ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
文章目录
- 摘要
- 结论
- 介绍
- 相关工作
- 数据来源
-
- 预训练语料
- SFT语料
- 基座模型
- Metrics
-
- 通用领域
- 垂域
- 实验结果分析
摘要
本文介绍了针对复杂的家居装修领域而设计的领域特定语言模型ChatHome的开发和评价。考虑到像GPT-4这样的大型语言模型(llm)的成熟能力以及对家庭装修的不断升级的迷恋,本研究通过生成一个专门的模型来调和这些方面,该模型可以产生与家庭装修领域相关的高保真度,精确的输出。ChatHome的新颖之处在于它的方法,在一个广泛的数据集上融合了领域自适应预训练和指令调整。该数据集包括专业文章、标准文档和与家庭装修相关的网络内容。
这种双管齐下的策略旨在确保我们的模型能够吸收全面的领域知识并有效地处理用户查询。通过对不同数据集的彻底实验,包括通用和特定领域,包括新引入的“EvalHome”领域数据集,我们证实ChatHome不仅放大了特定领域的功能,而且保留了其多功能性。
论文原文: ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
不想看全文的,直接看结论
结论
- 以baichuan-13b-base为基座模型,预训练和SFT阶段,垂域数据:通用数据 = 1 : 5 效果最好
- 以baichuan-13b-chat为基座模型,只进行SFT,垂域数据:通用数据 = 1 : 5 效果最好
- 以baichuan-13b-base为基座模型,采用MIP (Multi-Task Instruction Pre Training)的预训练方式,整合下游指令数据,垂域数据:通用数据 = 1 : 0,效果超过以上两种方案
介绍
省略不重要的描述…
本研究提出了一个专门为家居装修设计的语言模型ChatHome。
我们的方法包括两个步骤:
首先,使用广泛的家庭装修数据集(包括专业文章、标准文档和网络内容)对通用模型进行继续预训练。
其次,使用基于家庭装修的提示生成的问答对的策略生成的数据集实现指令微调。
基于家庭装修的提示生成的问答对的策略:使用GPT4生成数据问答对数据集
相关工作
省略不重要的描述…
根据不同的训练阶段,LLM领域的专业训练方法大致可以分为以下几类:
- 直接基于领域数据从头开始预训练,这种方法通常依赖于大量的领域数据,训练成本较高;
- 直接基于领域指令数据进行微调
- 基于领域数据在基础LLM上进行领域预训练,然后进行指令微调。
数据来源
预训练语料
先前的研究表明,语言模型可以从通过特定领域的语料库获得的知识中受益。我们收集了一个特定领域的语料库,用关于家居装饰的知识来增强模型。
此外,我们还编写了一个通用语料库,为模型提供了一个通用知识的平衡。
国家标准: 我们收集了几项国家装饰建筑标准,其中值得一提的是《住宅建筑设计规范》、《房屋装饰施工规范》
领域书籍: 我们收集近十年出版的房地产、家居装修、装修、建筑等领域的书籍
领域网站: 我们抓取家装领域网站,大约有3万篇关于家居装修建议、家居设备购买技巧等类别的文章
通用语料库: 为了构建通用语料库,我们从维基百科简体中文版的WuDaoCorpora中选取文章作为样本。
数据预处理
以上数据通过统一的管道处理,包括文本提取、质量过滤、重复数据删除。在文本提取过程中,我们丢弃不相关的信息,如图片、表格和url,只存储相关的文本。此外,我们通过在文章和句子级别上进行重复数据删除,将重复数据对模型训练的影响降至最低。最终,我们从领域语料库中获得了大约26.6M个tokens,从通用语料库中获得了276.6M个tokens。

SFT语料
为了缓解域偏置问题,提高模型在特定领域的性能,我们从高质量的家装书籍和家装网站文章中构建了大约25k的instruction data,以帮助模型适应特定的领域知识。关于这些提示的详细信息在附录的表5中介绍。

单轮对话: 为了获得更多与家居装饰相关的问题,最初,我们使用GPT4来模拟室内设计师和客户的双重角色,根据给定的知识生成几个问答对。随后,为了获得更详细的答复,我们将上述问题直接提交给GPT-4。这种两步法使我们能够获得更全面、更精确的数据。
多轮对话: 类似于单轮对话,GPT-4模拟了室内设计师和客户的角色,促进了家居装饰领域多回合对话的产生。此外,为了减轻幻觉,我们为GPT-4配备了相关的文章,从而使其对话内容围绕这些提供的知识。此外,我们指导GPT-4保持专注,有机地处理对话。
基座模型
Baichuan-13B-Base: 参数大小为130亿,训练语料库包含1.4万亿个token
Baichuan-13B-Chat: 建立在Baichuan-13B-Base的基础架构上,使用专门的指令进行了微调。因此,它展示了改进的对话生成和指令理解能力。
我们应用前面提到家装领域数据集来微调我们的两个基座模型。为了探索领域自适应预训练(DAPT)在领域自适应方面的优势,我们将对使用DAPT改进的模型进行相同的指令调优实验。
DAPT:使用特定领域的数据集在基座模型上预训练生成的模型
领域适应不可避免地面临灾难性遗忘的问题,其特征是在适应新领域时失去了先前获得的知识。缓解这一问题的一种直接方法是基于预演的策略,其中包括重新访问和重新学习先前获得的知识。考虑到大型语言模型是在广泛的通用数据上预训练的,在领域适应过程中实现通用数据和特定领域的数据之间的平衡是必要的。对于每个实验,我们执行了五组数据比率测试,以确定最有效的数据比率方案。
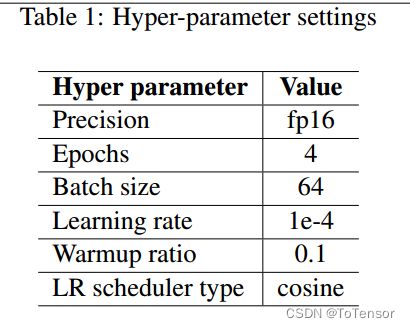
DAPT和SFT阶段的参数配置如表1所示,DADT和SFT阶段训练超参数的唯一区别在于最大长度,DAPT设置为1024,SFT设置为1536。
Metrics
评估对垂域模型的成功至关重要。对于ChatHome,我们不仅希望在模型中注入领域相关的知识,同时也关注模型在域化后的一般能力,因此我们的评估包括一般能力评估和领域能力评估两部分。
通用领域
为了评估模型的一般能力,我们采用了C-Eval和CMMLU,它们都是评估基础模型在中国背景下的高级知识和能力的基准
垂域
据我们所知,目前还没有关于家居装修领域的权威考试。我们构建了一个称为EvalHome的领域评估,它涵盖了三个难度级别:领域基础,领域专业知识和创新设计,分别从低到高的难度。由于选择题是评估领域模型高级能力潜力的一个简单但很好的代理,因此我们以选择题的形式构建所有问题,总共有113个。表2显示了EvalHome的统计信息。

测试集的数据量有点少,总共才113条!
实验结果分析
DAPT模型在一般评价集上的实验结果如表3所示。我们给出了CEval和CMMLU的平均分数。
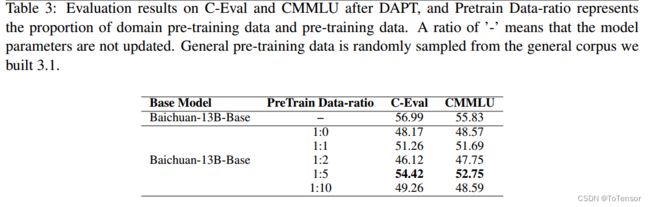
尽管以1:10的比例增加了更多的一般数据,但在1:5的数据比方案下,DAPT模型的一般能力损失最小,在CEval和CMMLU评估集上的平均得分分别比基本模型降低了2.57分和3.08分。
此模型记为:Baichuan-13BBase-DAPT(1:5)。
表4给出了领域适应模型在EvalHome和一般评估集上的实验结果。实验共设4个试验组,其中 Baichuan-13B-Base-DAPT(1:0) 表示DAPT阶段数据比为1:0。我们可以看到,除了Baichuan-13B-Base实验外,其他三个实验, Baichuan-13B-Base-DAPT(1:0),Baichuan-13B-Base-DAPT(1:5) 和Baichuan-13B-Chat,在1:5数据比方案下,都在EvalHome上产生了最好的结果。
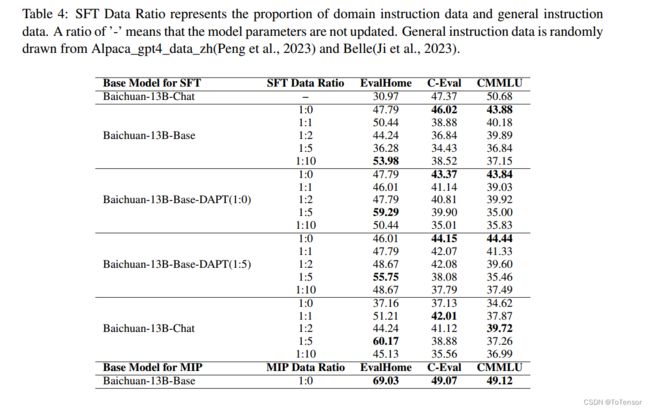
结合这两个表的实验结果,我们可以初步得出结论,在我们现有的基础模型和家装领域数据上,数据比例为1:5时表现最好。
在指令调优阶段,我们观察到一个值得注意的现象:随着更多的通用指令数据的加入,模型在通用能力评估集上的得分降低。这可能归因于评估基准C-Eval和CMMLU的重点,它们主要衡量模型的特定知识,而我们的一般指令数据可能无法涵盖这些知识。
从表4可以看出,使用DAPT后的模型进行指令调优,在EvalHome上分别获得59.29和55.75的最优结果。与未进行DAPT的e Baichuan-13B-Base模型相比略有改善,最高得分为53.98。然而,当使用 Baichuan-13B-Chat t模型进行指令调优时,在EvalHome上获得了更高的60.17分。与未更新参数的 Baichuan-13B-Chat 模型相比,不同数据比下的模型有了明显的改进。这表明,在我们当前的领域场景中,dapt后指令调优并没有显著超越指令对齐模型中的直接领域适应。我们推测这一现象可能是由于Base模型在预训练时已经包含了大量与装饰相关的数据。
意思就是说,使用base模型继续预训练,再进行SFT微调,效果不如直接用chat模型SFT微调
此外,受一些研究作品的启发,展示了在预训练期间整合下游监督数据集的优势,我们试图在DAPT阶段整合下游指令数据。这种策略被称为MIP (Multi-Task Instruction Pre Training),我们在本文中也沿用了这一命名。由于训练资源和时间的限制,我们没有对数据比率进行详细的分析。因此,在MIP阶段,我们的训练数据仅由领域预训练数据和领域指令数据组成,没有添加通用语料库。尽管如此,在EvalHome上获得了69.03的意外得分,如表4的最后一行所示。更令人惊讶的是,该模型不仅在EvalHome上获得了最高分,而且在两个通用能力评估基准上得分更高,因此优于所有其他模型。
研究结果表明,考虑到当前领域数据集和基础模型的条件,在DAPT阶段合并下游指令数据是有益的。我们未来的计划包括在MIP阶段进行更深入的数据比率实验。