coreId), new Text(core_neighbor_str));
}else{
// 单一核心点,输出个空格好了
context.write(new Text(coreId), new Text(" "));
}
OnlyCoreReducer
每个key都不一样,只要读一次value并输出即可。
String value = null;
for(Text v:values){
value = v.toString();
}
context.write(key, new Text(value));
OnlyCoreRun
该类详细定义了找到核心点邻域内其余核心点信息的任务设置细节,主要要注意的是设置了核心点列表文件地址。
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("corelist.core_list_filepath", coreListPath);
FirstCoreMerge部分
在算法中设置该部分是为了利用MapReduce的特性来聚合一部分的onlyCore输出信息进行merge操作,减轻最终整合时的计算压力。算是唯一的创新点吧,很惭愧。
主要思路是将only core中输出的核心点邻域核心信息进行从小到大的排序操作,之后将第一个id作为key,其他id作为value传入reducer中,从而可以借助reducer将一部分核心点进行merge操作,大大减轻后续完整整合的压力。
举例来说,假设only core中包含以下信息(方便阅读,分号作为换行标识):
1 2 3;2 1 5;3 7;
此时,经过排序操作,该数据会变为两部分,1 2 3;1 2 5与3 7,reducer中可以将前两者进行merge变为1 2 3 5,这样在最后的操作中只要将剩余的 1 2 3 5与 3 7两行进行merge即可,这在大量数据的条件下可以使大部分的合并操作利用MapReduce机制来分布式实现。
CoreClusterMapper
虽然步骤叫coreMerge但是类写成这名了,将就看吧。Mapper中将每行数据转换为整型数据的集合进行排序操作,并以排序后的第一个id,即最小id作为key进行输出,使reducer中可进行merge操作。
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 排序操作
String[] result = CalUtil.sortArrByIntegerList(value.toString());
System.out.println(result[0]);
System.out.println(result[1]);
context.write(new Text(result[0]), new Text(result[1]));
}
其中CalUtil.sortArrByIntegerList方法实现了排序操作。输出为一个字符串数组,包括最小id字符串和其他id组成的字符串。当只有单个核心时,数组第二个值设置为空格。
public static String[] sortArrByIntegerList(String line){
ArrayList<Integer> intList = convertStrIntoIntegerList(line);
intList = sortIntegerList(intList);
// 最小的核作为key
String keyId = String.valueOf(intList.get(0));
// 剩下的连起来
StringBuilder sb = new StringBuilder();
for(int i=1;i<intList.size();i++){
sb.append(intList.get(i)).append(" ");
}
String[] result = new String[2];
result[0] = keyId;
System.out.println(intList.size());
if(intList.size() <= 1){
// 单个核心,输出个空格
result[1] = " ";
}else{
result[1] = sb.toString().substring(0, sb.length()-1);
}
return result;
}
重写Comparator的compare方法来实现从小到大的集合排序。
public static ArrayList<Integer> sortIntegerList(ArrayList<Integer> intList){
intList.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
if(o1 < o2)
return -1;
else if(o1 > o2)
return 1;
else
return 0;
}
});
return intList;
}
CoreClusterReducer
reducer中主要实现为将所有的value进行分割并不重复地进行合并,最终输出排序后地最小id为key,其余id空格连接成为value即可。
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
String minCoreId = key.toString();
ArrayList<Integer> uniqueId = new ArrayList<Integer>();
// 把value作为list合并
for(Text v:values){
// 注意可能有单个空格值
if(!v.toString().equals(" ")){
ArrayList<Integer> neighbor_list = CalUtil.convertStrIntoIntegerList(v.toString());
for(Integer intNeighbor:neighbor_list){
if(!uniqueId.contains(intNeighbor)){
uniqueId.add(intNeighbor);
}
}
}
}
// 排序输出
uniqueId = CalUtil.sortIntegerList(uniqueId);
StringBuilder sb = new StringBuilder();
for(int i=1;i<uniqueId.size();i++){
sb.append(uniqueId.get(i)).append(" ");
}
context.write(key, new Text(sb.toString()));
}
最终输出格式为coreid coreid1 … coreidn。
CoreMerge部分
因为merge部分的特殊性,不能将其完全利用MapReduce进行优化计算,最终的实现是将上一步进行简化过的核心点邻域信息全部存入相同key对中,利用同一reducer进行处理。所以该部分主要对merge算法进行讲解,忽略mapper和reducer的具体实现过程。
CoreClusterMergeAdapter
该类实现了具体的merge合并方法。
首先讲解工具类方法:
public static boolean hasSameElement(ArrayList<String> list1, ArrayList<String> list2){
for (String s : list1) {
if (list2.contains(s))
return true;
}
return false;
}
public static void combineList(ArrayList<String> list1, ArrayList<String> list2){
list1.removeAll(list2);
list1.addAll(list2);
}
hasSameElement方法对两个字符串形式的id集合进行判断,有相同元素则输出true,没有则输出false。combineList方法则借助List类方法,将两个参数中的第一个list转换为参数中两个list的非重复并集。
具体的core merge实现可以如下表示:
首先,对每一个core id及其领域中核心点的集合进行处理,对每一个集合赋予一个used值,初始为0。之后,对第一个集合进行操作,将其与所有其他集合进行hasSameElement的判断,当返回为真时,对这两个集合的进行非重复并集操作,并将第一个集合对应used值转换为1,另一个转为2,之后寻找used为0的集合重复操作直到遍历完成。
最后,对所有used值为0或1的集合进行输出,输出结果即为完成merge合并的核心点邻域中核心点信息。
总的来说就是一个并集操作。
public static ArrayList<String> onlyCoreMerge(ArrayList<ArrayList<String>> coreList){
// 0为未被使用,1为已被使用并作为簇保留,2为被吸干
int[] isUsed = new int[coreList.size()];
for(int i=0;i<coreList.size();i++){
ArrayList<String> now = coreList.get(i);
if(isUsed[i] == 0){
// 找到包含now中某个值的list,并全部吸干
for(int j=0;j<coreList.size();j++){
// 可吸选手
if(isUsed[j]!=1 && isUsed[j]!=2 && i!=j){
// 有交集
if(CalUtil.hasSameElement(now, coreList.get(j))){
CalUtil.combineList(now, coreList.get(j));
isUsed[j] = 2;
isUsed[i] = 1;
}
}
}
}
}
ArrayList<String> result = new ArrayList<String>();
for(int i=0;i<isUsed.length;i++){
if(isUsed[i] == 1 || isUsed[i] == 0){
result.add(String.join(" ", coreList.get(i)));
}
}
return result;
}
输出格式与FirstCoreMerge的输出相同。
FinalMerge部分
该部分职责就是将核心点与边界点进行合并,完成DBSCAN聚类操作。
FinalMergeMapper
Mapper中输入为第二部分的核心点邻域信息输出内容。
首先,利用setup将Core merge部分输出读入。
protected void setup(Context context) throws IOException, InterruptedException {
Configuration config = context.getConfiguration();
String filePath = config.get("merge.core_cluster_result_path");
core_cluster_result = DataUtil.readCoreClusterResult(filePath);
}
该操作主要是为了将核心点邻域信息的key改为core merge中的某值,也就是说,在map操作中,通过与Core merge进行比对,核心点id转换为其所在的core合并结果的所有id集合形成的字符串,以便在reducer中将所有的边界点进行合并。
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 每行转list,查询是否有交集
StringTokenizer tokenizer = new StringTokenizer(value.toString());
ArrayList<String> singleList = new ArrayList<String>();
while(tokenizer.hasMoreTokens()){
singleList.add(tokenizer.nextToken());
}
for(ArrayList<String> list:core_cluster_result){
if(CalUtil.hasSameElement(list, singleList)){
context.write(new Text(String.join(" ", list)), new Text(value));
break;
}
}
}
hasSameElement方法作用已在前文中描述过。
FinalMergeReducer
reducer中对所有value进行分割组装,最终输出每行为对应聚类结果簇的所有簇中元素id的空格连接字符串。
ArrayList<String> list = new ArrayList<String>();
for(Text v:values){
StringTokenizer tokenizer = new StringTokenizer(v.toString());
ArrayList<String> singleList = new ArrayList<String>();
while(tokenizer.hasMoreTokens()){
singleList.add(tokenizer.nextToken());
}
// 获取非重复并集
CalUtil.combineList(list, singleList);
}
// 输出结果
String clusterStr = String.join(" ", list);
int firstBlankIndex = clusterStr.indexOf(" ");
context.write(new Text(clusterStr.substring(0, firstBlankIndex)), new Text(clusterStr.substring(firstBlankIndex + 1)));
FinalMergeRun
该类设置了FinalMerge任务的细节,主要是设置了core merge结果的文件地址。
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("merge.core_cluster_result_path", coreClusterResultPath);
总任务调度方法
主方法输入三个参数,分别为阈值,核心点最小邻域元素数与数据文件。
HDbscan
String dataPath = DataUtil.HDFS_INPUT + "/" + args[2]; // 数据集地址
String similarityPairPath = DataUtil.HDFS_OUTPUT + "/pair.txt"; // 满足阈值的点对结果输出地址
String coreNeighborPath = DataUtil.HDFS_OUTPUT + "/core_neighbor.txt"; // 核心点及其邻域点输出地址
String coreListPath = DataUtil.HDFS_OUTPUT + "/core_list.txt"; // 核心点列表输出地址
String onlyCoreNeighborPath = DataUtil.HDFS_OUTPUT + "/only_core.txt"; // 仅核心点邻域输出地址
String coreClusterFirstStep = DataUtil.HDFS_OUTPUT + "/core_cluster_first.txt"; // core cluster按序合并第一步输出地址
String coreClusterResult = DataUtil.HDFS_OUTPUT + "/core_cluster_result.txt"; // core cluster合并最终输出地址
String finalMergePath = DataUtil.HDFS_OUTPUT + "/final_merge.txt"; // 最终合并输出地址
double threshold = Double.parseDouble(args[0]); // 阈值
int minNum = Integer.parseInt(args[1]); // 成为核心的最低要求
// SimilarityRun.run(dataPath, similarityPairPath, threshold); // 计算相似度
// FindCoreRun.run(similarityPairPath, coreNeighborPath, minNum); // 寻找核心点
// CoreListRun.run(coreNeighborPath, coreListPath); // 核心点列表
// OnlyCoreRun.run(coreNeighborPath, onlyCoreNeighborPath, coreListPath); // 转为只有核心点的序列
// CoreClusterRun.firstRun(onlyCoreNeighborPath, coreClusterFirstStep); // core cluster按序合并第一步
// CoreClusterRun.secondRun(coreClusterFirstStep, coreClusterResult); // core cluster按序合并
FinalMergeRun.run(coreNeighborPath, finalMergePath, coreClusterResult); // 最终组合,完成聚类
结果展示
本来是在云服务器上搭的集群,结果有台被挖矿注入了懒得恢复了,yarn默认端口害人不浅。本地简单看看效果。
有点要注意的是,云服务器对自身操作都需要使用内网地址,因为这个当时踩了不少坑。
数据集格式
实验数据选取自美国zillow房地产评估2017年房产数据,选取其中的经纬度信息进行聚类操作,方便可视化。数据经处理转移到txt格式,并存入hdfs中进行实验。

jar文件与运行命令
将程序打包为dbscan_whole.jar文件在服务器上运行。
hadoop jar dbscan_whole.jar com.huiluczP.HDbscan 20000 30 10000data.txt
距离阈值选取20000,最小邻域元素数为30,数据集为10000data.txt。
实验结果数据

相似度计算输出pair.txt:

核心点寻找输出core_neighbor.txt:
核心点列表生成core_list.txt

只有核心点的邻域信息only_core.txt

核心点merge第一步core_cluster_first.txt
核心点完整合并 core_cluster_result.txt
聚类结果 final_merge.txt
聚类结果簇为29个。
![]()
聚类结果可视化
把文件提出来以后(写了个简单循环读HDFS的玩意),拿python写了个简单可视。
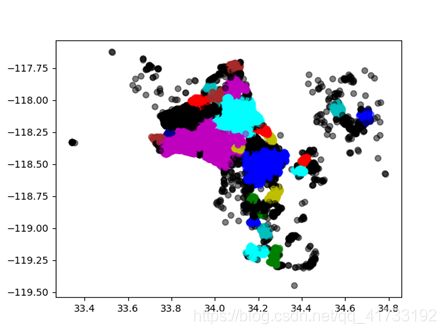
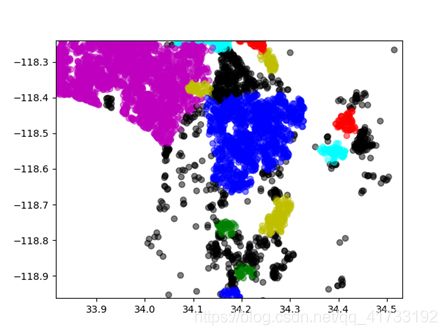
可以看出,根据密度聚类后,簇的边界分明而大小不同,这是由于城市人口与农村人口的差异,美国西部农村荒野多,呈现这种聚类状况合理,聚类效果良好。
项目链接
项目已上传至github,把数据集文件也传上去了,有兴趣可以看看。
https://github.com/huiluczP/hadoop_dbscan
总结
总的来说就是差不多实现了一版DBSCAN,算是熟悉下MR吧。密度聚类确实不太适合MR来做,有空补一个spark的。