数据仓库概念扫盲,kimball和Inmon两大派系在争什么?
本文,是为了让大家更好的理解大数据经典架构的补充内容,主要介绍一下数据仓库相关的内容。

数据仓库(Data Warehouse,DW):由两个主要部分构成(一个整合的决策支持数据库 + 一个收集、清洗、转换、存储来自于各种外部数据源数据的相关软件程序),两者结合以支持历史的、分析的和商务智能需求。
企业数据仓库(Enterprise Data Warehouse,EDW):是服务于整个企业商务智能需要的集中式数据仓库。企业数据仓库遵循企业数据模型,使得整个企业范围内的决策支持活动可以保持一致。
一个数据仓库也可能包括若干相关的数据集市,他们都是数据仓库的子集副本
数据仓库活动专注于实现一个历史的业务上下文,包括业务规则,同时保证与元数据存储库交互的流程。
数据仓库活动提供技术解决方案以支持商务智能(BI),“商务智能”是多种业务能力的集合,具体包括:
-
知识工作者执行查询、分析和报表活动,用于监控和了解企业财务运营情况,支持决策制定
-
基于企业操作型数据的战略/运营分析和报表,从而支持业务决策、风险管理、合规管理
-
查询/分析和报表相关的流程和规程
-
商务智能软件工具的细分市场、决策支持系统的同义词、商务智能环境的代名词
数据仓库和商务智能管理的目标:
| 软件 环境 |
为数据获取、数据管理和数据访问提供稳定、高效、可靠的环境。 提供易于使用的、灵活的和全面的数据访问环境。 定义、构建并维护所有数据存储、数据处理过程,数据基础设施和数据工具,在系统输出后经过整合和精细化处理的数据可以用于信息查看、分析或者满足数据请求 |
| 数据 服务 |
为所有合适的访问形式提供可信的、高质量的数据。 在内容和内容访问方面,与组织目标相适应,以增量方式交付。 对所需的当前和历史数据提供整合的数据存储,并按照主题域组织数据。 交付数据时,关注如何支持数据治理所发起的决策、政策、流程、定义以及标准等。 整合商务智能处理过程所发现的新数据到数据仓库,使其为进一步分析和商务智能所用。 |
| 外部 支撑 |
要借助其他相关的数据管理职能,如参考数据/主数据/元数据管理、数据治理、数据质量管理,而不重复建设。 |

几个必须知道的概念:
1、报表数据库和业务数据库的区别
区分数仓和业务应用库表设计的不同,是实施数仓的第一步。
同时牢记:数仓是面向主题,集成的,不可更新的,随时间不断变化的。
| 业务 数据库 |
用于减少冗余和提高精度 。 适合于数据的写入和更新而不是数据的读取。 数据被细分为很多表(为了消除冗余),大查询执行起来较慢 |
| 报表 数据库 |
报表型数据源通常使用星型结构布局。所有事务型数据,大部分数值型数据存储在事实表中,所有的参考数据,例如产品信息等,存储在独立的维度表中。 星型结构数据库比完全标准化数据库含有的表少,查询性能更快。 |
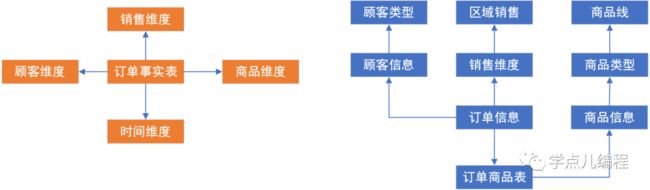
2、维度
维度是一个与业务相关的观察角度,依赖于数据的有效性和表达业务成效的关键指标。一个经典的维度描述是:什么时间(when),谁(who)在哪里(where)做了什么事(what),其间描述了四个维度。
所有维度在一起提供了业务的多维视图。这个多维视图的数据被存为一个立方体。一个维度可下设若干层。如地区维度下可以有地域、国家、办事处、销售员4层。
3、度量
度量也叫事实,是用于评价业务状况的数值型数据。如销售额、成本、利润、库存量、交易数(关联想像一下度量衡)。
在企业活动中通常是通过如销售额、费用、库存量和定额一类的关键性能指标,度量来监测业务的成效。
不同的度量反映出不同的业务性质。度量之间相互独立。
度量是业务量化的表示。
4、多维分析
从多个维度分析某个度量指标。
![]()
5、维度、层、类别
一图胜千言,请看图![]()


数据仓库圈内,存在 inmon和kimball 两大派系。
1、kimball数据仓库架构
Kimball架构是一种自下而上的架构,它认为数据仓库是一系列数据集市的集合。企业可以通过一系列维数相同的数据集市递增地构建数据仓库,通过使用一致的维度,能够共同看到不同数据集市中的信息,这表示它们拥有公共定义的元素。
kimball数据仓库四部分组成:操作型源系统、ETL系统、数据展示(我觉得用数据组织更合适一些)和商业应用,架构图如下:
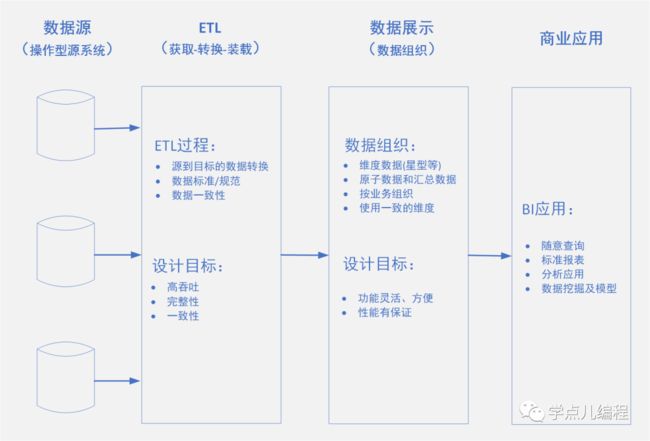
操作型源系统 |
记录操作型系统,用于获取业务事务。 源系统位于数据仓库之外,提供的数据仓库需要的基础数据,系统不能控制源系统数据格式和内容。 源系统一般不维护历史信息,数据仓库的责任是更好的承担源系统过去情况的责任,并依据业务需求实现源系统数据不能实现的查询场景。 |
ETL系统(获取-转换-加载) |
ETL系统处于操作型源系统和数据仓库展现(数据组织)之间,包括数据获取、转换和加载。 数据获取:将数据从操作型系统导入数据仓库环境,将需要的数据复制到ETL系统进行后续数据处理操作。 数据转换:对读取的操作型源系统数据进行清洗数据(消除拼写错误、处理错误元素、解析规范数据标准格式等)、合并来自不同数据源数据。 数据加载:将处理完成的数据加载到展现区域的目标维度模型中。数据加载过程中主要是划分维度表和事实表(包括:代理键设置、增加适当描述、拆分或组合列以提供需要的数据值、形成扁平大表)。
数据通过ETL系统处理,增加数据利用价值,同时可以进行元数据诊断,逐步改进源系统数据质量。 |
数据展现区(数据组织) |
展现区数据以维度模型展现,采用星型模式或OLAP多维数据库,以支撑商业智能的需求。 为满足用户无法预期的、随意查询,必须使用原子数据。 同时,为提高性能会存储部分聚合数据。
提供各种细节数据方便用户上卷解决实际问题。
|
| 商业智能(BI) | 用户利用展现区制定分析决策能力。 |
2、inmon架构
Bill Inmon(被称为数据仓库之父)提倡 企业信息工厂
(corporateinformation factory,CIF),下图是简化版CIF。
![]()
数据获取 |
获取各种操作源系统数据,按照3NF标准对获取的数据进行拆分(依托ETL系统),形成企业数据仓库中的规范表
|
数据发布 |
根据不同主题,对EDW中的数据按照维度模型拆分,结合部门、主题场景对EDW中的数据进行统计分析,保存到各个集市中,提供BI应用使用。 EDW中保留的是原子数据,支撑BI下钻直接查询原子数据。 |
inmon主张自上而下的架构:
(1)不同的业务数据 集中到 面向主题、集成的、不易失的和随时间变化的结构中。既可以下钻到最细层,也可上卷到汇总层。
-
数据集市应该是数据仓库的子集,
-
每个数据集市是针对独立部门特殊设计的。
(2)inmon将数据仓库定义为整个企业级的集中存储库,数据仓库存放着最低的详细级别的原子数据。维度数据集市只是在数据仓库完成以后才创建的。因此,数据仓库是企业信息工厂(CIF)的中心,它为交付商务智能提供逻辑框架。

两大派系对优缺点总结
Inmon架构:核心是要求规范化表,需要用大量的时间来梳理和设计数据表结构,但如果规范化数据仓库一旦建立好了,则以后数据就更易于管理。而且由于开发人员不能直接使用其中心数据库,更加确保了数据质量,中心数据库是采用规范化设计的,冗余情况也会更少。
kimball架构:对数据表结构没有强规范型要求,数据仓库的建设相对较快,适用于业务变化比较频繁的情况,对开发人员的要求也不是很高。
从实施角度,两种架构的对比分析如下:
| inmon架构 | kimball架构 | |
| 建设周期 | 花费大量时间 | 花费相对较少时间 |
| 建设成本 | 初期投入大,后期投入少。 | 初期投入较少, 后续需长期投入。 |
| 人员要求 | 专家团队 | 一般开发团队 |
| 维护难度 | 容易 | 困难 (字段冗余,数据不稳定) |
| 适合场景 | 业务模式较固定 | 业务变化较频繁 |

大数据常用架构、数据仓库介绍完了,后面咱们开始讨论经典大数据组件了。动物园管理员,走起! 敬请期待!
如果觉得这篇文章对您有帮助,欢迎关注公众号 “学点儿编程”,公众号不断推送干货文章!
