LearnOpenGL 学习笔记 PBR
目录
-
- PBR 基础知识
- 光照
- IBL
-
- HDR
- 从等距柱状投影到立方体贴图
- 漫反射立方体环境贴图求卷积
- 镜面反射部分
-
- 分割求和近似法
- 镜面反射立方体环境贴图求卷积
- 蒙特卡罗积分
- 生成随机数的方法
- 重要性采样
- 预过滤卷积的伪像
-
- 高粗糙度的立方体贴图接缝
- 预过滤卷积的亮点
- 预计算 BRDF
PBR 基础知识
辐射度量学,渲染方程,PBR 基于物理的渲染:微表面、能量守恒、反射方程中的双向反射分布函数 BRDF、漫反射部分和镜面反射部分
光照
略
IBL
光源不是如前一节教程中描述的可分解的直接光源,而是将周围环境整体视为一个大光源。
IBL 通常使用(取自现实世界或从3D场景生成的)环境立方体贴图 (Cubemap) ,我们可以将立方体贴图的每个像素视为光源,在渲染方程中直接使用它。这种方式可以有效地捕捉环境的全局光照和氛围,使物体更好地融入其环境。
由于基于图像的光照算法会捕捉部分甚至全部的环境光照,通常认为它是一种更精确的环境光照输入格式,甚至也可以说是一种全局光照的粗略近似。基于此特性,IBL 对 PBR 很有意义,因为当我们将环境光纳入计算之后,物体在物理方面看起来会更加准确。
微表面模型下的反射方程
L o ( p , w o ) = ∫ Ω ( k d c π + k s D F G 4 ( w o ⋅ n ) ( w i ⋅ n ) ) L i ( p , w i ) n ⋅ w i d w i L_o(p,w_o) = \int_{\Omega}(k_d\dfrac{c}{\pi}+k_s\dfrac{DFG}{4(w_o\cdot n)(w_i\cdot n)})L_i(p,w_i) n \cdot w_i \mathrm d w_i Lo(p,wo)=∫Ω(kdπc+ks4(wo⋅n)(wi⋅n)DFG)Li(p,wi)n⋅widwi
假设只有一两个点光源,那么积分的计算就是离散的几个计算
但是如果是从各个方向都有光源的话,就需要对各个方向采样了
从各个方向采样的结果就是全局光照
也就是对于一个半球,采样 N 个点,每个点都发出 M 个光线,光线会返回 radiance
当然这很容易光线数量爆炸,所以 M = 1 是最保险的,称为路径追踪
M != 1 称为分布式路径追踪
光线使用俄罗斯轮盘赌来决定是否停止
更进一步,直接光照直接对光源方向进行蒙特卡洛积分,而间接光照就在半球上随机方向进行蒙特卡罗积分
当然每一个像素点做一遍路径追踪也很耗时,所以不是实时的
现在我们需要实时的算法。
对于反射方程的漫反射部分:
k d c π ∫ Ω L i ( p , w i ) n ⋅ w i d w i k_d\dfrac{c}{\pi} \int_{\Omega}L_i(p,w_i) n \cdot w_i \mathrm d w_i kdπc∫ΩLi(p,wi)n⋅widwi
可以把这个积分做成一个立方体贴图,它在每个采样方向——也就是纹素——中存储漫反射积分的结果,这些结果是通过卷积计算出来的。
卷积的特性是,对数据集中的一个条目做一些计算时,要考虑到数据集中的所有其他条目。这里的数据集就是场景的辐射度或环境贴图。因此,要对立方体贴图中的每个采样方向做计算,我们都会考虑半球 Ω 上的所有其他采样方向。
为了对环境贴图进行卷积,我们通过对半球 Ω 上的大量方向进行离散采样并对其辐射度取平均值,来计算每个输出采样方向 wo 的积分。用来采样方向 wi 的半球,要面向卷积的输出采样方向 wo 。
这里的 p 都认为在立方体的中心

这个预计算的立方体贴图,在每个采样方向 wo 上存储其积分结果,可以理解为场景中所有能够击中面向 wo 的表面的间接漫反射光的预计算总和。这样的立方体贴图被称为辐照度图,因为经过卷积计算的立方体贴图能让我们从任何方向有效地直接采样场景(预计算好的)辐照度。
辐射方程也依赖了位置 p,不过这里我们假设它位于辐照度图的中心。这就意味着所有漫反射间接光只能来自同一个环境贴图,这样可能会破坏现实感(特别是在室内)。渲染引擎通过在场景中放置多个反射探针来解决此问题,每个反射探针单独预计算其周围环境的辐照度图。这样,位置 p 处的辐照度(以及辐射度)是取离其最近的反射探针之间的辐照度(辐射度)内插值。目前,我们假设总是从中心采样环境贴图,把反射探针的讨论留给后面的教程。

HDR
既然现在是用贴图来存一个计算结果,而且是基于物理的计算结果,那么这个计算结果就有可能大于 1
所以用传统的 0 到 1 的贴图来存是不行的,所以要用一个能够存大于 1 的文件格式,也就是 HDR
辐射度文件的格式(扩展名为 .hdr)存储了一张完整的立方体贴图,所有六个面数据都是浮点数,允许指定 0.0 到 1.0 范围之外的颜色值,以使光线具有正确的颜色强度。这个文件格式使用了一个聪明的技巧来存储每个浮点值:它并非直接存储每个通道的 32 位数据,而是每个通道存储 8 位,再以 alpha 通道存放指数——虽然确实会导致精度损失,但是非常有效率,不过需要解析程序将每种颜色重新转换为它们的浮点数等效值。
球状的贴图:
水平视角附近分辨率较高,而底部和顶部方向分辨率较低,在大多数情况下,这是一个不错的折衷方案,因为对于几乎所有渲染器来说,大部分有意义的光照和环境信息都在水平视角附近方向。
从等距柱状投影到立方体贴图
球到平面投影称为等距柱状投影
对等距柱状投影采样贵于对立方体贴图采样
所以先把等距柱状投影投影到立方体贴图
具体来说,就是把 hdr 作为 sampler2d
以标准化之后的视线方向的 xy 作为 hdr 贴图的 uv,去采样 hdr
得到的颜色就是要渲染到立方体贴图上的
渲染 6 次,每次转一个视角,帧缓冲的颜色附件绑定到立方体贴图的 GL_TEXTURE_CUBE_MAP_POSITIVE_X + i,渲染一遍,渲染结果输出到颜色附件,也就保存到了立方体贴图的 GL_TEXTURE_CUBE_MAP_POSITIVE_X + i
漫反射立方体环境贴图求卷积
前面不是说要做卷积嘛
也就是切线空间中确定采样点方向,然后转化到世界空间,然后对立方体贴图在这个方向上采样,重复若干次,得到平均值
现在我们要渲染卷积的立方体贴图
也是跟之前球面贴图渲染到立方体贴图一样
渲染 6 次,每次转一个视角,帧缓冲的颜色附件绑定到立方体贴图的 GL_TEXTURE_CUBE_MAP_POSITIVE_X + i,渲染一遍,渲染结果输出到颜色附件,也就保存到了立方体贴图的 GL_TEXTURE_CUBE_MAP_POSITIVE_X + i
有点不同的就是这里的卷积输出的尺寸是 32 * 32 的
得到了这个卷积的贴图就可以用在 PBR shader 中,乘在 diffuse 上
镜面反射部分
对于镜面部分
L o ( p , w o ) = ∫ Ω k s D F G 4 ( w o ⋅ n ) ( w i ⋅ n ) L i ( p , w i ) n ⋅ w i d w i L_o(p,w_o) = \int_{\Omega}k_s\dfrac{DFG}{4(w_o\cdot n)(w_i\cdot n)}L_i(p,w_i) n \cdot w_i \mathrm d w_i Lo(p,wo)=∫Ωks4(wo⋅n)(wi⋅n)DFGLi(p,wi)n⋅widwi
对于每一个输出方向 wo 他这里认为是要求这个积分的卷积的话,需要考虑到每一个 wo 和每一个 wi 的组合?
一开始我不太懂,这个积分式中的 wo 不是相当于一个常数吗,不是只有 wi 才是积分变量吗?
其实他这里确实,wi 是积分变量,但是他是要用 wo 去查询的,也就是说,对于某一个片元来说,某个片元具有一个 wo,那么就要去一个函数里面根据 wo 和 wi 查,那么函数就需要包括 wo 和 wi 两方面的信息
而之前那个漫反射的,就是因为积分式与 wo 无关,所以即使每一个片元的 wo 不一样,都只需要知道 wi 就行了
分割求和近似法
Epic Games 的分割求和近似法将预计算分成两个单独的部分求解,再将两部分组合起来得到后文给出的预计算结果。分割求和近似法将镜面反射积分拆成两个独立的积分:
L o ( p , w o ) = ∫ Ω k s D F G 4 ( w o ⋅ n ) ( w i ⋅ n ) L i ( p , w i ) n ⋅ w i d w i = ∫ Ω k s f r ( p , w i , w o ) L i ( p , w i ) n ⋅ w i d w i L_o(p,w_o) = \int_{\Omega}k_s\dfrac{DFG}{4(w_o\cdot n)(w_i\cdot n)}L_i(p,w_i) n \cdot w_i \mathrm d w_i = \int_{\Omega}k_sf_r(p,w_i,w_o)L_i(p,w_i) n \cdot w_i \mathrm d w_i Lo(p,wo)=∫Ωks4(wo⋅n)(wi⋅n)DFGLi(p,wi)n⋅widwi=∫Ωksfr(p,wi,wo)Li(p,wi)n⋅widwi
f r ( p , w i , w o ) = D F G 4 ( w o ⋅ n ) ( w i ⋅ n ) f_r(p,w_i,w_o) = \dfrac{DFG}{4(w_o\cdot n)(w_i\cdot n)} fr(p,wi,wo)=4(wo⋅n)(wi⋅n)DFG
拆分:
L o ( p , w o ) = ∫ Ω L i ( p , w i ) d w i ∗ ∫ Ω f r ( p , w i , w o ) n ⋅ w i d w i L_o(p,w_o) =\int_{\Omega}L_i(p,w_i) \mathrm d w_i * \int_{\Omega}f_r(p,w_i,w_o)n \cdot w_i \mathrm d w_i Lo(p,wo)=∫ΩLi(p,wi)dwi∗∫Ωfr(p,wi,wo)n⋅widwi
卷积的第一部分被称为预滤波环境贴图,它类似于辐照度图,是预先计算的环境卷积贴图,但这次考虑了粗糙度。因为随着粗糙度的增加,参与环境贴图卷积的采样向量会更分散,导致反射更模糊,所以对于卷积的每个粗糙度级别,我们将按顺序把模糊后的结果存储在预滤波贴图的 mipmap 中。例如,预过滤的环境贴图在其 5 个 mipmap 级别中存储 5 个不同粗糙度值的预卷积结果,如下图所示:

我们使用 Cook-Torrance BRDF 的法线分布函数(NDF)生成采样向量及其散射强度,该函数将法线和视角方向作为输入。由于我们在卷积环境贴图时事先不知道视角方向,因此 Epic Games 假设视角方向——也就是镜面反射方向——总是等于输出采样方向ωo,以作进一步近似。翻译成代码如下:
vec3 N = normalize(w_o);
vec3 R = N;
vec3 V = R;
这样,预过滤的环境卷积就不需要关心视角方向了。这意味着当从如下图的角度观察表面的镜面反射时,得到的掠角镜面反射效果不是很好(图片来自文章《Moving Frostbite to PBR》)。然而,通常可以认为这是一个体面的妥协:

等式的第二部分等于镜面反射积分的 BRDF 部分。如果我们假设每个方向的入射辐射度都是白色的(因此L(p,x)=1.0 ),就可以在给定粗糙度、光线 ωi 法线 n 夹角 n⋅ωi的情况下,预计算 BRDF 的响应结果。Epic Games 将预计算好的 BRDF 对每个粗糙度和入射角的组合的响应结果存储在一张 2D 查找纹理(LUT)上,称为BRDF积分贴图。2D 查找纹理存储是菲涅耳响应的系数(R 通道)和偏差值(G 通道),它为我们提供了分割版镜面反射积分的第二个部分:
生成查找纹理的时候,我们以 BRDF 的输入n⋅ωi(范围在 0.0 和 1.0 之间)作为横坐标,以粗糙度作为纵坐标。有了此 BRDF 积分贴图和预过滤的环境贴图,我们就可以将两者结合起来,以获得镜面反射积分的结果:
一开始我不懂为什么是 NdotV 和 roughness 作为采样的?为什么不是 wi 和 wo 作为坐标
之后才知道,原来他前面说的令 wo 等于 wi 就是指的是 BRDF 这一部分的
所以现在 wo 已知了
所以现在 fr 主要是描述微表面的那个 DFG,其中需要一个粗糙度,还需要一个 wi 所以最终是 NdotV 和 roughness
float lod = getMipLevelFromRoughness(roughness);
vec3 prefilteredColor = textureCubeLod(PrefilteredEnvMap, refVec, lod);
vec2 envBRDF = texture2D(BRDFIntegrationMap, vec2(NdotV, roughness)).xy;
vec3 indirectSpecular = prefilteredColor * (F * envBRDF.x + envBRDF.y)
至此,你应该对 Epic Games 的分割求和近似法的原理,以及它如何近似求解反射方程的间接镜面反射部分有了一些基本印象。让我们现在尝试一下自己构建预卷积部分。
镜面反射立方体环境贴图求卷积
现在是对于
L o ( p , w o ) = ∫ Ω L i ( p , w i ) d w i ∗ ∫ Ω f r ( p , w i , w o ) n ⋅ w i d w i L_o(p,w_o) =\int_{\Omega}L_i(p,w_i) \mathrm d w_i * \int_{\Omega}f_r(p,w_i,w_o)n \cdot w_i \mathrm d w_i Lo(p,wo)=∫ΩLi(p,wi)dwi∗∫Ωfr(p,wi,wo)n⋅widwi
中的第一部分,构建镜面反射立方体环境贴图的卷积
得到的结果叫作 预滤波环境贴图
前面讲过,使用 mipmap 的形式存储,mipmap 的每一级对应一个粗糙度
越粗糙的 mipmap 等级越高,分辨率越低,刚好,粗糙的效果不需要高分辨率的贴图
之前我们在漫反射这里是对半球上均匀随机方向采样再平均作为卷积
但是这是因为漫反射的反射方向是半球上均匀随机方向的,而镜面反射部分的光线并不是的,它的反射方向是有形状的

所有可能出射的反射光构成的形状称为镜面波瓣。随着粗糙度的增加,镜面波瓣的大小增加;随着入射光方向不同,形状会发生变化。因此,镜面波瓣的形状高度依赖于材质。 在微表面模型里给定入射光方向,则镜面波瓣指向微平面的半向量的反射方向。考虑到大多数光线最终会反射到一个基于半向量的镜面波瓣内,采样时以类似的方式选取采样向量是有意义的,因为大部分其余的向量都被浪费掉了,这个过程称为重要性采样。
蒙特卡罗积分
O = ∫ a b f ( x ) d x = 1 N ∑ i = 0 N − 1 f ( x ) p d f ( x ) O = \int_a^bf(x)\mathrm d x = \dfrac{1}{N}\sum_{i=0}^{N-1}\dfrac{f(x)}{\mathrm{pdf}(x)} O=∫abf(x)dx=N1i=0∑N−1pdf(x)f(x)
无偏样本
有偏样本 收敛更快 可能不收敛到精确解
生成随机数的方法
低差异序列 生成的随机数更加均匀
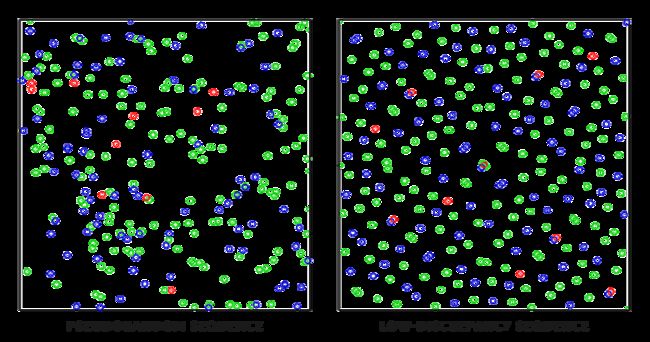
当使用低差异序列生成蒙特卡洛样本向量时,该过程称为拟蒙特卡洛积分。拟蒙特卡洛方法具有更快的收敛速度,这使得它对于性能繁重的应用很有用。
重要性采样
镜面波瓣外的任何(拟)随机生成的样本与镜面积分无关,因此将样本集中在镜面波瓣内生成是有意义的,但代价是蒙特卡洛估算会产生偏差。
本质上来说,这就是重要性采样的核心:只在某些区域生成采样向量,该区域围绕微表面半向量,受粗糙度限制。通过将拟蒙特卡洛采样与低差异序列相结合,并使用重要性采样偏置样本向量的方法,我们可以获得很高的收敛速度。因为我们求解的速度更快,所以要达到足够的近似度,我们所需要的样本更少。因此,这套组合方法甚至可以允许图形应用程序实时求解镜面积分,虽然比预计算结果还是要慢得多。
预过滤卷积的伪像
当前的预过滤贴图可以在大多数情况下正常工作,不过你迟早会遇到几个与预过滤卷积直接相关的渲染问题。我将在这里列出最常见的一些问题,以及如何修复它们。
高粗糙度的立方体贴图接缝
因为生成的预卷积的贴图,越粗糙:mipmap 等级越高,代表着贴图分辨率越低,同时重要性采样中的波瓣越大,因此缺乏立方体的面和面之间的滤波的问题就更明显
幸运的是,OpenGL 可以启用 GL_TEXTURE_CUBE_MAP_SEAMLESS,以为我们提供在立方体贴图的面之间进行正确过滤的选项:
glEnable(GL_TEXTURE_CUBE_MAP_SEAMLESS);
预过滤卷积的亮点
由于镜面反射中光强度的变化大,高频细节多,所以对镜面反射进行卷积需要大量采样,才能正确反映 HDR 环境反射的混乱变化。我们已经进行了大量的采样,但是在某些环境下,在某些较粗糙的 mip 级别上可能仍然不够(就是说缩的不够小,高频细节去掉的不够充分),导致明亮区域周围出现点状图案:
一种解决方案是进一步增加样本数量,但在某些情况下还是不够。另一种方案如 Chetan Jags 所述,我们可以在预过滤卷积时,不直接采样环境贴图,而是基于积分的 PDF 和粗糙度采样环境贴图的 mipmap ,以减少伪像:
“基于积分的 PDF 和粗糙度采样环境贴图的 mipmap”就是说主动去采低频的信息
预计算 BRDF
前面我们 BRDF 的式子为
f r ( p , w i , w o ) = D F G 4 ( w o ⋅ n ) ( w i ⋅ n ) f_r(p,w_i,w_o) = \dfrac{DFG}{4(w_o\cdot n)(w_i\cdot n)} fr(p,wi,wo)=4(wo⋅n)(wi⋅n)DFG
现在要算
L o ( p , w o ) = ∫ Ω L i ( p , w i ) d w i ∗ ∫ Ω f r ( p , w i , w o ) n ⋅ w i d w i L_o(p,w_o) =\int_{\Omega}L_i(p,w_i) \mathrm d w_i * \int_{\Omega}f_r(p,w_i,w_o)n \cdot w_i \mathrm d w_i Lo(p,wo)=∫ΩLi(p,wi)dwi∗∫Ωfr(p,wi,wo)n⋅widwi
的第二部分
文章里面算了一堆,把 F 从 BRDF 中提取了出来,我不知道是干啥
之后的数学计算我也懒得复制了……