运维视角:rabbitmq教程(四)工作模式
今天这篇文章,通过python代码来测试rabbitmq交换机以及队列的工作模式,以此更加透彻的理解它的工作方式
一、简单模式
1、测试代码
生产者代码:
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.queue_declare(queue='hello') # 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作
for i in range(3):
new_dic = {"name"+str(i): ""+str(i)}
# channel.basic_publish(exchange='', routing_key='hello', body=b'hello world_'+str(i).encode('utf-8'))
channel.basic_publish(exchange='', routing_key='hello', body=str(new_dic).encode('utf-8'))
# print("send success...")
connection.close() # 关闭连接
消费者代码:
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.queue_declare(queue='hello')
# 回调函数
def callback(ch, method, properties, body):
# print('消费者收到:{}'.format(body))
print(body.decode('utf-8'))
channel.basic_consume(queue='hello', # 接收指定queue的消息
auto_ack=True, # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息
on_message_callback=callback # 设置收到消息的回调函数
)
channel.start_consuming() # 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
如果再运行一个消费者(两个消费者),当有生产者生产消息的时候,会出现轮训的效果,即,每个消费者消费一个消息;
2、消息确认
当处理一个比较耗时得任务的时候,你也许想知道消费者(consumers)是否运行到一半就挂掉。当前的代码中,当消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除;这种情况,你只要把一个工作者(worker)停止,正在处理的消息就会丢失。同时,所有发送到这个工作者的还没有处理的消息都会丢失。
证实该现象的测试:
往一个队列中存储了100个消息,开启一个消费者工作,中途模拟消费者中断或崩溃。终端查询队列,消息显示为0;队列将100个消息发个消费者,不管消费者是否正确处理,就直接删除了这些消息,不做存留;
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
消息是没有超时这个概念的;当工作者与它断开连的时候,RabbitMQ会重新发送消息。这样在处理一个耗时非常长的消息任务的时候就不会出问题了。
在消费者回调函数中添加 basic_ack 方法,示例:
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(1)
ch.basic_ack(delivery_tag=method.delivery_tag) # 消息确认
basic_ack 不可与 auto_ack 一同使用,会报错
3、持久化
——队列持久化
channel.queue_declare(queue='task_queue', durable=True)
在生产者、消费者代码中,添加 durable=True 可以使队列持久化,如:重启rabbitmq后创建的队列不丢失;
[shell]# rabbitmqctl list_queues 查看队列以及消息数量
——消息持久化
channel.basic_publish(exchange='',
routing_key="task_queue",
body=str(new_dic).encode('utf-8'),
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
在生产者代码中,设置 properties 方法值 delivery_mode=2 参数,可以使消息持久化,没有被处理的消息会保存在队列中;
4、公平调度
以上的代码,一直是按照轮训的方式来派发消息的。比如有两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。然而RabbitMQ并不知道这些,它仍然一如既往的派发消息。
可以使用basic.qos方法,并设置prefetch_count=1。这样是告诉RabbitMQ,再同一时刻,不要发送超过1条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
channel.basic_qos(prefetch_count=1)
示例配置:
...
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(1)
ch.basic_ack(delivery_tag=method.delivery_tag) # 消息确认
channel.basic_qos(prefetch_count=1) # 一次性取几个消息
channel.basic_consume('task_queue', callback)
...
二、发布订阅模式
将同一个消息发送给多个消费者;
1.1-生产者代码
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.13', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 创建一个fanout交换机,命名为logs
for i in range(10):
new_dic = {"name" + str(i): "" + str(i)}
channel.basic_publish(exchange='logs', routing_key='', body=str(new_dic).encode('utf-8'))
print(" [x] Sent %r" % new_dic)
connection.close()
1.2-消费者代码一
(临时队列和随机的队列名称)
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 创建一个fanout交换机,命名为logs
result = channel.queue_declare(exclusive=True, queue="") # 临时队列(exclusive=True表示断开连接时,这个队列被删除)
queue_name = result.method.queue # 获取随机队列名
channel.queue_bind(exchange='logs', queue=queue_name) # 将队列和交换机绑定
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(queue_name, callback)
channel.start_consuming()
1.3-消费者代码二
(指定的队列名称)
import pika
import time
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='logs', exchange_type='fanout') # 创建一个fanout交换机,命名为logs
# channel.queue_declare(exclusive=True, queue="bind_queue_test") # 创建一个临时队列(exclusive=True表示断开连接时,这个队列被删除)
channel.queue_declare(queue="bind_queue_test", durable=True) # 创建一个队列
channel.queue_bind(exchange='logs', queue="bind_queue_test") # 将队列和交换机绑定
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume("bind_queue_test", callback)
channel.start_consuming()
2.1-测试结论
发布订阅的方式可以实现将消息同时发给多个消费者;
它是通过扇形交换机(exchange_type=‘fanout’)实现的。扇形交换机会将消息复制发送到与其绑定的队列中,每个队列会同时接到相同的消息;所以【消费者代码一】中创建的队列名称都是临时(独占)、随机的,这样的话,其他消费者就不能消费这个队列,也不会冲突;
当然,也可以创建指定的队列名称并持久化。但是这样的消费者不能是多个,否则在这个队列中就会是轮训的分发消息了;
2.2-验证测试
步骤:
1、运行了一个【消费者代码一】;
2、运行了两个【消费者代码二】:消费者代码A和消费者代码B;
3、运行【生产者代码】;发送 0到9 个消息;
结果:
【消费者代码一】全部接收到了 0-9 个消息;
【消费者代码A】接收到了 0、2、4、6、8;
【消费者代码B】接收到了 1、3、5、7、9;
三、路由模式
生产者和消费者设置 routing_key 参数;路由器通过该参数来判断消息转发给哪个队列;
1.1-生产者
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.13', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='direct_logs', exchange_type='direct') # 创建直连交换机
severity = "error" # 绑定的routing_key
message = "messages test ---- " + severity # 要发送的消息
channel.basic_publish(exchange='direct_logs', routing_key=severity, body=str(message).encode('utf-8'))
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
1.2-消费者一
routing_key 为“info”
import pika
import time
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare(exclusive=True, queue="") # 创建一个临时随机名称的队列(exclusive=True表示断开连接时,这个队列被删除)
queue_name = result.method.queue # 获取随机队列名
severity = "info"
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) # 将队列和交换机绑定
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue_name, callback)
channel.start_consuming()
1.3-消费者二
routing_key 为“error”
import pika
import time
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='direct_logs', exchange_type='direct')
result = channel.queue_declare(exclusive=True, queue="") # 创建一个临时随机名称的队列(exclusive=True表示断开连接时,这个队列被删除)
queue_name = result.method.queue # 获取随机队列名
severity = "error"
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) # 将队列和交换机绑定
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue_name, callback)
channel.start_consuming()
2.1-测试结论
通过设置 routing_key 参数,可以指定消息发送到哪个队列;
验证方法:多个消费者绑定同一个 routing_key;
但是,扇型交换机(fanout exchange)没有足够的灵活性 —— 它能做的仅仅是广播;
通过绑定 routing_key 的方式可以让直连交换机实现类似于扇形交换机发布订阅的效果;(扇形交换机会忽略routing_key这个参数)
2.2-验证测试
步骤:
1、运行消费者一和二;
2、运行生产者;
结果:
当 routing_key 为 info 时,消息发送到了消费者一;当 routing_key 为 error 时,消息发送到了消费者二;
四、主题交换机
主题交换机的路由键必须是一个由.分隔开的词语列表,如:“stock.usd.nyse”, “nyse.vmw”, “quick.orange.rabbit”。词语的个数可以随意,但是不要超过255字节。
● * (星号) 用来表示一个单词.
● # (井号) 用来表示任意数量(零个或多个)单词。
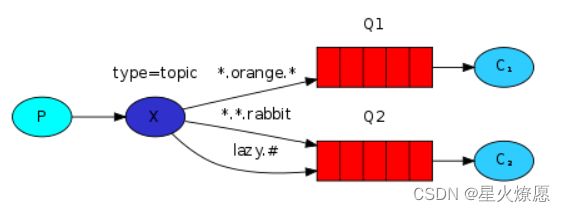
Q1的绑定键为 .orange.,Q2的绑定键为 ..rabbit 和 lazy.#
示例:
携带有 quick.orange.rabbit 的消息将会被分别投递给这两个队列;
携带着 lazy.orange.elephant 的消息同样也会给两个队列都投递过去;
携带有 quick.orange.fox 的消息会投递给第一个队列;
携带有 lazy.brown.fox 的消息会投递给第二个队列;
携带有 lazy.pink.rabbit 的消息只会被投递给第二个队列一次,即使它同时匹配第二个队列的两个绑定;
携带着 quick.brown.fox 的消息不会投递给任何一个队列。
如果我们违反约定,发送了一个携带有一个单词或者四个单词(“orange” or “quick.orange.male.rabbit”)的消息时,发送的消息不会投递给任何一个队列,而且会丢失掉。
但是另一方面,即使 “lazy.orange.male.rabbit” 有四个单词,他还是会匹配最后一个绑定,并且被投递到第二个队列中。
1.1-生产者
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.13', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 创建一个主题交换机
routing_key = "lazy.orange.male.rabbit"
message = "messages test ---- " + routing_key # 要发送的消息
channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=str(message).encode('utf-8'))
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
1.2-消费者一
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.14', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 创建一个主题交换机
result = channel.queue_declare(exclusive=True, queue="") # 创建一个临时随机名称的队列(exclusive=True表示断开连接时,这个队列被删除)
queue_name = result.method.queue # 获取随机队列名
binding_key = "*.orange.*" # 绑定路由
channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) # 将队列和交换机绑定
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue_name, callback)
channel.start_consuming()
1.2-消费者二
import pika
user_info = pika.PlainCredentials('admin', 'admin')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.2.15', '5672', '/', user_info))
channel = connection.channel() # 创建一个channel
channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 创建一个主题交换机
result = channel.queue_declare(exclusive=True, queue="") # 创建一个临时随机名称的队列(exclusive=True表示断开连接时,这个队列被删除)
queue_name = result.method.queue # 获取随机队列名
binding_key = "*.*.rabbit" # 绑定路由
channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) # 将队列和交换机绑定
channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key="lazy.#") # 将队列和交换机绑定,并绑定路由
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body,))
channel.basic_consume(queue_name, callback)
channel.start_consuming()
五、其他
这期的文章主要集中在了python上,编辑python代码来模拟生产者和消费者,以此发送、接收消息,能更加清楚的理解运作原理;
本篇文章中的代码案例部分基于rabbitmq的官方文档,同时也采集、测试了网上其他的代码案例,综合考量,更容易理解;