复杂知识库问答最新综述:方法、挑战与解决方案

©PaperWeekly 原创 · 作者 | 刘兴贤
学校 | 北京邮电大学硕士生
研究方向 | 自然语言处理
本文是一篇有关复杂知识库问答(Complex KBQA)的综述,主要围绕 Complex KBQA 遇到的挑战、现有的方法以及解决方案角度来叙述。
目前两类主流的复杂KBQA方法,是基于语义句法分析(SP-based)的方法和基于信息检索(IR-based)的方法。本文从这两个类别的角度对目前最先进的方法进行了全面的回顾。

论文题目:
A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions
论文地址:
https://arxiv.org/abs/2105.11644
该论文被收录于 IJCAI 2021,作者来自新加坡管理大学、人大、北京大数据管理分析中心重点实验室。
知识库问答(KBQA)旨在通过知识库回答问题。近年来,大量的研究集中在语义或句法上复杂的问题上。本文详细地总结了复杂 KBQA 的典型挑战和解决方案。首先介绍 KBQA 任务的背景。接下来,我们介绍了两类主流的复杂 KBQA 方法,即基于语义句法分析(SP-based)的方法和基于信息检索(IR-based)的方法。
然后,我们从这两个类别的角度对先进的方法进行了全面的回顾。具体地说,我们详细说明了他们对典型挑战的解决方案。最后,总结并讨论了未来的研究方向。

Complex KBQA Example
对于问题“谁是 The Jeff Probst Show 提名的 TV Producer 的第一任妻子?”,可以看到该问题涉及了 7 个实体,为了回答该问题,需要 KBQA 系统有一定的推理能力与数值计算能力,然而这样的问题对于目前的 KBQA 系统是相当困难的。


Main Challenge
1. 现有的基于语义解析(SP)的方法中使用的解析器很难覆盖各种复杂的查询(例如,多跳推理、约束关系和数值运算)。类似地,以前的基于 IR 的方法可能无法回答复杂的查询,因为它们的排序是在没有可追踪推理的小范围实体上执行的。
2. 复杂问题中的关系和主语越多,潜在逻辑形式的搜索空间就越大,这将大大增加计算成本。同时,更多的关系和主题可能会使基于信息检索的方法检索所有相关实体进行排序更加困难。
3. 这两种方法都将问题理解作为首要步骤。当问题在语义和句法方面都变得复杂时,要求模型具有很强的自然语言理解和泛化能力。
4. 为复杂问题标注通向答案的基本事实路径的成本很高,通常,只提供问答对。这表明基于语义解析(SP)的方法和基于信息检索(IR)的方法必须分别在没有正确逻辑形式和推理路径注释的情况下进行训练。如此微弱的监督信号给这两种方式都带来了困难。

Mainstream Approaches
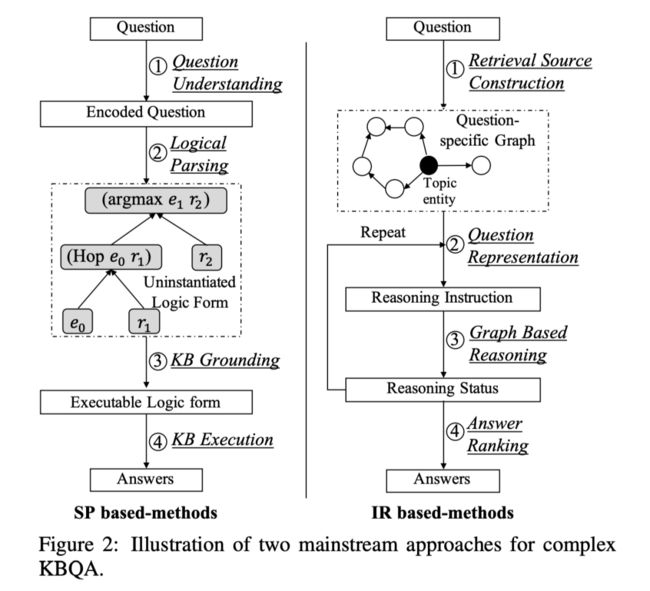
基于语义解析的方法(SP)
该方法旨在将自然语言的问句解析成逻辑形式,通常步骤如下:
(1)使用一个问题理解模块,对句子进行语义和语法解析,获得编码后的问题。
(2)利用逻辑解析模块将编码后的问题转化为一个还未实例化(未填充具体实体关系)的逻辑形式。
(3)针对知识库,将逻辑形式与结构化的知识库进行语义对齐,进一步实例化上一步的逻辑形式。
(4)对知识库执行解析后的逻辑形式,通过知识库执行模块生成预测答案。
基于信息检索的方法(IR)
该方法旨在使用问题中传达的信息,直接从知识库中检索并排序答案。
(1)确定中心实体,并从知识库中提取出特定于问题的子图。理想情况下,该图应该包含所有语文题相关的实体和关系。
(2)通过一个问题表示模块,对输入的问题进行编码,该模块分析问题的编码并输出推理指令,这些指令并非具有明确含义的,而是一个向量。
(3)基于图的推理模块通过基于向量的计算进行语义匹配,将信息沿着图中的相邻实体传播并聚合。
(4)利用答案排序模块根据推理结束时的推理状态对图中的实体进行排序。

Overview
总体而言,基于 SP 的方法可以通过生成可表达的逻辑形式来产生更具解释性的推理过程。然而,它们严重依赖于逻辑形式和解析算法的设计,成为性能提高的瓶颈。作为对比,基于 IR 的方法对图结构进行复杂推理,并进行语义匹配。这样的方法适合流行的端到端训练,并使基于 IR 的方法更易于训练。然而,推理模型的黑盒结构使得中间推理更难解释。

Challenges and Solutions

5.1 Semantic Parsing-based Methods
5.1.1 Overview
基于 SP 的方法遵循先分析后执行的过程,即问题理解、逻辑分析、知识库实例化和知识库执行。对于复杂的 KBQA,这些模块将遇到不同的挑战。
(1)当问题在语义和句法方面都比较复杂时,问题理解变得更加困难。其次,逻辑分析必须涵盖复杂问题的各种查询类型。
(2)涉及更多关系和主题的复杂问题会极大地增加解析可能的搜索空间,从而降低解析效率。
(3)人工标注逻辑形式不仅费时费力,而且训练弱监督信号(即问答对)的SP方法具有挑战性。
5.1.2 Understanding Complex Semantics and Syntax
作为基于 SP 的方法的第一步,问题理解模块将非结构化文本转换为结构化表示,这有利于后续的句法分析。
与简单问句相比,复杂问句具有更复杂的问句类型和成分语义,增加了语言分析的难度。为了更好地理解复杂的自然语言问题,许多现有方法依赖于句法分析,例如依存关系 [Abujabal 等人,2017;Abujabal 等人,2018 [1];Luo等人,2018 [2] ] 和抽象意义表示(AMR)[Kapanipathi 等人,2020 [3] ],以在问题成分和逻辑元素(例如,实体、关系、实体类型和属性)之间提供更好的对齐。
然而,对于复杂问题,特别是对于那些具有长距离依存关系的问题,生成句法分析的准确率仍然不能令人满意。为了减轻从句法分析到下游语义分析的错误传播,[Sun 等人, 2020 [4] ] 提出了一种改进方法。利用基于骨架的句法分析方法,获得复杂问题的主干,这是一个具有多个分支(即原文跨度的枢轴词)的简单问题。
另一项工作侧重于利用逻辑形式的结构属性(如树结构或图结构)对候选解析进行排名。他们试图通过引入结构感知的特征编码器 [Zhu 等人,2020 [5] ],应用细粒度的槽匹配 [Mahehwari 等人,2019 年 [6] ],以及添加关于查询结构的约束来过滤噪音查询,来改善逻辑形式和问题之间的匹配 [Chen 等人,2020 [7] ]。
5.1.3 Parsing Complex Queries
在句法分析过程中,传统的语义句法分析(例如 CCG [Cai and Yates,2013 [8] ];Kwiatkowski 等人,2013 [9];Reddy等人,2014 [10])在分析简单问题时显示出了它们的潜力。然而,由于本体不匹配问题,这些方法对于复杂的问题可能是次优的 [Yih 等人,2015 年 [11] ]。因此,有必要利用知识库的结构进行更准确的解析。
为了满足复杂问题的组合性,研究者将不同的表达逻辑形式作为目标。[Bast 和 Haussmann, 2015 [12] ] 设计了三个查询模板作为解析目标,可以涵盖查询1-跳、2- 跳关系和单约束涉及关系的问题。虽然该方法可以成功地解析几种类型的复杂问题,但它存在覆盖范围有限的问题。
[Yih 等, 2015 [11] ] 提出将问题解析成一个查询图。查询图是与知识库模式紧密匹配的图结构逻辑形式。这种查询图在复杂的 KBQA 任务中表现出很强的表达能力。但是,它们是由预定义的人工规则限制生成的,这不适用于大规模数据集和长尾复杂问题类型。后续工作试图改进查询图的表达方式。
为了推广到看不见的长尾问题类型,[Ding 等人, 2019 [13] ] 提出利用频繁使用的查询子结构进行形式化查询生成。[Abujabal 等人,2017 [1] ] 利用句法标注提高查询图的结构复杂度。[Hu 等人,2018b [14] ] 应用了更多的聚合运算符(如“合并”)来拟合复杂的问题,并进行了共指消解。
5.1.4 Grounding with Large Search Space
为了获得可执行的逻辑形式,知识库实例化模块用知识库实例化可能的逻辑形式(将在知识库中的实体关系添加进可执行的查询语句)。由于知识库中的一个实体可能链接到数百甚至数千个关系,考虑到计算资源和时间复杂性,为一个复杂问题建立所有可能的逻辑形式是代价高昂的。
最近,研究人员提出了多种解决问题的方法。[Zheng 等人,2018b [15] ] 提出将一个复杂问题分解为多个简单问题,每个问题解析成一个简单的逻辑形式。然后,通过这些简单的逻辑形式生成中间答案,并联合得到最终答案。这种分解-执行-连接策略可以有效地缩小搜索空间。
[Bhutani 等人, 2019 [16] ] 也研究了类似的方法,他们通过利用依赖关系结构减少了人工标注。同时,一些研究采用扩展排序策略,通过 Beam Search 来减小搜索空间。[Chen 等人,2019 [17] ] 首先采用逐跳贪婪搜索策略对最可能的查询图进行扩展,直至得到最优查询图。
[Lan 等人,2019c [18] ] 提出了一种迭代匹配模块,在每个搜索步骤中无需重新访问生成的查询图即可对问题进行解析。这种顺序展开过程只在回答多跳问题时有效,而对于有约束或数值运算的问题则无能为力。[Lan 和 Jiang, 2020 [19] ] 定义了更多的操作来支持三个典型的复杂查询,这可以大大减少搜索空间。
5.1.5 Training under Weak Supervision Signals
为了处理训练数据有限或不足的问题,采用了基于强化学习(RL)的优化方法来最大化预期回报 [Liang 等人,2017 [20];Qiu 等人,2020b [21] ]。在这种情况下,基于 SP 的方法只能在执行完完整的解析逻辑形式后才能收到反馈,这导致了严重的稀疏正反馈和数据低效问题。为了解决这些问题,一些研究工作采用了 reward shaping 策略来进行句法分析评估。
[Saha 等人,2019 [22] ] 当预测答案与基本事实类型相同时,附加反馈奖励模型。[Hua 等人, 2020b [23] ] 采用类似的思路,通过将生成的逻辑形式与存储在内存缓冲区中的高反馈逻辑形式进行比较,对生成的逻辑形式进行评估。除了对整个过程的反馈之外,语义分析过程中的中间反馈也可能有助于解决这一挑战。
最近,[Qiu 等人,2020b [21] ] 提出了自己的观点,将查询图生成问题描述为一个层次化决策问题,并提出了一种基于层次化 RL 的框架,该框架具有提供中间反馈的机制。为了加快和稳定训练过程,[Qiu 等人,2020b [21] ] 使用一个伪 gold 过程(用手工规则生成的高反馈逻辑表格)预训练模型。因为伪黄金程序也可以从该模型中产生,[Liang 等人,2017 [20] ] 提出通过迭代最大似然训练过程来保持伪 gold 过程的 bootstrap 训练。
5.2 Information Retrieval-based Methods
5.2.1 Overview
整个过程通常由检索源构建、问题表示、基于图的推理和答案排序模块组成。对于复杂的 KBQA,这些模块将遇到不同的挑战。
(1)检索源构建模块从知识库中提取问题特定子图,该图涵盖了每个问题的广泛相关事实。知识库的不完全性 [Min 等人,2013 [24] ] 的问题不可忽视,因此提取的图中可能缺少正确的推理路径。这个问题更有可能发生在复杂问题的情况下。
(2)问题表示模块理解问题并生成指导推理过程的指令。当问题很复杂时,这一步就会变得具有挑战性。
(3)通过语义匹配对图进行推理。在处理复杂问题时,这些方法通过语义相似度对答案进行排序,图中没有可追溯的推理,这给推理分析和故障诊断带来了困难。
(4)该系统在弱监督信号(即只有问答对但没有推理路径)下遇到同样的训练挑战。
5.2.2 Reasoning under Incomplete KB
基于 IR 的方法首先从知识库中提取问题特定子图,然后对其进行推理。由于简单的问题只需要在知识库中的中心实体邻域上进行 1 跳推理,因此基于 IR 的方法不太可能受到知识库固有的不完全性的影响 [Min 等人,2013 [24] ]。
相比之下,对于复杂的问题来说,这可能是一个严重的问题,因为在特定问题的图表中可能没有正确的推理路径。此外,这种不完整性减少了用于编码实体的邻域信息,这给有效推理带来了额外的挑战。
为了应对这一挑战,研究人员利用辅助信息(比如维基百科检索到的与问题相关的大型文本语料库),可以提供广泛的非结构化知识作为补充证据。[Sun 等人,2018 [25] ] 和 [Sun 等人, 2019 [26] ] 提出用额外的问题相关文本语句来补充从不完备知识库中提取的子图,形成一个异构图,并在其上进行推理。
[Xiong 等人,2019 [27];Han 等人, 2020a [28] ] 没有直接将句子作为节点补充到问题特定的图中,而是在实体表示中融合额外的文本信息来补充知识。该方法首先对问句相关实体进行编码,然后通过聚合句子的表示来补充不完整的知识库,以增强相应的实体表示。
除了额外的文本语料库外,还采用了知识库嵌入的方法,通过进行缺省链接预测来缓解知识库的稀疏性。受知识库补全任务的启发,[Saxena 等人,2020 [29] ] 利用预先训练的知识库嵌入来丰富学习的实体表示并解决不完整的知识库问题。
5.2.3 Understanding Complex Semantics
一般而言,基于 IR 的方法通过神经网络(例如 LSTM)将问题直接编码为低维向量来生成推理指令。通过上述方法静态生成的推理指令不能有效地表示复杂问题的组合语义。为了更全面地理解问题,最近的工作在推理过程中动态更新了推理指令。
为了把重点放在问题目前未分析的部分,[Miller 等人,2016 [30];Zhou 等人,2018 [31];Xu 等人,2019 [32] ] 建议用推理过程中检索到的信息更新推理指令。除了用推理信息更新指令表示外,[He 等人,2021 [33] ] 还对指令表示进行了修改,提出用动态注意力机制关注问题的不同部分。
这种动态注意机制可以促进模型注意到问题所传达的其他信息,并为后续的推理步骤提供适当的指导。[Sun 等人,2018 [25] ] 没有分解问题的语义,提出使用图表中的上下文信息来增强问题的表示。在每个推理步骤之后,他们通过聚合来自主题实体的信息来更新推理指令。
5.2.4 Uninterpretable Reasoning
传统的基于信息检索的方法通过计算问题和图中实体之间的单一语义相似度来对答案进行排序,这在中间步骤较难解释。由于复杂的问题通常会查询多个事实,因此系统应该基于一个可追踪和可观察的推理过程来准确地预测图上的答案。即使有些工作多次重复推理步骤,他们也不能沿着图表中可追踪的路径进行推理。为了推导出更具解释性的推理过程,引入了多跳推理。
[Zhou 等人,2018 [31] ] 和 [Xu 等人,2019 [32] ] 提出使在每一跳预测的关系或实体可追溯和可观察。它们从预定义的记忆模块中输出中间预测(即匹配的关系或实体)作为可解释的推理路径。然而,它不能充分利用语义关系信息进行边对边推理。因此,[Han等人,2020b [34] ] 通过精确定位一组通过相同关系连接的实体,构建了一个更密集的超图,它模拟了人的跳跃关系推理,并输出一条顺序关系路径,使推理具有可解释性。
5.2.5 Training under Weak Supervision Signals
与基于 SP 的方法类似,基于 IR 的方法很难在中间步骤没有任何注释的情况下推理正确的答案,因为模型直到推理结束才能收到任何反馈。人们发现,这种情况可能导致虚假推理 [He 等人,2021 [33] ]。
为了缓解这些问题,[Qiu 等人,2020a [35] ] 将知识库上的推理过程定义为扩展知识库上的推理路径,并采用奖励形成策略提供中间奖励。为了评估中间步骤的推理路径,他们利用问题和推理路径之间的语义相似性来提供反馈。
除了在中间步骤评估推理路径之外,更直观的想法是推断伪中间状态,并用这样的推断信号增强模型训练。受图上双向搜索算法的启发,[He 等人,2021 [33] ] 提出了基于图的双向搜索算法,通过同步双向推理过程来学习中间推理实体分布。
目前已有的工作大多集中在中间环节的监控信号增强上,而对实体链接环节的研究较少。研究人员使用离线工具来定位问题主题实体,这可能会导致错误传播到后续推理中。为了准确定位不带标注的主题实体,[Zhang 等人,2018 [36] ] 提出了一种新的主题实体定位方法,利用基于知识库的中心实体识别和后续推理的联合学习算法来训练实体链接模块。

Conclusion and Future Directions
6.1 Evolutionary KBQA
复杂 KBQA 现有方法通常是在离线训练数据集上学习的,然后在线部署来回答用户的问题。由于这种明确的分离,现有的 KBQA 系统大多跟不上世界知识的快速增长,无法回答新的问题。然而,用户反馈可能会为已部署的 KBQA 系统提供改进自身的机会。
基于这一观察,[Abujabal 等人,2018 [37] ] 利用用户反馈纠正 KBQA 系统生成的答案,并进行进一步改进。除了验证系统预测的正确性外,用户也可能在答疑过程中发挥更积极的作用。
[Zheng 等人,2018a [38] ] 设计了一种交互式方式,让用户直接参与知识库问答系统的问题解析过程。在未来,KBQA 系统在在线部署后要得到持续改进,对于可持续性的、不断进化的 KBQA 的探索势在必行。
6.2 Robust and Interpretable Models
虽然现有的方法在目前的基准数据集上取得了令人振奋的结果,但它们可能很容易无法处理分布外的情况。
Few-Shot 学习是训练数据有限的场景。以前的一些研究 [Hua 等人,2020a;He等人,2021 [33] ] 讨论了相关主题,但在分析挑战和问题解决方面仍然远远不全面。
成分泛化是另一个场景,在该场景中,训练过程新颖单词组合应该在测试过程中被推断出来。为了支持对这一问题的更多研究,[Gu 等人,2020 [39] ] 和 [Keysers等人,2020 [40] ] 介绍了相关数据集,即 GraQA 和 CFQ。这些模型应该能够处理分布不均的问题,并获得可解释的推理过程。设计具有良好可解释性和健壮性的 KBQA 方法可能是未来研究的一个具有挑战性但很有前途的课题。
6.3 More General Knowledge Base
由于知识库的不完整性,研究人员纳入了额外的信息(如文本 [Sun 等人,2018 年 [25] ]、图像 [Xie 等人,2017 [41] ] 和人与人的互动 [He 等人,2020 [42] ] )来补充知识库,这将进一步改善复杂的 KBQA 性能。
还有一些任务(例如,视觉问答和常识知识推理)可以表示为基于特定知识库的问答。例如,在视觉问答中,从图像中提取的场景图可以看作是一个特殊的知识库 [Hudson and Manning,2019 [43] ]。
尽管将关系知识显性地表示为结构型知识库,但一些研究者建议对隐性的“知识库”进行推理。[Petroni 等人,2019 [44] ] 分析了一系列预训练模型中的关系知识,并进行了一些后续工作 [Bouraoui 等人,2020 [45];Jiang 等人,2020 [46] ],进一步证明了它对回答完形填空语句的有效性。虽然现有的大部分工作都集中在传统的结构化知识库上,但对知识库的更广泛的定义和对知识库的灵活使用可能有助于 KBQA 研究表现出更大的影响力。
参考文献
[1] Abdalghani Abujabal, Mohamed Yahya, Mirek Riedewald, and Gerhard Weikum. Automated template generation for question answering over knowledge graphs. In WWW, 2017.
[2] [Luo et al., 2018] Kangqi Luo, Fengli Lin, Xusheng Luo, and Kenny Q. Zhu. Knowledge base question answering via encoding of complex query graphs. In EMNLP, 2018.
[3] [Kapanipathi et al., 2020] Pavan Kapanipathi, Ibrahim Abdelaziz, Srinivas Ravishankar, Salim Roukos, Alexander G. Gray, Ram´on Fernandez Astudillo, Maria Chang, Cristina Cornelio, Saswati Dana, Achille Fokoue, Dinesh Garg, Alfio Gliozzo, Sairam Gurajada, Hima Karanam, Naweed Khan, Dinesh Khandelwal, Young-Suk Lee, Yunyao Li, Francois P. S. Luus, Ndivhuwo Makondo, Nandana Mihindukulasooriya, Tahira Naseem, Sumit Neelam, Lucian Popa, Revanth Gangi Reddy, Ryan Riegel, Gaetano Rossiello, Udit Sharma, G. P. Shrivatsa Bhargav, and Mo Yu. Question answering over knowledge bases by leveraging semantic parsing and neuro-symbolic reasoning. In AAAI, 2020.
[4] [Sun et al., 2020] Yawei Sun, Lingling Zhang, Gong Cheng, and Yuzhong Qu. SPARQA: skeleton-based semantic parsing for complex questions over knowledge bases. In AAAI, 2020.
[5] [Zhu et al., 2020] Shuguang Zhu, Xiang Cheng, and Sen Su. Knowledge-based question answering by tree-to-sequence learning. Neurocomputing, 2020.
[6] [Maheshwari et al., 2019] Gaurav Maheshwari, Priyansh Trivedi, Denis Lukovnikov, Nilesh Chakraborty, Asja Fischer, and Jens Lehmann. Learning to rank query graphs for complex question answering over knowledge graphs. In ISWC, 2019.
[7] [Chen et al., 2020] Yongrui Chen, Huiying Li, Yuncheng Hua, and Guilin Qi. Formal query building with query structure prediction for complex question answering over knowledge base. In IJCAI, 2020.
[8] [Cai and Yates, 2013] Qingqing Cai and Alexander Yates. Large-scale semantic parsing via schema matching and lexicon extension. In ACL, 2013.
[9] [Kwiatkowski et al., 2013] Tom Kwiatkowski, Eunsol Choi, Yoav Artzi, and Luke Zettlemoyer. Scaling semantic parsers with on-the-fly ontology matching. In EMNLP, 2013.
[10] [Reddy et al., 2014] Siva Reddy, Mirella Lapata, and Mark Steedman. Large-scale semantic parsing without questionanswer pairs. TACL, 2014.
[11] [Yih et al., 2015] Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. Semantic parsing via staged query graph generation: Question answering with knowledge base. In ACL, 2015.
[12] [Bast and Haussmann, 2015] Hannah Bast and Elmar Haussmann. More accurate question answering on freebase. In CIKM, 2015.
[13] [Ding et al., 2019] Jiwei Ding, Wei Hu, Qixin Xu, and Yuzhong Qu. Leveraging frequent query substructures to generate formal queries for complex question answering. In EMNLP, 2019.
[14] [Hu et al., 2018b] Sen Hu, Lei Zou, and Xinbo Zhang. Astate-transition framework to answer complex questionsover knowledge base. In EMNLP, 2018.
[15] [Zheng et al., 2018b] Weiguo Zheng, Jeffrey Xu Yu, Lei Zou, and Hong Cheng. Question answering over knowledgegraphs: Question understanding via template decomposition. In VLDB Endow., 2018.
[16] [Bhutani et al., 2019] Nikita Bhutani, Xinyi Zheng, and H. V. Jagadish. Learning to answer complex questions over knowledge bases with query composition. In CIKM, 2019.
[17] [Chen et al., 2019] Zi-Yuan Chen, Chih-Hung Chang, Yi- Pei Chen, Jijnasa Nayak, and Lun-Wei Ku. UHop: An unrestricted-hop relation extraction framework for knowledge-based question answering. In NAACL, 2019.
[18] [Lan et al., 2019c] Yunshi Lan, Shuohang Wang, and Jing Jiang. Multi-hop knowledge base question answering with an iterative sequence matching model. In ICDM, 2019.
[19] [Lan and Jiang, 2020] Yunshi Lan and Jing Jiang. Query graph generation for answering multi-hop complex questions from knowledge bases. In ACL, 2020.
[20] [Liang et al., 2017] Chen Liang, Jonathan Berant, Quoc Le, Kenneth D. Forbus, and Ni Lao. Neural symbolic machines: Learning semantic parsers on Freebase with weak supervision. In ACL, 2017.
[21] [Qiu et al., 2020b] Yunqi Qiu, Kun Zhang, Yuanzhuo Wang, Xiaolong Jin, Long Bai, Saiping Guan, and Xueqi Cheng. Hierarchical query graph generation for complex question answering over knowledge graph. In CIKM, 2020.
[22] [Saha et al., 2019] Amrita Saha, Ghulam Ahmed Ansari, Abhishek Laddha, Karthik Sankaranarayanan, and Soumen Chakrabarti. Complex program induction for querying knowledge bases in the absence of gold programs. TACL, 2019.
[23] [Hua et al., 2020b] Yuncheng Hua, Yuan-Fang Li, Guilin Qi, Wei Wu, Jingyao Zhang, and Daiqing Qi. Less is more: Data-efficient complex question answering over knowledge bases. J. Web Semant., 2020.
[24] [Min et al., 2013] Bonan Min, Ralph Grishman, Li Wan, Chang Wang, and David Gondek. Distant supervision for relation extraction with an incomplete knowledge base. In NAACL-HLT, 2013.
[25] [Sun et al., 2018] Haitian Sun, Bhuwan Dhingra, Manzil Zaheer, Kathryn Mazaitis, Ruslan Salakhutdinov, and William Cohen. Open domain question answering using early fusion of knowledge bases and text. In EMNLP, 2018.
[26] [Sun et al., 2019] Haitian Sun, Tania Bedrax-Weiss, and William Cohen. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. In EMNLP, 2019.
[27] [Xiong et al., 2019] Wenhan Xiong, Mo Yu, Shiyu Chang, Xiaoxiao Guo, and William Yang Wang. Improving question answering over incomplete kbs with knowledge-aware reader. In ACL, 2019.
[28] [Han et al., 2020a] Jiale Han, Bo Cheng, and Xu Wang. Open domain question answering based on text enhanced knowledge graph with hyperedge infusion. In EMNLP, 2020.
[29] [Saxena et al., 2020] Apoorv Saxena, Aditay Tripathi, and Partha Talukdar. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In ACL, 2020.
[30] [Miller et al., 2016] Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. Key-value memory networks for directly reading documents. In EMNLP, 2016.
[31] [Zhou et al., 2018] Mantong Zhou, Minlie Huang, and Xiaoyan Zhu. An interpretable reasoning network for multirelation question answering. In COLING, 2018.
[32] [Xu et al., 2019] Kun Xu, Yuxuan Lai, Yansong Feng, and Zhiguo Wang. Enhancing key-value memory neural networks for knowledge based question answering. In NAACL-HLT, 2019.
[33] [He et al., 2021] Gaole He, Yunshi Lan, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. Improving multihop knowledge base question answering by learning intermediate supervision signals. In WSDM, 2021
[34] [Han et al., 2020b] Jiale Han, Bo Cheng, and Xu Wang. Two-phase hypergraph based reasoning with dynamic relations for multi-hop kbqa. In IJCAI, 2020.
[35] [Qiu et al., 2020a] Yunqi Qiu, Yuanzhuo Wang, Xiaolong Jin, and Kun Zhang. Stepwise reasoning for multi-relation question answering over knowledge graph with weak supervision. In WSDM, 2020.
[36] [Zhang et al., 2018] Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J Smola, and Le Song. Variational reasoning for question answering with knowledge graph. In AAAI, 2018.
[37] [Abujabal et al., 2018] Abdalghani Abujabal, Rishiraj Saha Roy, Mohamed Yahya, and Gerhard Weikum. Neverending learning for open-domain question answering over knowledge bases. In WWW, 2018.
[38] [Zheng et al., 2018a] Weiguo Zheng, Hong Cheng, Jeffrey Xu Yu, Lei Zou, and Kangfei Zhao. Never-ending learning for open-domain question answering over knowledge bases. In InfoScience, 2018.
[39] [Gu et al., 2020] Yu Gu, Sue Kase, Michelle Vanni, Brian M. Sadler, Percy Liang, Xifeng Yan, and Yu Su. Beyond I.I.D.: three levels of generalization for question answering on knowledge bases. In WWW, 2020.
[40] [Keysers et al., 2020] Daniel Keysers, Nathanael Sch¨arli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashubin, Nikola Momchev, Danila Sinopalnikov, Lukasz Stafiniak, Tibor Tihon, Dmitry Tsarkov, Xiao Wang, Marc van Zee, and Olivier Bousquet. Measuring compositional generalization: A comprehensive method on realistic data. In ICLR, 2020.
[41] [Xie et al., 2017] Ruobing Xie, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. Image-embodied knowledge representation learning. In IJCAI, pages 3140–3146, 2017.
[42] [He et al., 2020] Gaole He, Junyi Li,Wayne Xin Zhao, Peiju Liu, and Ji-Rong Wen. Mining implicit entity preference from user-item interaction data for knowledge graph completion via adversarial learning. In WWW, 2020.
[43] [Hudson and Manning, 2019] Drew A. Hudson and Christopher D. Manning. Learning by abstraction: The neural state machine. In NeurIPS, 2019.
[44] [Petroni et al., 2019] Fabio Petroni, Tim Rockt¨aschel, Sebastian Riedel, Patrick S. H. Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander H. Miller. Language models as knowledge bases? In EMNLP, 2019.
[45] [Bouraoui et al., 2020] Zied Bouraoui, Jos´e Camacho- Collados, and Steven Schockaert. Inducing relational knowledge from BERT. In AAAI, 2020.
[46] [Jiang et al., 2020] Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. How can we know what language models know. TACL, 2020.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
