4.3、Flink任务怎样读取Kafka中的数据
目录
1、添加pom依赖
2、API使用说明
3、这是一个完整的入门案例
4、Kafka消息应该如何解析
4.1、只获取Kafka消息的value部分
4.2、获取完整Kafka消息(key、value、Metadata)
4.3、自定义Kafka消息解析器
5、起始消费位点应该如何设置
5.1、earliest()
5.2、latest()
5.3、timestamp()
6、Kafka分区扩容了,该怎么办 —— 动态分区检查
7、在加载KafkaSource时提取事件时间&添加水位线
7.1、使用内置的单调递增的水位线生成器 + kafka timestamp 为事件时间
7.2、使用内置的单调递增的水位线生成器 + kafka 消息中的 ID字段 为事件时间
1、添加pom依赖
我们可以使用Flink官方提供连接Kafka的工具flink-connector-kafka
该工具实现了一个消费者FlinkKafkaConsumer,可以用它来读取kafka的数据
如果想使用这个通用的Kafka连接工具,需要引入jar依赖
org.apache.flink
flink-connector-kafka
1.17.0
2、API使用说明
官网链接:Apache Kafka 连接器
语法说明:
// 1.初始化 KafkaSource 实例
KafkaSource source = KafkaSource.builder()
.setBootstrapServers(brokers) // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点)
.setTopics("input-topic") // 必填:指定要消费的topic
.setGroupId("my-group") // 必填:指定消费者的groupid(不存在时会自动创建)
.setValueOnlyDeserializer(new SimpleStringSchema()) // 必填:指定反序列化器(用来解析kafka消息数据,转换为flink数据类型)
.setStartingOffsets(OffsetsInitializer.earliest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest())
.build();
// 2.通过 fromSource + KafkaSource 获取 DataStreamSource
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source"); 3、这是一个完整的入门案例
开发语言:java1.8
flink版本:flink1.17.0
public class ReadKafka {
public static void main(String[] args) throws Exception {
newAPI();
}
public static void newAPI() throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.读取kafka数据
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092") // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点)
.setTopics("20230810") // 必填:指定要消费的topic
.setGroupId("FlinkConsumer") // 必填:指定消费者的groupid(不存在时会自动创建)
.setValueOnlyDeserializer(new SimpleStringSchema()) // 必填:指定反序列化器(用来解析kafka消息数据)
.setStartingOffsets(OffsetsInitializer.earliest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest())
.build();
env.fromSource(source,
WatermarkStrategy.noWatermarks(),
"Kafka Source")
.print()
;
// 3.触发程序执行
env.execute();
}
}
4、Kafka消息应该如何解析
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析
反序列化器的功能:
将Kafka ConsumerRecords转换为Flink处理的数据类型(Java/Scala对象)
反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema.of(反序列化器类型)) 指定
下面介绍两种常用Kafka消息解析器:
KafkaRecordDeserializationSchema.of(new JSONKeyValueDeserializationSchema(true)) :
1、返回完整的Kafka消息,将JSON字符串反序列化为ObjectNode对象
2、可以选择是否返回Kafak消息的Metadata信息,true-返回,false-不返回
KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class) :
1、只返回Kafka消息中的value部分
4.1、只获取Kafka消息的value部分
4.2、获取完整Kafka消息(key、value、Metadata)
kafak消息格式:
key = {"nation":"蜀国"}
value = {"ID":整数}
public static void ParseMessageJSONKeyValue() throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.读取kafka数据
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092") // 必填:指定broker连接信息 (为保证高可用,建议多指定几个节点)
.setTopics("9527") // 必填:指定要消费的topic
.setGroupId("FlinkConsumer") // 必填:指定消费者的groupid(不存在时会自动创建)
// 必填:指定反序列化器(将kafak消息解析为ObjectNode,json对象)
.setDeserializer(KafkaRecordDeserializationSchema.of(
// includeMetadata = (true:返回Kafak元数据信息 false:不返回)
new JSONKeyValueDeserializationSchema(true)
))
.setStartingOffsets(OffsetsInitializer.latest()) // 可选:指定启动任务时的消费位点(不指定时,将默认使用 OffsetsInitializer.earliest())
.build();
env
.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
.print()
;
// 3.触发程序执行
env.execute();
}
运行结果:
常见报错:
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = 9527, partition = 0, leaderEpoch = 0, offset = 1064, CreateTime = 1691668775938, serialized key size = 4, serialized value size = 9, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@5e9eaab8, value = [B@67390400).
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:57)
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53)
... 14 more
Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'xxxx': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')
at [Source: (byte[])"xxxx"; line: 1, column: 5]报错原因:
出现这个报错,一般是使用flink读取fafka时,使用JSONKeyValueDeserializationSchema
来解析消息时,kafka消息中的key 或者 value 内容不符合json格式而造成的解析错误
例如下面这个格式,就会造成解析错误 key=1000,value=你好
那应该怎么解决呢?
1、如果有权限修改Kafka消息格式,可以将Kafka消息key&value内容修改为Json格式
2、如果没有权限修改Kafka消息格式(比如线上环境,修改比较困难),可以重新实现
JSONKeyValueDeserializationSchema类,根据所需格式来解析Kafka消息(可以参考源码)
4.3、自定义Kafka消息解析器
生产中对Kafka消息及解析的格式总是各种各样的,当flink预定义的解析器满足不了业务需求时,可以通过自定义kafka消息解析器来完成业务的支持
例如,当使用 MyJSONKeyValueDeserializationSchema 获取Kafka元数据时,只返回了 offset、topic、partition 三个字段信息,现在需要`kafka生产者写入数据时的timestamp`,就可以通过自定义kafka消息解析器来完成
代码示例:
// TODO 自定义Kafka消息解析器,在 metadata 中增加 timestamp字段
public class MyJSONKeyValueDeserializationSchema implements KafkaDeserializationSchema{
private static final long serialVersionUID = 1509391548173891955L;
private final boolean includeMetadata;
private ObjectMapper mapper;
public MyJSONKeyValueDeserializationSchema(boolean includeMetadata) {
this.includeMetadata = includeMetadata;
}
@Override
public void open(DeserializationSchema.InitializationContext context) throws Exception {
mapper = JacksonMapperFactory.createObjectMapper();
}
@Override
public ObjectNode deserialize(ConsumerRecord record) throws Exception {
ObjectNode node = mapper.createObjectNode();
if (record.key() != null) {
node.set("key", mapper.readValue(record.key(), JsonNode.class));
}
if (record.value() != null) {
node.set("value", mapper.readValue(record.value(), JsonNode.class));
}
if (includeMetadata) {
node.putObject("metadata")
.put("offset", record.offset())
.put("topic", record.topic())
.put("partition", record.partition())
// 添加 timestamp 字段
.put("timestamp",record.timestamp())
;
}
return node;
}
@Override
public boolean isEndOfStream(ObjectNode nextElement) {
return false;
}
@Override
public TypeInformation getProducedType() {
return getForClass(ObjectNode.class);
}
}
运行结果:

5、起始消费位点应该如何设置
起始消费位点说明:
起始消费位点是指 启动flink任务时,应该从哪个位置开始读取Kafka的消息
下面介绍下常用的三个设置:
OffsetsInitializer.earliest() :
从最早位点开始消
这里的最早指的是Kafka消息保存的时长(默认为7天,生成环境各公司略有不同)
该这设置为默认设置,当不指定OffsetsInitializer.xxx时,默认为earliest()
OffsetsInitializer.latest() :
从最末尾位点开始消费
这里的最末尾指的是flink任务启动时间点之后生产的消息
OffsetsInitializer.timestamp(时间戳) :
从时间戳大于等于指定时间戳(毫秒)的数据开始消费
下面用案例说明下,三种设置的效果,kafak生成10条数据,如下:
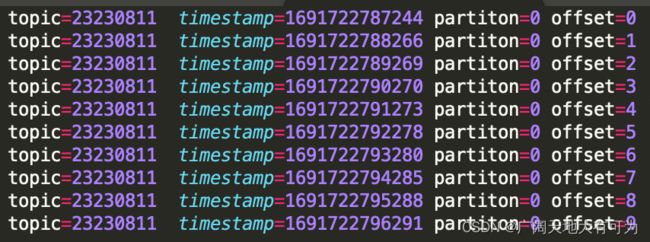 5.1、earliest()
5.1、earliest()
代码示例:
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("23230811")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new JSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从最早位置开始消费(该设置为默认设置)
.setStartingOffsets(OffsetsInitializer.earliest())
.build(); 运行结果:
5.2、latest()
代码示例:
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("23230811")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new JSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest())
.build(); 运行结果:
5.3、timestamp()
代码示例:
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("23230811")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new MyJSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从指定时间戳后开始消费
.setStartingOffsets(OffsetsInitializer.timestamp(1691722791273L))
.build(); 运行结果:
6、Kafka分区扩容了,该怎么办 —— 动态分区检查
在flink1.13的时候,如果Kafka分区扩容了,只有通过重启flink任务,才能消费到新增分区的数据,小编就曾遇到过上游业务部门的kafka分区扩容了,并没有通知下游使用方,导致实时指标异常,甚至丢失了数据。
在flink1.17的时候,可以通过`开启动态分区检查`,来实现不用重启flink任务,就能消费到新增分区的数据
开启分区检查:(默认不开启)
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区代码示例:
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("9527")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new JSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest())
// 开启动态分区检查(默认不开启)
.setProperty("partition.discovery.interval.ms", "10000") // 每 10 秒检查一次新分区
.build(); 7、在加载KafkaSource时提取事件时间&添加水位线
可以在 fromSource(source,WatermarkStrategy,sourceName) 时,提取事件时间和制定水位线生成策略
注意:当不指定事件时间提取器时,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间
7.1、使用内置的单调递增的水位线生成器 + kafka timestamp 为事件时间
代码示例:
// 在读取Kafka消息时,提取事件时间&插入水位线
public static void KafkaSourceExtractEventtimeAndWatermark() throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.读取kafka数据
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("9527")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new MyJSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest())
.build();
env.fromSource(source,
// 使用内置的单调递增的水位线生成器(默认使用 kafka的timestamp作为事件时间)
WatermarkStrategy.forMonotonousTimestamps(),
"Kafka Source")
// 通过 ProcessFunction 查看提取的事件时间和水位线信息
.process(
new ProcessFunction() {
@Override
public void processElement(ObjectNode kafkaJson, ProcessFunction.Context ctx, Collector out) throws Exception {
// 当前处理时间
long currentProcessingTime = ctx.timerService().currentProcessingTime();
// 当前水位线
long currentWatermark = ctx.timerService().currentWatermark();
StringBuffer record = new StringBuffer();
record.append("========================================\n");
record.append(kafkaJson + "\n");
record.append("currentProcessingTime:" + currentProcessingTime + "\n");
record.append("currentWatermark:" + currentWatermark + "\n");
record.append("kafka-ID:" + Long.parseLong(kafkaJson.get("value").get("ID").toString()) + "\n");
record.append("kafka-timestamp:" + Long.parseLong(kafkaJson.get("metadata").get("timestamp").toString()) + "\n");
out.collect(record.toString());
}
}
).print();
// 3.触发程序执行
env.execute();
}
运行结果:
7.2、使用内置的单调递增的水位线生成器 + kafka 消息中的 ID字段 为事件时间
代码示例:
// 在读取Kafka消息时,提取事件时间&插入水位线
public static void KafkaSourceExtractEventtimeAndWatermark() throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.读取kafka数据
KafkaSource source = KafkaSource.builder()
.setBootstrapServers("worker01:9092")
.setTopics("9527")
.setGroupId("FlinkConsumer")
// 将kafka消息解析为Json对象,并返回元数据
.setDeserializer(KafkaRecordDeserializationSchema.of(
new MyJSONKeyValueDeserializationSchema(true)
))
// 设置起始消费位点:从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest())
.build();
env.fromSource(source,
// 使用内置的单调递增的水位线生成器(使用 kafka消息中的ID字段作为事件时间)
WatermarkStrategy.forMonotonousTimestamps()
// 提取 Kafka消息中的 ID字段作为 事件时间
.withTimestampAssigner(
(json, timestamp) -> Long.parseLong(json.get("value").get("ID").toString())
),
"Kafka Source")
// 通过 ProcessFunction 查看提取的事件时间和水位线信息
.process(
new ProcessFunction() {
@Override
public void processElement(ObjectNode kafkaJson, ProcessFunction.Context ctx, Collector out) throws Exception {
// 当前处理时间
long currentProcessingTime = ctx.timerService().currentProcessingTime();
// 当前水位线
long currentWatermark = ctx.timerService().currentWatermark();
StringBuffer record = new StringBuffer();
record.append("========================================\n");
record.append(kafkaJson + "\n");
record.append("currentProcessingTime:" + currentProcessingTime + "\n");
record.append("currentWatermark:" + currentWatermark + "\n");
record.append("kafka-ID:" + Long.parseLong(kafkaJson.get("value").get("ID").toString()) + "\n");
record.append("kafka-timestamp:" + Long.parseLong(kafkaJson.get("metadata").get("timestamp").toString()) + "\n");
out.collect(record.toString());
}
}
).print();
// 3.触发程序执行
env.execute();
}
运行结果: