Python学习:Pandas模块入门学习
一、介绍
官网:熊猫文档 — 熊猫 2.0.0 文档 (pydata.org)
pandas 是一个 Python 包,提供快速, 灵活且富有表现力的数据结构,旨在使 “关系”或“标记”数据既简单又直观。它的目标是成为 用于执行实际真实世界数据的基本高级构建块 分析在 Python 中。此外,它还有一个更广泛的目标,即成为 最强大、最灵活的开源数据分析/操作工具 提供任何语言版本。它已经在朝着这个目标迈进。
熊猫非常适合许多不同类型的数据:
具有异类类型列的表格数据,如在 SQL 表中或 Excel电子表格
有序和无序(不一定是固定频率)时间序列数据。
具有行和 列标签
任何其他形式的观察/统计数据集。数据 根本不需要标记即可放入熊猫数据结构中
二、使用
1.包的导入
由于Pandas模块属于第三方库,故使用之前先确保自己已经安装了该库,如未安装,可以在开发环境的终端输入:
pip install pandas来进行安装,安装完成后如下图所示(以VS CODE为例):
2.创建一张表格
(1)DataFrame:
Pandas是一个强大的Python数据分析库,提供了高效的数据结构和数据分析工具。其中的DataFrame就是Pandas的一个核心数据结构,它是一个二维表格,可以存储不同类型的数据,并且可以对数据进行各种操作。
以下是一个创建DataFrame的例子:
如果我想使用Python来建立一个表格,我可以通过DataFrame函数来实现:
import pandas as pd
df=pd.DataFrame(
{
'Names':['Python',
'Java',
'C++',
'R',],
'Year':[1989,1990,1983,1980],
}
)
print(df)在这个例子中,我们使用了一个字典来创建DataFrame,其中字典的键是列名,而值是列数据。Pandas将这个字典转换为DataFrame,并自动为每一列生成一个默认的整数索引。我们可以使用print(df)来打印DataFrame,输出结果如下:
Names Year
0 Python 1989
1 Java 1990
2 C++ 1983
3 R 1980如果我想单独使用某一列数据,我可以输入:
print(df['Year'])结果如下图所示:
0 1989
1 1990
2 1983
3 1980
Name: Year, dtype: int64除了从字典创建DataFrame之外,还有很多其他的方式可以创建DataFrame,例如从CSV文件、数据库、Excel文件等中读取数据,或者手动创建一个空的DataFrame并逐步填充数据。
在创建DataFrame之后,我们可以使用各种方法来操作数据,例如选择子集、过滤、排序、合并、分组、聚合等等。Pandas提供了非常丰富的操作方法和函数,可以帮助我们完成各种复杂的数据处理任务。
(2)Series:
Pandas的Series是另一个重要的数据结构,它是一个一维数组,可以存储不同类型的数据。和DataFrame类似,Series也有一个默认的整数索引,但是我们可以为其指定自定义的索引。
以下是一个创建Series的例子:
import pandas as pd
# 创建Series
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
# 打印Series
print(s)
在这个例子中,我们使用一个列表来创建Series,其中列表的元素是数值。Pandas将这个列表转换为Series,并自动为每个元素生成一个默认的整数索引。我们可以使用print(s)来打印Series,输出结果如下:
0 10
1 20
2 30
3 40
4 50
dtype: int64
除了从列表创建Series之外,还有很多其他的方式可以创建Series,例如从字典、Numpy数组、标量等中创建。和DataFrame一样,Series也可以使用各种方法来操作数据,例如选择子集、过滤、排序、合并、分组、聚合等等。
(3)对数据帧或系列执行某些操作:
.max:
print(df['Year'].max)结果:
1 1990
2 1983
3 1980
Name: Year, dtype: int64.min同理
如果我对我的数据表的数值数据的一些基本统计感兴趣:
df.describe()是一个Pandas DataFrame对象的方法,用于生成DataFrame中数值列的汇总统计信息。默认情况下,
df.describe()会返回以下统计数据:
- count:非空值的数量
- mean:平均值
- std:标准差
- min:最小值
- 25%:第一个四分位数,即25%分位数
- 50%:第二个四分位数,即中位数
- 75%:第三个四分位数,即75%分位数
- max:最大值
print(df.describe()) Year
count 4.000000
mean 1985.500000
std 4.795832
min 1980.000000
25% 1982.250000
50% 1986.000000
75% 1989.250000
max 1990.0000003.对表格的存储与读取:
(1)表格的保存:
to_csv():
根据上面那个例子,如果我们想将创建的表格以csv的形式保存到本地,我们可以使用该代码:
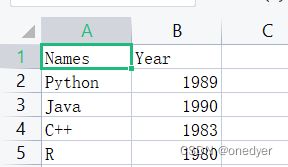
df.to_csv('C:/Users/94152/Desktop/test.csv',index=False)该方法接受文件路径作为参数,可以是相对或绝对路径,上述我们使用to_csv()方法将其保存为名为test.csv的csv文件。index=False参数表示不保存行索引
保存后的文件如下图所示:
(2)表格的读取:
read_csv():
要读取csv文件到pandas DataFrame中,可以使用read_csv()方法:
df=pd.read_csv('C:/Users/94152/Desktop/test.csv')
print(df)运行结果:
Names Year
0 Python 1989
1 Java 1990
2 C++ 1983
3 R 1980head() and tail()
如果要读取表格的前几行,可以输入:
df=pd.read_csv('C:/Users/94152/Desktop/test.csv')
print(df.head(2))其中'2'是行数,结果如图所示:
Names Year
0 Python 1989
1 Java 1990同理,想要读取末尾的,也可以使用
print(df.tail(2)) Names Year
2 C++ 1983
3 R 1980dtypes:
查看数据类型:
print(df.dtypes)Names object
Year int64
dtype: object参考资料
pandas documentation — pandas 2.0.0 documentation (pydata.org)