1. 如何爬取自己的CSDN博客文章列表(获取列表)(博客列表)(手动+python代码方式)
文章目录
-
- 写在最前
- 步骤
-
- 打开chrome浏览器,登录网页
- 按pagedown一直往下刷呀刷呀刷,直到把自己所有的博文刷出来
- 然后我们按F12,点击选取元素按钮
- 然后随便点一篇博文,产生如下所示代码
- 然后往上翻,找到头,复制
- 然后到编辑器里粘贴,然后保存文件为export.html
- 用vscode格式化
- 撰写python代码parse.py
- 将export.html恢复之前的格式
- 执行解析代码
- 查看articles.json文件
- 本篇文章就告一段落了,如有兴趣,可以看我下一篇文章,我们基于本篇文章得到的结果,获取每篇CSDN博文质量分并将列表展示在网页上
下一篇:2. 获取自己CSDN文章列表并按质量分由小到大排序,并展示在网页上(文章质量分、博文质量分)
写在最前
一开始我想弄个python代码,直接爬取https://blog.csdn.net/Dontla?type=blog页面的的所有已发布文章列表,但是貌似爬不到,也不知道是什么原因,可能是大佬做了限制,不让爬。。。
并非做了限制,可以看这篇博客:如何批量查询自己的CSDN博客质量分
我只能想其他办法了,,,
后来想到一个办法,既然不让爬,就自己手工拷贝吧,这还是能做到的。
步骤
打开chrome浏览器,登录网页
https://blog.csdn.net/Dontla?type=blog
按pagedown一直往下刷呀刷呀刷,直到把自己所有的博文刷出来
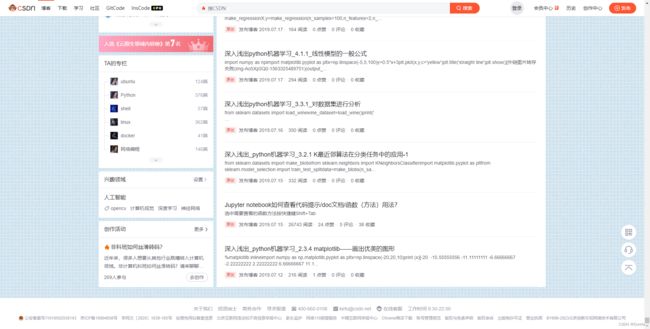
刷完老费劲了
然后我们按F12,点击选取元素按钮

然后随便点一篇博文,产生如下所示代码
这里每一个article开头的都我们刚刚刷出来的一篇博文:

然后往上翻,找到头,复制
找到这个div data...>的头,然后点击右键,选择复制复制–>复制outerHTML:

然后到编辑器里粘贴,然后保存文件为export.html

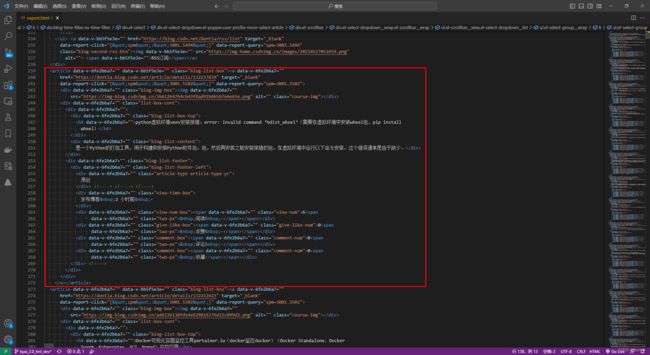
用vscode格式化
格式化之后,就很清晰了,每个article标签就是我们的一篇博文,我们就是要对每个article标签内的内容实行抓取:
撰写python代码parse.py
求助最强大脑:
我有一个export.html文件,里面有很多个article标签,每个标签内容大致如下:
<article data-v-6fe2b6a7="" data-v-bb5f5e3e="" class="blog-list-box"><a data-v-6fe2b6a7=""
href="https://dontla.blog.csdn.net/article/details/132237839" target="_blank"
data-report-click="{"spm":"3001.5502"}" data-report-query="spm=3001.5502">
<div data-v-6fe2b6a7="" class="blog-img-box"><img data-v-6fe2b6a7=""
src="https://img-blog.csdnimg.cn/3b61264764cb43f8ad91b6b5b7e4e65e.png" alt="" class="course-img"></div>
<div data-v-6fe2b6a7="" class="list-box-cont">
<div data-v-6fe2b6a7="">
<div data-v-6fe2b6a7="" class="blog-list-box-top">
<h4 data-v-6fe2b6a7="">python虚拟环境venv安装报错:error: invalid command ‘bdist_wheel‘(需要在虚拟环境中安装wheel包,pip install
wheel)</h4>
</div>
<div data-v-6fe2b6a7="" class="blog-list-content">
是一个Python的打包工具,用于构建和安装Python软件包。包,然后再安装之前安装报错的包。在虚拟环境中运行以下命令安装。这个错误通常是由于缺少。</div>
</div>
<div data-v-6fe2b6a7="" class="blog-list-footer">
<div data-v-6fe2b6a7="" class="blog-list-footer-left">
<div data-v-6fe2b6a7="" class="article-type article-type-yc">
原创
</div> <!----> <!----> <!---->
<div data-v-6fe2b6a7="" class="view-time-box">
发布博客 2 小时前 ·
</div>
<div data-v-6fe2b6a7="" class="view-num-box"><span data-v-6fe2b6a7="" class="view-num">6<span
data-v-6fe2b6a7="" class="two-px"> 阅读 ·</span></span></div>
<div data-v-6fe2b6a7="" class="give-like-box"><span data-v-6fe2b6a7="" class="give-like-num">0<span
data-v-6fe2b6a7="" class="two-px"> 点赞 ·</span></span></div>
<div data-v-6fe2b6a7="" class="comment-box"><span data-v-6fe2b6a7="" class="comment-num">0<span
data-v-6fe2b6a7="" class="two-px"> 评论 ·</span></span></div>
<div data-v-6fe2b6a7="" class="comment-box"><span data-v-6fe2b6a7="" class="comment-num">0<span
data-v-6fe2b6a7="" class="two-px"> 收藏</span></span></div>
</div> <!---->
</div>
</div>
</a></article>
我需要你用python帮我遍历这个文件,然后将每个article中的内容提取出来,做成一个json文件,每个文章提取为一个数组元素,数组元素中要有以下字段:article_url字段(class="blog-list-box"后面那个)、article_title字段(class="blog-list-box-top"后面那个)、article_type(class="article-type article-type-yc"后面那个)
根据最强大脑给出的结果,我再删删改改,得出了这样一个代码:
(parseHtml.py)
from bs4 import BeautifulSoup
import json
# 读取HTML文件
with open('export.html', 'r', encoding='utf-8') as f:
html = f.read()
# 创建BeautifulSoup对象
soup = BeautifulSoup(html, 'html.parser')
# 遍历article标签
articles = []
for article in soup.find_all('article'):
# 提取字段内容
article_url = article.find('a')['href']
article_title = article.find('h4').text
article_type = article.find(class_='article-type').text.strip()
# 构造字典
article_dict = {
'article_url': article_url,
'article_title': article_title,
'article_type': article_type
}
# 添加到数组
articles.append(article_dict)
# 生成json文件
with open('articles.json', 'w', encoding='utf-8') as f:
json.dump(articles, f, ensure_ascii=False, indent=4)
代码解释:使用BeautifulSoup库来解析HTML文件,并使用json库来生成json文件。
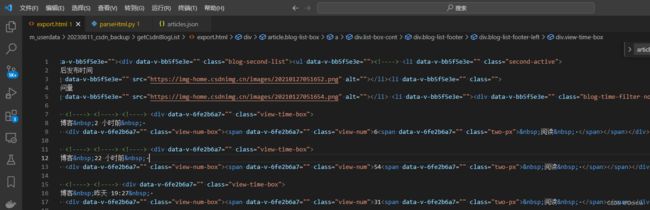
将export.html恢复之前的格式
执行前我们先恢复原始格式,因为我的vscode格式化之后,貌似加入了很多无关的\n以及空格,搞到后面解析结果不好了:

我们把export.html文本恢复成这样:
执行解析代码

执行python代码:
python3 parse.py
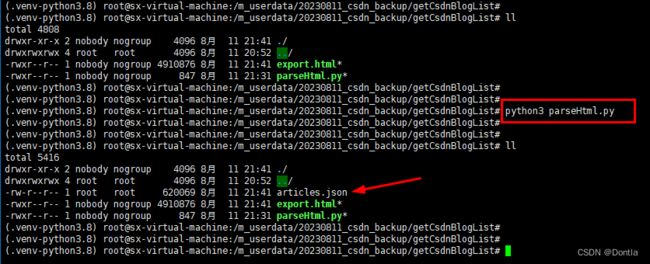
生成了articles.json文件。
查看articles.json文件
可以说结果非常的完美:

[
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132237839”,
“article_title”: “python虚拟环境venv安装报错:error: invalid command ‘bdist_wheel‘(需要在虚拟环境中安装wheel包,pip install wheel)”,
“article_type”: “原创”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132212623”,
“article_title”: “Docker可视化容器监控工具portainer.io(docker监控docker)(Docker Standalone、Docker Swarm、Kubernetes、ACI、Nomad)监控容器”,
“article_type”: “原创”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132216588”,
“article_title”: “FQDN是什么?全限定域名(Fully Qualified Domain Name)(主机名、次级域名、顶级域名)”,
“article_type”: “转载”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132178650”,
“article_title”: “ubuntu python虚拟环境venv搭配systemd服务实战”,
“article_type”: “原创”
}
]
本篇文章就告一段落了,如有兴趣,可以看我下一篇文章,我们基于本篇文章得到的结果,获取每篇CSDN博文质量分并将列表展示在网页上
下一篇:2. 获取自己CSDN文章列表并按质量分由小到大排序,并展示在网页上(文章质量分、博文质量分)