Kafka学习——生产者(三)
目录
1. 一个完整的生产逻辑
2. 参数配置
2.1 三个必配参数
2.2 序列化器(必配)
2.3 分区器(非必配)
2.4 拦截器(非必配)
3. 创建生产者实例
4. 构建待发送的消息
5. 发送消息
5.1 三种发送方式
5.2 两种类型的异常
6. 回收资源
1. 一个完整的生产逻辑
对于Kafka生产者客户端开发而言,一个正常的生产逻辑需具备下面几个步骤:
(1)配置生产者客户端参数及创建相应的生产者实例;
(2)构建待发送的消息;
(3)发送消息;
(4)关闭生产者实例。
示例代码如下:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer {
private static final String brokerList = "localhost:9092";
private static final String topic = "topic-demo";
private static Properties initConfig() {
Properties properties = new Properties();
// broker地址清单
properties.put("bootstrap.servers", brokerList);
// key 序列化器
properties.put("key.serializer", StringSerializer.class.getName());
// value 序列化器
properties.put("value.serializer", StringSerializer.class.getName());
return properties;
}
public static void main(String[] args) {
// 1.配置生产者客户端参数
Properties properties = initConfig();
// 2.创建KafkaProducer实例
KafkaProducer producer = new KafkaProducer<>(properties);
// 3.创建待发送消息
ProducerRecord record = new ProducerRecord<>(topic, "hello, kafka!!!");
try {
// 4.发送消息
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
// 5.关闭生产者客户端实例
producer.close();
}
} GAV坐标如下:
org.apache.kafka
kafka-clients
2.8.0
2. 参数配置
2.1 三个必配参数
- bootstrap.servers :该参数用来指定生产者客户端连接Kafka集群所需的broker地址清单。具体的内容格式为host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为""。注意这里并非需要所有的broker地址,因为生产者会从给定的broker地址里查找到其他broker的信息。不过建议至少设置两个以上的broker地址信息,当其中任意一个宕机时,生产者仍然可以连接到Kafka集群上。
- key.serializer :broker端接收的消息必须以字节数组(byte[])的形式存在。所以在发往broker之前需要将消息中对应的key和value做相应的序列化操作来转换成字节数组。key.serializer和value.serializer这两个参数分别用来指定key和value序列化操作的序列化器。这两个参数无默认值。注意这里必须填写序列化器的全限定名。
- value.serializer :同上。
一般情况下,我们可能无法记住这些参数名。为此,Kafka的ProducerConfig类提供了一系列的参数常量。例如:
bootstrap.servers 可替换为 ProducerConfig.BOOTSTRAP_SERVERS_CONFIG
key.serializer 可替换为 ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG
value.serializer 可替换为 ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG
2.2 序列化器(必配)
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从Kafka中收到的字节数组转换成相应的对象。其实除了示例代码中用到的String 类型的序列化器外,还有ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型,它们都实现了org.apache.kafka.common.serialization.Serializer接口。
生产者使用的序列化器和消费者使用的反序列化器需要一一对应。 如果生产者使用了某种序列化器,比如StringSerializer,而消费者使用了另一种序列化器,比如IntegerSerializer,那么是无法解析出想要的数据的。
如果Kafka客户端提供的几种序列化器都无法满足应用需求,则可以选择使用如Avro、JSON、Thrift、ProtoBuf和Protostuff等通用的序列化工具来实现,或者使用自定义类型的序列化器来实现。
2.3 分区器(非必配)
消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区。
Kafka中提供的默认分区器是org.apache.kafka.clients.producer.internals.DefaultPartitioner, 它实现了org.apache.kafka.clients.producer.Partitioner接口。
除了使用Kafka提供的默认分区器进行分区分配,还可以使用自定义的分区器,只需同 DefaultPartitioner 一样实现Partitioner接口即可。默认分区器在 key为null 时不会选择非可用的分区,我们可以通过自定义的分区器打破这一限制。实现了自定义的分区器后需要通过配置参数 partition.class来显式指定这个分区器。示例如下:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DemoPartitioner.class.getName());2.4 拦截器(非必配)
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器的使用也很方便,主要是自定义实现org.apache.kafka.clients.producer. Producerlnterceptor接口。实现自定义的拦截器之后,需要在KafkaProducer的配置参数interceptor.classes中指定这个拦截器,此参数的默认值为""。示例如下:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, DemoProducerInterceptor.class.getName());KafkaProducer中不仅可以指定一个拦截器,还可以指定多个拦截器以形成拦截链。拦截链会按照interceptor.classes参数配置的拦截器的顺序来一一执行(配置的时候,各个拦截器之间使用逗号分割)。
3. 创建生产者实例
在配置完参数之后, 我们就可以使用它来创建一个生产者实例。示例如下:
KafkaProducer producer = new KafkaProducer<>(props); KafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例,也可以将 KafkaProducer实例进行池化来供其他线程调用。
KafkaProducer中有多个构造方法,比如在创建KafkaProducer实例时并没有设定key.serializer和value.serializer这两个配置参数,那么就需要在构造方法中添加对应的序列化器。示例如下:
KafkaProducer producer = new KafkaProducer<>(props,
new StringSerializer(), new StringSerializer()); 其内部原理和无序列化器的构造方法一样,不过就实际应用而言,一般都选用 public KafkaProducer(Properties properties)这个构造方法来创建KafkaProducer实例。
4. 构建待发送的消息
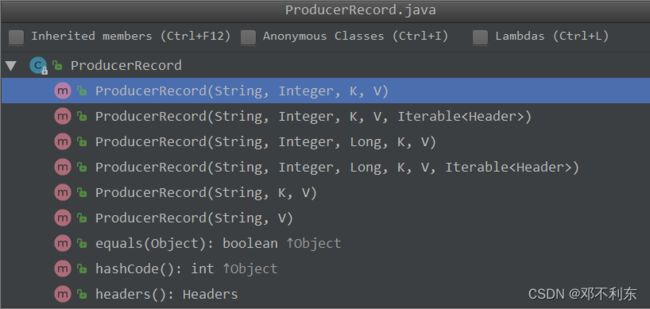
在创建完生产者实例之后,接着就是构建消息,即创建ProducerRecord对象。
Kafka共提供了6种构造方法,如下:
5. 发送消息
5.1 三种发送方式
- 发后即忘(fire-and-forget):这种方式只管往Kafka中发送消息而并不关心消息是否正确到达。在大多数情况下,这种发送方式没有什么问题,不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,但可靠性也最差。
- 同步(sync):这种方式可靠性高。要么消息被发送成功,要么发生异常。如果发生异常,则可以捕获并进行相应地处理,而不会像“发后即忘”的方式直接造成消息的丢失。不过同步发送方式的性能会差很多,需要阻塞等待一条消息发送完之后才能发送下一条。
- 异步(async):一般是在send()方法里指定一个Callback 的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。
5.2 两种类型的异常
- 可重试异常 :常见的可重试异常有:NetworkException、LeaderNotAvailableException, UnknownTopicOrPartitionException、NotEnoughReplicasException、NotCoordinatorException等。比如NetworkException表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;又比如LeaderNotAvailableException表示分区 的leader副本不可用,这个异常通常发生在leader副本下线而新的leader副本选举完成之前,重试之后可以重新恢复。对于可重试的异常,如果配置了retries参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。retries参数的默认值为0,配置方式参考如下:
properties.put(ProduceConfig.RETRIES_CONFIG, 10); - 不可重试异常:比如RecordTooLargeException异常,表示所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。
6. 回收资源
通常,一个KafkaProducer不会只负责发送单条消息,更多的是发送多条消息,在发送完这些消息之后,需要调用KafkaProducer的close()方法来回收资源。目前KafkaProducer提供了两个close方法重载。如下:
- close() : 无参的关闭方法。该方法会阻塞等待之前所有的发送请求完成后再关闭KafkaProducer。在实际应用中,一般使用的都是无参的close()方法。
- close(long timeout, TimeUnit timeUnit) : 带超时时间的关闭方法。该方法会在等待timeout时间内来完成所有尚未完成的请求处理,然后强行退出。