【MindStudio训练营第一季】基于MindX的U-Net网络的工业质检实践作业
1.1 作业介绍
1.1.1 作业背景
随着新一轮科技革命和产业变革的加速演进,全球各国都在借助新技术推动制造业升级,从工业2.0自动化开始兴起,到工业3.0信息化普及,如今正迈向工业4.0智能化。借助IoT、工业大数据、人工智能等先进技术实现从低端劳动密集型产业向高端科技型产业的制造升级。
在应用人工智能技术之前,部分场景下已出现传统机器视觉进行质检的案例。但是由于产品零件复杂、光源多样等因素的限制,更多场景还是依赖于人工质检。而人工智能技术的融合可进一步提升检测精度,很多实践已证明AI算法可实现高达99%以上检测精度,可以应用在绝大多数工业质检场景中。
从AI算法到工业制造场景化应用还有很远,算法开发、应用开发、业务部署是阻碍AI应用进入工业生产的三大鸿沟。为此,华为昇腾计算秉承“硬件开放、软件开源”的理念,打造了昇腾智能制造使能平台,致力于推进制造行业转型升级。
在硬件方面,华为提供从模组/板卡到服务器/集群的Atlas系列化硬件。Atlas 200 AI加速模块具有极致性能、超低功耗的特点,可以在端侧实现物体识别、图像分类等;Atlas 300I推理卡提供超强AI推理性能,以超强算力加速应用,可广泛应用于推理场景。
在软件方面,为了帮助开发者跨越AI应用落地制造行业的三大鸿沟,华为提供了全栈软件平台与工具。特别是昇腾应用使能MindX,帮助广大应用开发者快速开发AI应用,让AI进入制造行业。据介绍,MindX中包含了“2+1+X”,其中“2”是深度学习使能MindX DL和智能边缘使能MindX Edge,帮助开发者快速搭建深度学习和边缘推理的基础平台;“1”是优选模型库ModelZoo,为开发者提供了各个场景下经过调优的模型,开发者只需根据自身场景需要,按需下载即可;最后是面向行业应用的SDK,华为已经在昇腾社区发布了面向智能制造场景的mxManufacture SDK和mxVision SDK,聚焦于工业质检场景,能够以很少的代码量、甚至于零代码完成制造行业AI应用开发。
1.1.2 作业目的
本作业使用工业质检场景中的模拟数据集,采用MindSpore深度学习框架构建U-Net网络,在华为云平台的ModelArts上创建基于昇腾910处理器的训练环境,启动训练并得到图像分割的模型;之后在华为云平台的ECS弹性云服务器上创建基于昇腾310处理器的推理环境,将该模型转换成离线模型,使用MindX SDK mxVision 执行推理任务。
本作业目的:
• 理解工业质检的背景。
• 掌握MindSpore的基础使用。
• 熟悉U-Net网络和图像分割的原理知识。
• 掌握华为云ModelArts和ECS的环境搭建。
• 熟悉昇腾910和昇腾310处理器的使用。
• 掌握离线模型的转换方法。
• 熟悉MindX SDK mxVision的使用。
考虑到本次以MindStudio为基础,注重推理,因此主要介绍在昇腾310上模型推理,训练部分省略。
1.1.3 模型介绍
U-Net介绍:
U-Net模型基于二维图像分割。在2015年ISBI细胞跟踪竞赛中,U-Net获得了许多最佳奖项。论文中提出了一种用于医学图像分割的网络模型和数据增强方法,有效利用标注数据来解决医学领域标注数据不足的问题。U型网络结构也用于提取上下文和位置信息。

[U-Net 论文 ]: Olaf Ronneberger, Philipp Fischer, Thomas Brox. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” conditionally accepted at MICCAI 2015. 2015.
UNet++是U-Net的增强版本,使用了新的跨层链接方式和深层监督,可以用于语义分割和实例分割。

[UNet++ 论文 ]: Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh and J. Liang, “UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation,” in IEEE Transactions on Medical Imaging, vol. 39, no. 6, pp. 1856-1867, June 2020, doi: 10.1109/TMI.2019.2959609.
运行脚本
预计模型训练所需时间约为20分钟。环境配置为华为云ModelArts上的MindSpore1.7 + Ascend 910A组合。
终端运行示例:
python train.py --data_url=./data/ --run_eval=True
• --data_url:数据集输入路径。
• --run_eval:True表示训练过程中同时进行验证。
训练日志:
============== Starting Training ==============
img shape: (1800, 1800, 3) mask shape (1800, 1800)
step: 1, loss is 2.0795505, fps is 0.01587404091683707
step: 2, loss is 2.07847, fps is 25.585164851923018
step: 3, loss is 2.0777602, fps is 34.00713498086528
step: 4, loss is 2.0772874, fps is 35.27263247302604
step: 5, loss is 2.0767062, fps is 36.21961624151569
...
step: 236, loss is 0.03733757, fps is 35.12729160908855
step: 237, loss is 0.027148828, fps is 35.399451407351144
step: 238, loss is 0.030170249, fps is 35.72904456862478
step: 239, loss is 0.049450595, fps is 36.01899576631429
step: 240, loss is 0.031540662, fps is 35.64675386485131
epoch: 5, avg loss:0.0373, total cost: 138.932 s, per step fps:1.727
epoch: 5, dice_coeff: 0.9967254781174716
End training, the best dice_coeff is: 0.9980154385637104, the best dice_coeff epoch is 1
============== End Training ==============
经过5轮的训练,图像分割模型已趋近收敛,并已找到最优Dice系数(Dice coefficient),说明模型预测值和标签的最高相似度达到0.9980。
*Dice系数是一种度量集合相似度的函数,通常用于计算两个样本的相似度(取值范围为[0,1])。
1.1.4 模型保存
如果想在昇腾AI处理器上执行推理,可以通过网络定义和CheckPoint生成AIR格式模型文件。
export.py文件内容如下,可根据实际开发情况进行修改。
import argparse
import numpy as np
from mindspore import Tensor, export, load_checkpoint, load_param_into_net, context
from src.unet_medical.unet_model import UNetMedical
from src.unet_nested import NestedUNet, UNet
from src.config import cfg_unet as cfg
from src.utils import UnetEval
parser = argparse.ArgumentParser(description='unet export')
parser.add_argument("--device_id", type=int, default=0, help="Device id")
parser.add_argument("--batch_size", type=int, default=1, help="batch size")
parser.add_argument("--ckpt_file", type=str, required=True, help="Checkpoint file path.")
parser.add_argument('--width', type=int, default=572, help='input width')
parser.add_argument('--height', type=int, default=572, help='input height')
parser.add_argument("--file_name", type=str, default="unet", help="output file name.")
parser.add_argument('--file_format', type=str, choices=["AIR", "ONNX", "MINDIR"], default='AIR', help='file format')
parser.add_argument("--device_target", type=str, choices=["Ascend", "GPU", "CPU"], default="Ascend",
help="device target")
args = parser.parse_args()
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target)
if args.device_target == "Ascend":
context.set_context(device_id=args.device_id)
if __name__ == "__main__":
if cfg['model'] == 'unet_medical':
net = UNetMedical(n_channels=cfg['num_channels'], n_classes=cfg['num_classes'])
elif cfg['model'] == 'unet_nested':
net = NestedUNet(in_channel=cfg['num_channels'], n_class=cfg['num_classes'], use_deconv=cfg['use_deconv'],
use_bn=cfg['use_bn'], use_ds=False)
elif cfg['model'] == 'unet_simple':
net = UNet(in_channel=cfg['num_channels'], n_class=cfg['num_classes'])
else:
raise ValueError("Unsupported model: {}".format(cfg['model']))
# return a parameter dict for model
param_dict = load_checkpoint(args.ckpt_file)
# load the parameter into net
load_param_into_net(net, param_dict)
net = UnetEval(net)
input_data = Tensor(np.ones([args.batch_size, cfg["num_channels"], args.height, args.width]).astype(np.float32))
export(net, input_data, file_name=args.file_name, file_format=args.file_format)
终端运行示例:
python export.py --ckpt_file="./ckpt_0/best.ckpt" --width=960 --height=960 --file_name="out_model/unet_hw960_bs1" --file_format="AIR"
• ckpt_file: ckpt路径。
• width: 模型输入尺寸。
• height: 模型输入尺寸。
• file_name: 输出文件名。
• file_format: 输出格式,必须为[“ONNX”, “AIR”, “MINDIR”]。
输出结果:
out_model/unet_hw960_bs1.air
将unet_hw960_bs1.air模型下载至本地,供后续MindX SDK推理实验使用。
*提醒:本阶段结束后请及时停止Notebook训练作业,避免资源浪费。
1.2 MindX SDK推理
1.2.1 环境准备
基于训练营共享的CANN6.0.RC1_MindX_Vision3.0.RC3镜像,购买ECS,注意该镜像是针对root用户配置,我们的操作基本都在root用户下执行。
我们还要修改bash,具体命令和结果如下。

1.2.2 项目介绍
本项目支持MindStudio运行和终端运行。
下载项目代码
https://alexed.obs.cn-north-4.myhuaweicloud.com/unet_sdk.zip
将项目文件unet_sdk.zip上传至华为云ECS弹性云服务器/root/目录下,并解压;或者下载到本地电脑,用MindStudio打开。
将之前unet_hw960_bs1.air模型放到/unet_sdk/model/目录下。
项目文件结构
├── unet_sdk
├── README.md
├── data //数据集
│ ├── 1
│ │ ├──image.png //图片
│ │ ├──mask.png //标签
│ ...
├── model
│ ├──air2om.sh // air模型转om脚本
│ ├──xxx.air //air模型
│ ├──xxx.om //om模型
│ ├──aipp_unet_simple_opencv.cfg // aipp文件
├── pipeline
│ ├──unet_simple_opencv.pipeline // pipeline文件
├── main.py // 推理文件
├── run.sh // 执行文件
├── requirements.txt // 需要的三方库
1.2.3 模型转换
将unet_hw960_bs1.air模型转为昇腾AI处理器支持的.om格式离线模型,此处模型转换需要用到ATC工具。
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是昇腾CANN架构体系下的模型转换工具,它可以将开源框架的网络模型或Ascend IR定义的单算子描述文件(json格式)转换为昇腾AI处理器支持的.om格式离线模型。模型转换过程中可以实现算子调度的优化、权值数据重排、内存使用优化等,可以脱离设备完成模型的预处理。
ATC参数概览:https://support.huaweicloud.com/atctool-cann504alpha3infer/atlasatc_16_0041.html


运行脚本:
cd unet_sdk/model/ # 切换至模型存储目录
atc --framework=1 --model=unet_hw960_bs1.air --output=unet_hw960_bs1 --input_format=NCHW --soc_version=Ascend310 --log=error --insert_op_conf=aipp_unet_simple_opencv.cfg
- 注意air模型转om只支持静态batch,这里batchsize=1。
参数说明:
• framework:原始框架类型。
• model:原始模型文件路径与文件名。
• output:转换后的离线模型的路径以及文件名。
• input_format:输入数据格式。
• soc_version:模型转换时指定芯片版本。
• log:显示日志的级别。
• insert_op_conf:插入算子的配置文件路径与文件名,这里使用AIPP预处理配置文件,用于图像数据预处理。
输出结果:
ATC run success,表示模型转换成功,得到unet_hw960_bs1.om模型。
![]()
模型转换成功之后,可以使用MindX SDK mxVision运行脚本,在Ascend 310上进行推理。
1.2.4 MindX SDK mxVision 执行推理
MindX SDK文档请参考:
https://support.huaweicloud.com/ug-vis-mindxsdk203/atlasmx_02_0051.html
MindX SDK执行推理的业务流程:
通过stream配置文件,Stream manager可识别需要构建的element以及element之间的连接关系,并启动业务流程。Stream manager对外提供接口,用于向stream发送数据和获取结果,帮助用户实现业务对接。
plugin表示业务流程中的基础模块,通过element的串接构建成一个stream。buffer用于内部挂载解码前后的视频、图像数据,是element之间传递的数据结构,同时也允许用户挂载元数据(Metadata),用于存放结构化数据(如目标检测结果)或过程数据(如缩放后的图像)。

MindX SDK基础概念介绍:

MindX SDK 基础插件
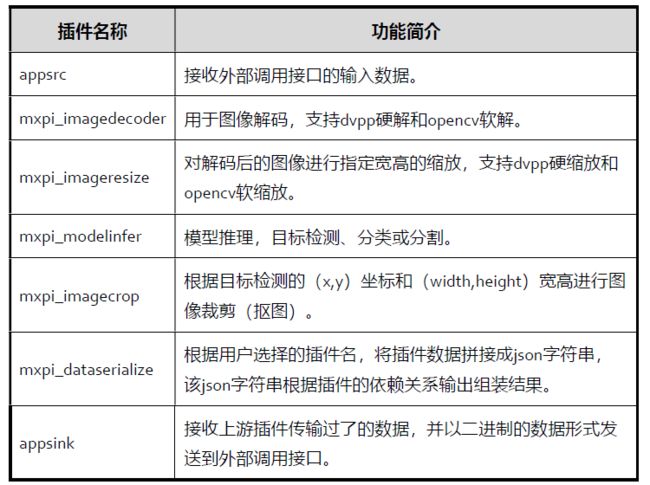
MindX SDK业务流程编排:
Stream配置文件以json格式编写,用户必须指定业务流名称、元件名称和插件名称,并根据需要,补充元件属性和下游元件名称信息。
以下表格为本实验pipeline/unet_simple_opencv.pipeline文件及其对应的名称及描述:


pipeline/unet_simple_opencv.pipeline文件内容如下,可根据实际开发情况进行修改。
{
"unet_mindspore": {
"stream_config": {
"deviceId": "0"
},
"appsrc0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsrc",
"next": "mxpi_imagedecoder0"
},
"mxpi_imagedecoder0": {
"props": {
"cvProcessor": "opencv",
"outputDataFormat": "BGR"
},
"factory": "mxpi_imagedecoder",
"next": "mxpi_imagecrop0"
},
"mxpi_imagecrop0": {
"props": {
"cvProcessor": "opencv",
"dataSource": "ExternalObjects"
},
"factory": "mxpi_imagecrop",
"next": "mxpi_imageresize0"
},
"mxpi_imageresize0": {
"props": {
"handleMethod": "opencv",
"resizeType": "Resizer_Stretch",
"resizeHeight": "960",
"resizeWidth": "960"
},
"factory": "mxpi_imageresize",
"next": "mxpi_tensorinfer0"
},
"mxpi_tensorinfer0": {
"props": {
"dataSource": "mxpi_imageresize0",
"modelPath": "model/unet_hw960_bs1_AIPP.om"
},
"factory": "mxpi_tensorinfer",
"next": "mxpi_dumpdata0"
},
"mxpi_dumpdata0": {
"props": {
"requiredMetaDataKeys": "mxpi_tensorinfer0"
},
"factory": "mxpi_dumpdata",
"next": "appsink0"
},
"appsink0": {
"props": {
"blocksize": "4096000"
},
"factory": "appsink"
}
}
}
修改modelPath
打开pipeline/unet_simple_opencv.pipeline文件,将"mxpi_tensorinfer0"元件的属性"modelPath"(模型导入路径)修改为模型转换后保存的om模型"model/unet_hw960_bs1.om"。
修改结果:
"modelPath": "model/unet_hw960_bs1.om"
modelPath修改完成之后,保存pipeline/unet_simple_opencv.pipeline文件。
StreamManagerApi:
StreamManagerApi文档请参考:
https://support.huaweicloud.com/ug-vis-mindxsdk203/atlasmx_02_0320.html
StreamManagerApi用于对Stream流程的基本管理:加载流程配置、创建流程、向流程发送数据、获得执行结果、销毁流程。
本实验用到的StreamManagerApi有:
• InitManager:初始化一个StreamManagerApi。
• CreateMultipleStreams:根据指定的配置创建多个Stream。
• SendData:向指定Stream上的输入元件发送数据(appsrc)。
• GetResult:获得Stream上的输出元件的结果(appsink)。
• DestroyAllStreams:销毁所有的流数据。
main.py文件内容如下,可根据实际开发情况进行修改。
import argparse
import base64
import json
import os
import cv2
import numpy as np
from StreamManagerApi import *
import MxpiDataType_pb2 as MxpiDataType
x0 = 2200 # w:2200~4000; h:1000~2800
y0 = 1000
x1 = 4000
y1 = 2800
ori_w = x1 - x0
ori_h = y1 - y0
def _parse_arg():
parser = argparse.ArgumentParser(description="SDK infer")
parser.add_argument("-d", "--dataset", type=str, default="data/",
help="Specify the directory of dataset")
parser.add_argument("-p", "--pipeline", type=str,
default="pipeline/unet_simple_opencv.pipeline",
help="Specify the path of pipeline file")
return parser.parse_args()
def _get_dataset(dataset_dir):
img_ids = sorted(next(os.walk(dataset_dir))[1])
for img_id in img_ids:
img_path = os.path.join(dataset_dir, img_id)
yield img_path
def _process_mask(mask_path):
# 手动裁剪
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)[y0:y1, x0:x1]
return mask
def _get_stream_manager(pipeline_path):
stream_mgr_api = StreamManagerApi()
ret = stream_mgr_api.InitManager() #初始化stream
if ret != 0:
print(f"Failed to init Stream manager, ret={ret}")
exit(1)
with open(pipeline_path, 'rb') as f:
pipeline_content = f.read()
ret = stream_mgr_api.CreateMultipleStreams(pipeline_content) # 创建stream
if ret != 0:
print(f"Failed to create stream, ret={ret}")
exit(1)
return stream_mgr_api
def _do_infer_image(stream_mgr_api, image_path):
stream_name = b'unet_mindspore' # 与pipeline中stream name一致
data_input = MxDataInput()
with open(image_path, 'rb') as f:
data_input.data = f.read()
# 插入抠图的功能,扣1800*1800大小
roiVector = RoiBoxVector()
roi = RoiBox()
roi.x0 = x0
roi.y0 = y0
roi.x1 = x1
roi.y1 = y1
roiVector.push_back(roi)
data_input.roiBoxs = roiVector
unique_id = stream_mgr_api.SendData(stream_name, 0, data_input) # 向指定Stream上的输入元件发送数据(appsrc)
if unique_id < 0:
print("Failed to send data to stream.")
exit(1)
infer_result = stream_mgr_api.GetResult(stream_name, unique_id) # 获得Stream上的输出元件的结果(appsink)
if infer_result.errorCode != 0:
print(f"GetResult error. errorCode={infer_result.errorCode},"
f"errorMsg={infer_result.data.decode()}")
exit(1)
# 用dumpdata获取数据
infer_result_data = json.loads(infer_result.data.decode())
content = json.loads(infer_result_data['metaData'][0]['content'])
tensor_vec = content['tensorPackageVec'][0]['tensorVec'][1] # 1是argmax结果
data_str = tensor_vec['dataStr']
tensor_shape = tensor_vec['tensorShape']
argmax_res = np.frombuffer(base64.b64decode(data_str), dtype=np.float32).reshape(tensor_shape)
np.save("argmax_result.npy", argmax_res)
tensor_vec = content['tensorPackageVec'][0]['tensorVec'][0] # 0是softmax结果
data_str = tensor_vec['dataStr']
tensor_shape = tensor_vec['tensorShape']
softmax_res = np.frombuffer(base64.b64decode(data_str), dtype=np.float32).reshape(tensor_shape)
np.save("softmax_result.npy", softmax_res)
return softmax_res # ndarray
# 自定义dice系数和iou函数
def _calculate_accuracy(infer_image, mask_image):
mask_image = cv2.resize(mask_image, infer_image.shape[1:3])
mask_image = mask_image / 255.0
mask_image = (mask_image > 0.5).astype(np.int)
mask_image = (np.arange(2) == mask_image[..., None]).astype(np.int)
infer_image = np.squeeze(infer_image, axis=0)
inter = np.dot(infer_image.flatten(), mask_image.flatten())
union = np.dot(infer_image.flatten(), infer_image.flatten()) + \
np.dot(mask_image.flatten(), mask_image.flatten())
single_dice = 2 * float(inter) / float(union + 1e-6)
single_iou = single_dice / (2 - single_dice)
return single_dice, single_iou
def main(_args):
dice_sum = 0.0
iou_sum = 0.0
cnt = 0
stream_mgr_api = _get_stream_manager(_args.pipeline)
for image_path in _get_dataset(_args.dataset):
infer_image = _do_infer_image(stream_mgr_api, os.path.join(image_path, 'image.png')) # 抠图并且reshape后的shape,1hw
mask_image = _process_mask(os.path.join(image_path, 'mask.png')) # 抠图后的shape, hw
dice, iou = _calculate_accuracy(infer_image, mask_image)
dice_sum += dice
iou_sum += iou
cnt += 1
print(f"image: {image_path}, dice: {dice}, iou: {iou}")
print(f"========== Cross Valid dice coeff is: {dice_sum / cnt}")
print(f"========== Cross Valid IOU is: {iou_sum / cnt}")
stream_mgr_api.DestroyAllStreams() # 销毁stream
if __name__ == "__main__":
args = _parse_arg()
main(args)
run.sh文件内容如下,可根据实际开发情况进行修改。
参考SDK软件包sample脚本,需要按照实际路径修改各个环境变量路径。
set -e
CUR_PATH=$(cd "$(dirname "$0")" || { warn "Failed to check path/to/run.sh" ; exit ; } ; pwd)
# Simple log helper functions
info() { echo -e "\033[1;34m[INFO ][MxStream] $1\033[1;37m" ; }
warn() { echo >&2 -e "\033[1;31m[WARN ][MxStream] $1\033[1;37m" ; }
#export MX_SDK_HOME=${CUR_PATH}/../../..
export LD_LIBRARY_PATH=${MX_SDK_HOME}/lib:${MX_SDK_HOME}/opensource/lib:${MX_SDK_HOME}/opensource/lib64:/usr/local/Ascend/ascend-toolkit/latest/acllib/lib64:${LD_LIBRARY_PATH}
export GST_PLUGIN_SCANNER=${MX_SDK_HOME}/opensource/libexec/gstreamer-1.0/gst-plugin-scanner
export GST_PLUGIN_PATH=${MX_SDK_HOME}/opensource/lib/gstreamer-1.0:${MX_SDK_HOME}/lib/plugins
#to set PYTHONPATH, import the StreamManagerApi.py
export PYTHONPATH=$PYTHONPATH:${MX_SDK_HOME}/python
python3 main.py
exit 0
运行脚本
激活mxVision环境变量(本作业无需此步骤):
. /root/mxVision/set_env.sh
运行脚本:
cd /root/unet_sdk/ # 切换至推理脚本目录
bash run.sh
运行截图如下:

通过MindStudio运行,会自动上传代码到预设路径,并执行,运行结果如下:

- 注意事项:
由于MindX SDK默认日志级别为debug,此日志级别下,dump_data插件会将所有内容打印至终端,影响日志查看。因此可以通过修改日志级别的方式,避免打印不必要的信息。
修改日志:
vi $MX_SDK_HOME/config/logging.conf
按“i”键修改 Line23行,日志级别可改为0或1或2。
# Log level: -1-debug, 0-info, 1-warn, 2-error, 3-fatal
global_level=0
输入“:wq”,保存并退出。
*提醒:实验结束后请及时关闭/删除ECS弹性云服务器,避免资源浪费。
1.3 作业总结
本作业主要介绍如何使用MindSpore框架构建U-Net网络模型,使用线上昇腾算力在工业质检的模拟数据集上进行训练,并将保存的模型编译生成适配昇腾AI处理器的离线模型,部署在华为云ECS上,使用MindX SDK mxVision进行推理,从而实现图像分割的任务。我们希望掌握MindSpore的基础使用,熟悉U-Net网络和图像分割的原理知识,掌握华为云ModelArts和ECS的环境搭建,熟悉昇腾910和昇腾310处理器的使用,掌握离线模型的转换方法,以及熟悉MindX SDK mxVision的使用。
此外,在使用中发现即使使用Windows版本的MindStudio远程连接服务器,仍然有卡顿,通过查看任务管理器,发现其占用的CPU、内存、硬盘和网络资源远超其他应用,考虑到我的电脑可以流畅运行PyCharm、Intellij IDEA、Clion等类似软件,且为本地运行,相比之下,远程连接的MindStudio反而卡顿,个人认为应该还是MindStudio自身资源占用大,优化不足而导致的安顿,这一点,从庞大的安装包也能窥探一二。期待MindStudio未来能有更好的优化。
此外,建议MindStudio能将ssh远程连接服务器放在菜单栏醒目位置,方便查找。