基于pyspark的als推荐电影
ALS推荐算法:
ALS算法是基于模型的推荐算法
基本思想
对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型。然后依照此模型可以针对新的用户和物品数据进行评估。ALS是采用交替的最小二乘法来算出缺失项的,交替的最小二乘法是在最小二乘法的基础上发展而来的。
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF,它同时考虑了User和Item两个方面。
矩阵分解模型的物理意义:
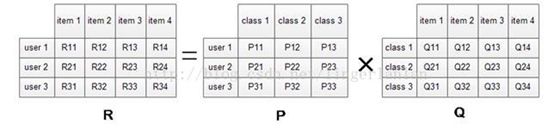
模型参数:
val model=ALS.train(ratings,rank,numIterations,lambda)
•numBlocks 是用于并行化计算的分块个数 (设置为-1,为自动配置)。
•rank 是模型中隐语义因子的个数。
•iterations 是迭代的次数。
•lambda 是ALS的正则化参数。
•implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
•alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
可以调整这些参数,不断优化结果,使均方差变小。比如:iterations越多,lambda较小,均方差会较小,推荐结果较优。
实现代码
'''
观众影评数据集(观众ID,影片ID,评分)
电影数据集(编号,电影名(上映年)....)
'''
from pyspark import SparkContext,SparkConf
import os,sys
import numpy as np
os.environ['SPARK_HOME'] = "D:\Soft\Spark\spark-2.4.4-bin-hadoop2.7"
os.environ['HADOOP_HOME'] = "D:\Soft\hadoop-2.7.4"
os.environ['JAVA_HOME'] = "D:\JDK"
os.environ['PYTHONHASHSEED'] = "66"
sc = SparkContext("local","ALS_ZD1")
raw_data = sc.textFile('u.data')
print(raw_data.first())#196 242 3 881250949
raw_ratings = raw_data.map(lambda x : x.split('\t'))
print(raw_ratings.take(5))
from pyspark.mllib.recommendation import Rating, ALS
ratings = raw_ratings.map(lambda x: Rating(int(x[0]),int(x[1]),float(x[2])))
print(ratings.take(5))
model = ALS.train(ratings,50,10,0.01)#
user_features = model.userFeatures()
#用户789推荐top10的items,其items顺序为降序
topKRecs = model.recommendProducts(789,10)
for i in topKRecs:
print(i)
#比对用户所评级过得电影和被推荐的电影
movies_for_user = ratings.groupBy(lambda x:x.user).mapValues(list).lookup(789)
print(movies_for_user)
print('用户对%d部电影进行了评级'%len(movies_for_user[0]))
print('源数据中用户(userId=789)喜欢的电影(item):')
for i in sorted(movies_for_user[0],key=lambda x : x.rating,reverse=True):
print(i.product)
movies = sc.textFile("u.item")
titles = movies.map(lambda line: (int(line.split('|')[0]),line.split('|')[1])).collectAsMap()#电影名称集合
print(titles[1])#Toy Story (1995)
for i,rec in enumerate(topKRecs):
print('rank:'+str(i)+' '+str(titles[rec.product])+':'+str(rec.rating))
actual = movies_for_user[0][2]
actualRating = actual.rating
print ('用户789对电影1012的实际评级',actualRating)
predictedRating = model.predict(789, actual.product)
print('用户789对电影1012的预测评级',predictedRating)
squaredError = np.power(actualRating-predictedRating,2)
print('实际评级与预测评级的MSE',squaredError)
userProducts = ratings.map(lambda rating:(rating.user,rating.product))
print ('实际的评分:',userProducts.take(5))
print (model.predictAll(userProducts).collect()[0])
predictions = model.predictAll(userProducts).map(lambda rating:((rating.user,rating.product), rating.rating))
print( '预测的评分:',predictions.take(5))
ratingsAndPredictions = ratings.map(lambda rating:((rating.user,rating.product),rating.rating)).join(predictions)
print('组合预测的评分和实际的评分:',ratingsAndPredictions.take(5))
actualMovies = [rating.product for rating in movies_for_user[0]]
predictMovies = [rating.product for rating in topKRecs]
print('实际的电影:',actualMovies)
print('预测的电影:',predictMovies)
from pyspark.mllib.evaluation import RegressionMetrics
from pyspark.mllib.evaluation import RankingMetrics
#((196, 242), (3.0, 3.089619902353484)),
predictedAndTrue = ratingsAndPredictions.map(lambda x:x[1][0:2])
print (predictedAndTrue.take(5))
regressionMetrics = RegressionMetrics(predictedAndTrue)
print ("均方误差 = %f"%regressionMetrics.meanSquaredError)
print ("均方根误差 = %f"% regressionMetrics.rootMeanSquaredError)
运行结果:
