OpenCV实例(八)车牌字符识别技术(三)汉字识别
车牌字符识别技术(三)汉字识别
- 1.代码实例
- 2.遇到问题
- 3.汉字识别代码实例
相较于数字和英文字符的识别,汽车牌照中的汉字字符识别的难度更大,主要原因有以下4个方面:
(1)字符笔画因切分误差导致非笔画或笔画流失。
(2)汽车牌照被污染导致字符上出现污垢。
(3)采集所得车辆图像分辨率低导致多笔画的汉字较难分辨。
(4)车辆图像采集时所受光照影响的差异导致笔画较淡。
综合汉字识别时的这些难点来看,很难被直接提取的是字符的局部特征。笔画作为最重要的特征而仅存在于汉字中,这由先验知识可知。一旦捺、横、竖、撇这些笔画特征被提取到,对于汉字字符识别的工作就完成了许多。在水平方向上,横笔画的灰度值的波动表现为低频,竖笔画的灰度变化表现为低频;在垂直方向上,横笔画的灰度变化表现为高频,竖笔画的灰度变化表现为高频。在汉字字符特征的提取过程中,对于小波的多分辨率特性的利用显然是一个不错的选择。
对于汉字进识别的相关工作,在一系列对图像进行预处理以及对图像的特征进行提取等相关操作后就可以进行了。第一步是预处理原始图像;第二步是对字符的原始特征进行提取(主要通过小波变换进行),并降维处理原始特征(主要采用线性判别式分析(LDA)变换矩阵进行),获取字符的最终特征;第三步是在特征模板匹配和最小距离分类器中读入获取所得到的最终特征,得到字符的最终识别结果。
1.代码实例
中文车牌的识别(包括新能源汽车)
import cv2 as cv
from PIL import Image
import pytesseract as tess
def recoginse_text(image):
"""
步骤:
1、灰度,二值化处理
2、形态学操作去噪
3、识别
:param image:
:return:
"""
# 灰度 二值化
gray = cv.cvtColor(image,cv.COLOR_BGR2GRAY)
# 如果是白底黑字 建议 _INV
ret,binary = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV| cv.THRESH_OTSU)
# 形态学操作 (根据需要设置参数(1,2))
kernel = cv.getStructuringElement(cv.MORPH_RECT,(1,2)) #去除横向细线
morph1 = cv.morphologyEx(binary,cv.MORPH_OPEN,kernel)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 1)) #去除纵向细线
morph2 = cv.morphologyEx(morph1,cv.MORPH_OPEN,kernel)
cv.imshow("Morph",morph2)
# 黑底白字取非,变为白底黑字(便于pytesseract 识别)
cv.bitwise_not(morph2,morph2)
textImage = Image.fromarray(morph2)
# 图片转文字
text=tess.image_to_string(textImage)
n=10 #根据不同国家车牌固定数目进行设置
print("识别结果:")
print(text[1:n])
def main():
# 读取需要识别的数字字母图片,并显示读到的原图
src = cv.imread("cp.jpg")
cv.imshow("src",src)
# 识别
recoginse_text(src)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__=="__main__":
main()
2.遇到问题

No module named ‘pytesseract’
缺少pytesseract 模块。
在环境中安装该模块
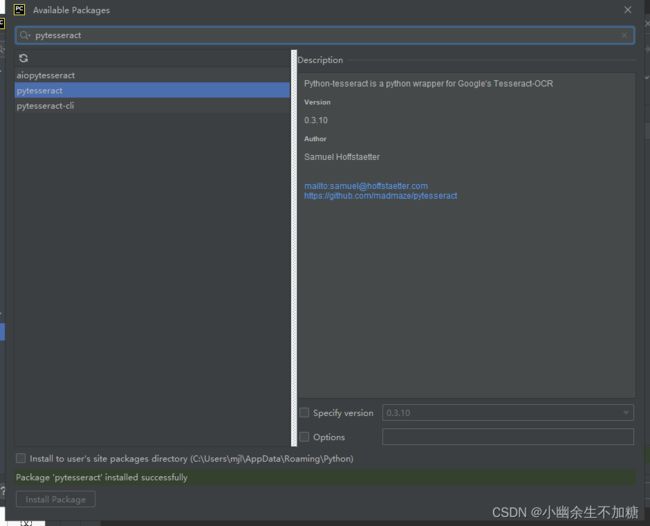
安装完成运行程序,结果又出现了一堆问题:
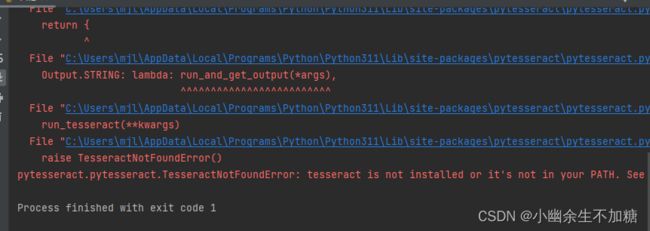
原因是没有安装pytesseract需要的Tesseract-OCR工具,Windows版本的安装包的下载路径为https://github.com/UB-Mannheim/tesseract/wiki
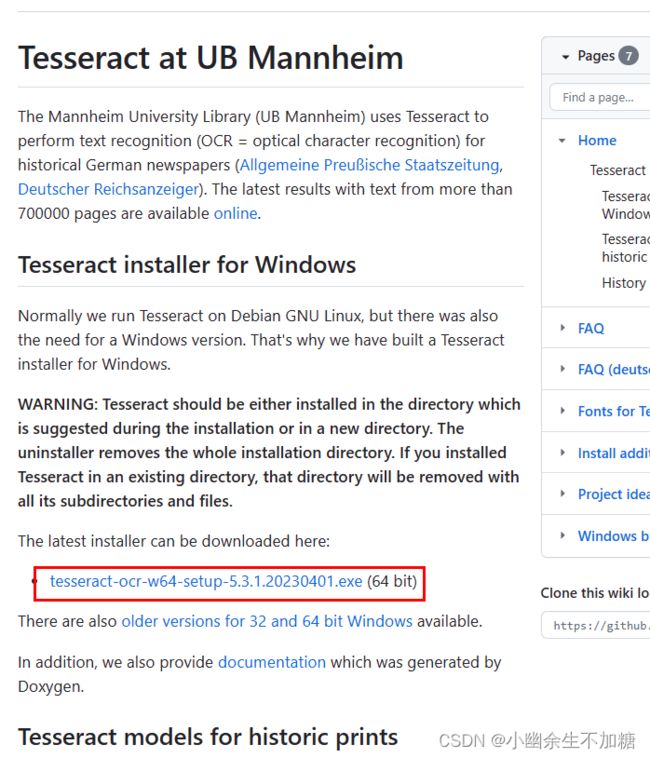
直接双击该文件进行安装即可。这里的安装位置(这个路径要记住,后面要用)采用默认值:
C:\Program Files\Tesseract-OCR
配置pytesseract.py打开“我的计算机”,进入\Users==\AppData\Local\Programs\Python\Python38\Lib\site-packages\pytesseract\,找到pytesseract.py文件,用文本编辑器打开这个文件,找到"tesseract_cmd"关键字

至此,字符识别开发环境准备好了,下面就可以编写代码了。
代码实例:
import cv2 as cv
from PIL import Image
import pytesseract as tess
def recoginse_text(image):
"""
步骤:
1、灰度,二值化处理
2、形态学操作去噪
3、识别
:param image:
:return:
"""
# 灰度 二值化
gray = cv.cvtColor(image,cv.COLOR_BGR2GRAY)
# 如果是白底黑字 建议 _INV
ret,binary = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV| cv.THRESH_OTSU)
# 形态学操作 (根据需要设置参数(1,2))
kernel = cv.getStructuringElement(cv.MORPH_RECT,(1,2)) #去除横向细线
morph1 = cv.morphologyEx(binary,cv.MORPH_OPEN,kernel)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 1)) #去除纵向细线
morph2 = cv.morphologyEx(morph1,cv.MORPH_OPEN,kernel)
cv.imshow("Morph",morph2)
# 黑底白字取非,变为白底黑字(便于pytesseract 识别)
cv.bitwise_not(morph2,morph2)
textImage = Image.fromarray(morph2)
# 图片转文字
text=tess.image_to_string(textImage)
n=10 #根据不同国家车牌固定数目进行设置
print("识别结果:")
print(text[1:n])
def main():
# 读取需要识别的数字字母图片,并显示读到的原图
src = cv.imread("cp.jpg")
cv.imshow("src",src)
# 识别
recoginse_text(src)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__=="__main__":
main()
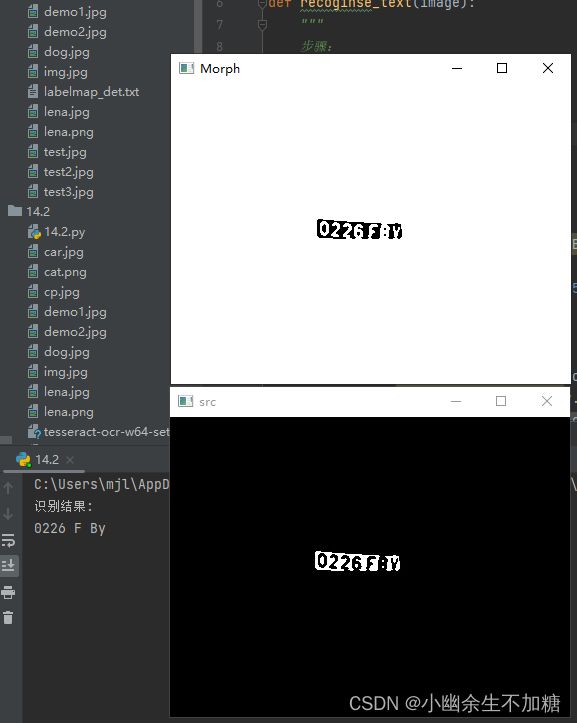
3.汉字识别代码实例
代码实例
import tkinter as tk
from tkinter.filedialog import *
from tkinter import ttk
import predict
import cv2
from PIL import Image, ImageTk
import threading
import time
class Surface(ttk.Frame):
pic_path = ""
viewhigh = 600
viewwide = 600
update_time = 0
thread = None
thread_run = False
camera = None
color_transform = {"green":("绿牌","#55FF55"), "yello":("黄牌","#FFFF00"), "blue":("蓝牌","#6666FF")}
def __init__(self, win):
ttk.Frame.__init__(self, win)
frame_left = ttk.Frame(self)
frame_right1 = ttk.Frame(self)
frame_right2 = ttk.Frame(self)
win.title("车牌识别")
win.state("zoomed")
self.pack(fill=tk.BOTH, expand=tk.YES, padx="5", pady="5")
frame_left.pack(side=LEFT,expand=1,fill=BOTH)
frame_right1.pack(side=TOP,expand=1,fill=tk.Y)
frame_right2.pack(side=RIGHT,expand=0)
ttk.Label(frame_left, text='原图:').pack(anchor="nw")
ttk.Label(frame_right1, text='车牌位置:').grid(column=0, row=0, sticky=tk.W)
from_pic_ctl = ttk.Button(frame_right2, text="来自图片", width=20, command=self.from_pic)
from_vedio_ctl = ttk.Button(frame_right2, text="来自摄像头", width=20, command=self.from_vedio)
self.image_ctl = ttk.Label(frame_left)
self.image_ctl.pack(anchor="nw")
self.roi_ctl = ttk.Label(frame_right1)
self.roi_ctl.grid(column=0, row=1, sticky=tk.W)
ttk.Label(frame_right1, text='识别结果:').grid(column=0, row=2, sticky=tk.W)
self.r_ctl = ttk.Label(frame_right1, text="")
self.r_ctl.grid(column=0, row=3, sticky=tk.W)
self.color_ctl = ttk.Label(frame_right1, text="", width="20")
self.color_ctl.grid(column=0, row=4, sticky=tk.W)
from_vedio_ctl.pack(anchor="se", pady="5")
from_pic_ctl.pack(anchor="se", pady="5")
self.predictor = predict.CardPredictor()
self.predictor.train_svm()
def get_imgtk(self, img_bgr):
img = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
im = Image.fromarray(img)
imgtk = ImageTk.PhotoImage(image=im)
wide = imgtk.width()
high = imgtk.height()
if wide > self.viewwide or high > self.viewhigh:
wide_factor = self.viewwide / wide
high_factor = self.viewhigh / high
factor = min(wide_factor, high_factor)
wide = int(wide * factor)
if wide <= 0 : wide = 1
high = int(high * factor)
if high <= 0 : high = 1
im=im.resize((wide, high), Image.ANTIALIAS)
imgtk = ImageTk.PhotoImage(image=im)
return imgtk
def show_roi(self, r, roi, color):
if r :
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
roi = Image.fromarray(roi)
self.imgtk_roi = ImageTk.PhotoImage(image=roi)
self.roi_ctl.configure(image=self.imgtk_roi, state='enable')
self.r_ctl.configure(text=str(r))
self.update_time = time.time()
try:
c = self.color_transform[color]
self.color_ctl.configure(text=c[0], background=c[1], state='enable')
except:
self.color_ctl.configure(state='disabled')
elif self.update_time + 8 < time.time():
self.roi_ctl.configure(state='disabled')
self.r_ctl.configure(text="")
self.color_ctl.configure(state='disabled')
def from_vedio(self):
if self.thread_run:
return
if self.camera is None:
self.camera = cv2.VideoCapture(0)
if not self.camera.isOpened():
mBox.showwarning('警告', '摄像头打开失败!')
self.camera = None
return
self.thread = threading.Thread(target=self.vedio_thread, args=(self,))
self.thread.setDaemon(True)
self.thread.start()
self.thread_run = True
def from_pic(self):
self.thread_run = False
self.pic_path = askopenfilename(title="选择识别图片", filetypes=[("jpg图片", "*.jpg")])
if self.pic_path:
img_bgr = predict.imreadex(self.pic_path)
self.imgtk = self.get_imgtk(img_bgr)
self.image_ctl.configure(image=self.imgtk)
resize_rates = (1, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4)
for resize_rate in resize_rates:
print("resize_rate:", resize_rate)
try:
r, roi, color = self.predictor.predict(img_bgr, resize_rate)
except:
continue
if r:
break
#r, roi, color = self.predictor.predict(img_bgr, 1)
self.show_roi(r, roi, color)
@staticmethod
def vedio_thread(self):
self.thread_run = True
predict_time = time.time()
while self.thread_run:
_, img_bgr = self.camera.read()
self.imgtk = self.get_imgtk(img_bgr)
self.image_ctl.configure(image=self.imgtk)
if time.time() - predict_time > 2:
r, roi, color = self.predictor.predict(img_bgr)
self.show_roi(r, roi, color)
predict_time = time.time()
print("run end")
def close_window():
print("destroy")
if surface.thread_run :
surface.thread_run = False
surface.thread.join(2.0)
win.destroy()
if __name__ == '__main__':
win=tk.Tk()
surface = Surface(win)
win.protocol('WM_DELETE_WINDOW', close_window)
win.mainloop()
输出结果:
