机器学习基础笔记
文章目录
- 1.机器学习简介
-
- 1.1 机器学习的一般功能
- 1.2 机器学习的应用
- 1.3 机器学习的方法
- 1.4 机器学习的种类
- 1.5 机器学习的常用框架
- 2. Spark机器学习
-
- 2.1 MLlib介绍
- 2.2 MLlib的数据格式
-
- 2.2.1 本地向量
- 2.2.2 标签数据
- 2.3 MLlib与ml
- 2.4 MLlib的应用场景
- 3.Spark环境搭建
- 4.向量与矩阵
-
- 4.1 向量操作
- 4.2 矩阵操作
- 5.基础统计
-
- 5.1 描述性统计
- 5.2 相关性度量
- 5.3 假设检验
- 6.回归算法
-
- 6.1 线性与非线性
- 6.2 线性回归(LinearRegression)
- 6.3 逻辑回归(logisticRegression)
-
- 6.3.1 正则化原理
- 6.3.2 逻辑回归案例
- 6.4 保序回归
-
- 6.4.1 介绍
- 6.4.2 原理
- 6.4.3 实践
- 6.2 最小二乘法
- 6.3 随机梯度下降
- 7.分类算法
-
- 7.1 朴素贝叶斯算法
-
- 7.1.1 简介
- 7.1.2 贝叶斯定理
- 7.1.2 朴素贝叶斯算法
- 7.1.3 朴素贝叶斯分类实例
- 7.2 支持向量机(svm)
-
- 7.2.1 支持向量机介绍
- 7.2.2 支持向量机算法原理
- 7.2.3 支持向量机实例
- 7.3 决策树
-
- 7.3.1 决策树介绍
- 7.3.2 决策树算法概述
- 7.3.3 决策树算法原理
- 7.3.4 决策树案例
- 无监督学习
- 8.聚类算法
-
- 8.1 Kmeans算法(迭代算法)
-
- 8.1.1 Kmeans算法的描述
- 8.1.2 Kmeans算法案例
- 8.2 LDA算法
-
- 8.2.1 LDA算法概述
- 8.2.2 LDA算法原理
- 8.2.3 LDA算法案例
- 9.降维
-
- 9.1 PCA算法
-
- 9.1.1 PCA算法介绍
- 9.1.2 PCA算法原理
- 9.1.3 PCA实例
- 10.文本情感分类
-
- 10.1 TF-IDF算法
- 10.2 TF-IDF实例
- 11.推荐系统
-
- 11.1 推荐系统简介
- 11.2 推荐系统的原理
- 11.3 推荐系统案例
第一次看机器学习视频,很多公式都是懵的,上学时的高数忘记块差不多了。可能需要重新来补习缺失的知识了。
仅以此来记录学习的过程。
1.机器学习简介
1.1 机器学习的一般功能
分类:识别图像动物 离散的
聚类: 发掘兴趣爱好
回归:预测股市价格 连续的
1.2 机器学习的应用
自然语言处理、数据挖掘、生物信息识别(人脸识别)、计算机视觉
1.3 机器学习的方法
- 统计机器学习(本课程)
- BP神经网络
- 深度学习
1.4 机器学习的种类
(1) 监督学习
学习一个模型,使模型能够对任意给定的输入作出相应的预测
学习的数据形式是(x,y)组合
(2) 无监督学习
(3) 强化学习
训练模型应该避免以下两种情况:
过拟合:模型训练过渡,假设过于严格
欠拟合: 模型有待继续训练,拟合能力不强
1.5 机器学习的常用框架
统计学习: Spark(ml/mllib) scikit-learn Mahout
深度学习: TF,Caffe,Keras (x OnSpark & SparkNet)
2. Spark机器学习
2.1 MLlib介绍
逻辑回归
朴素贝叶斯
线性回归
SVM
决策树
LDA
矩阵分解
2.2 MLlib的数据格式
本地数据:
本地向量和标签数据
数据格式
本地矩阵和分布式矩阵
2.2.1 本地向量
本地向量是存储在本地节点上的,其基本数据类型是Vector
其有两个子集,分别是密集的和稀疏的,通常用Vectors工厂类来生成。
如:
Vectors.dense(1.0,2.0,3.0) 密集的
Vectors.sparse(3,(0,1),(1,2),(2,3)) 稀疏的
2.2.2 标签数据
2.3 MLlib与ml
2.4 MLlib的应用场景
海量数据的分析与挖掘
海量的房屋出租数据,出售信息进行数据挖掘,预测房价,租金
大数据机器学习系统
自然语言处理类的系统,推荐系统等
推荐系统,需要实时进行数据的收集,统计,任务调度,定期更新训练模型
3.Spark环境搭建
4.向量与矩阵
4.1 向量操作
spark-shell
import org.apache.spark.mllib.linalg.Vectors
//spark自带的向量
val v1 = Vectors.dense(1,2,3,4)
//第三方工具breeze, spark已经集成
val v2 = breeze.linalg.DenseVector(1,2,3,4)
//矩阵相加
v2+v2
//矩阵转置
v2.t
v2 * v2.t
4.2 矩阵操作
import org.apache.spark.mllib.linalg.Matrices
//两行三列
val m1 = Matrices.dense(2,3,Array(1,2,3,4,5,6))
val m2 = Matrices.dense(2,3,Array(1,4,2,5,3,6))


使用breeze包
val mb1 = breeze.linalg.DenseMatrix(Array(1,2,3),Array(4,5,6))
//或者
val mb2 = breeze.linalg.DenseMatrix(Array(1,2,3,4,5,6))
//根据上面的转换为2行3列
mb2.reshape(2,3)
//转置:2行3列 转 3行2列
mb2.reshape(2,3).t
//矩阵与自身的转置矩阵相乘
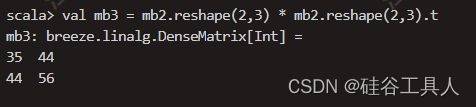
val mb3 = mb2.reshape(2,3) * mb2.reshape(2,3).t
5.基础统计
5.1 描述性统计
平均数
方差
众数
中位数
准备数据: 北京市每年的降雨量数据beijing.txt
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
val df = sc.textFile("/tmp/king/beijing.txt")
val df2 = df.map(x=> Vectors.dense(x.toDouble))
val df3 = Statistics.colStats(df2)
df3.max
df3.mean //均值
df3.min
df3.count
![]()
5.2 相关性度量
一种研究变量之间线性相关程度的度量
常用的相关系数有:
皮尔逊和斯尔曼相关系数,反应变量间相关关系密切程度
- 皮尔逊相关系数

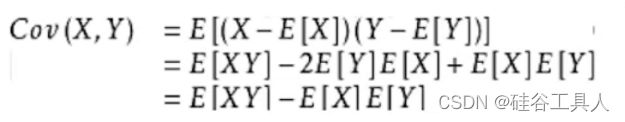
准备的数据北京的降雨量,年份,降雨量:
2022,0.4925
2021,0.6984
2020,0.5271
2019,0.4063
2018,0.5465
2017,0.5762
2016,0.6691
2015,0.5981
2014,0.4615
2013,0.5084
2012,0.7332
2011,0.7211
2010,0.5225
2009,0.4806
2007,0.4839
2006,0.318
2005,0.4107
2004,0.4835
2003,0.4445
2002,0.3704
2001,0.3389
2000,0.3711
1999,0.2669
1998,0.7317
1997,0.4309
1996,0.7009
1995,0.5725
1994,0.8132
1993,0.5067
1992,0.5415
1991,0.7479
1990,0.6973
1989,0.4422
1988,0.6733
1987,0.6839
1986,0.6653
1985,0.721
1984,0.4888
1983,0.4899
1982,0.5444
1981,0.3932
1980,0.3807
1979,0.7184
1978,0.6648
1977,0.779
1976,0.684
1975,0.3928
1974,0.4747
1973,0.6982
1972,0.3742
1971,0.5112
1970,0.597
1969,0.9132
1968,0.3867
1967,0.5934
1966,0.5279
1965,0.2618
1964,0.8177
1963,0.7756
使用皮尔逊系数公式,计算年份与降雨量的相关系数
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
import org.apache.spark.sql.SparkSession
val df= spark.sparkContext.textFile("/tmp/king/beijing2.txt")
val df2 = df.map(x=> (x.split(",").apply(0).toDouble,x.split(",").apply(1).toDouble))
val df_year = df2.map(_._1)
val df_val = df2.map(_._2)
val result = Statistics.corr(df_year,df_val)

由于计算结果的绝对值0.14,所以年份与降雨量相关性很小。
5.3 假设检验
根据一定的假定条件,由样本推断总体的一种统计学方法。
基本思路:先提出假设(虚无假设),使用统计方法进行计算,根据计算结果判断是否拒绝假设。
假设检验的统计方法:卡方检验、T检验等。
皮尔森卡方检验是最常用的卡方检验,可以分为适配度检验和独立性检验。
适配度检验:验证观察值的次数分配与理论值是否相等。
6.回归算法
6.1 线性与非线性
线性 就是两个变量之间存在一次方函数关系。
自然界中变量间更多的关系是非线性的,绝对的线性关系相对很少。
在选择数据模型进行拟合的时候,很多情况使用非线性函数构造的模型比线性函数模型更好。
6.2 线性回归(LinearRegression)
线性回归案例,根据房子的面积预测价格
准备的数据:
先读取房产价格数据
val df = spark.read.format("csv")
.option("header","true")
.option("sep",";")
.load(path + "/ai_demo/file/house.csv")
.drop("blank")
import spark.implicits._
选择面积和价格字段,然后将数据集顺序打乱
//选取面积和价格
val random = new Random() //加入随机数,为了打乱排序
val data = df.select("square","price")
.map(x=> (x.getAs[String](0).toDouble,x.getAs[String](1).toDouble, random.nextDouble()))
.toDF("square","price","rand")
.sort("rand") //打乱顺序
包装数据集
val ass = new VectorAssembler().setInputCols(Array("square")).setOutputCol("features")
val ds = ass.transform(data) //特征包装
features是将面积字段包装后的特征

拆分为训练数据集和测试数据集
val Array(train,test) = ds.randomSplit(Array(0.8,0.2))
创建一个线性回归的实例
val regression = new LinearRegression() //创建一个线性回归实例
.setMaxIter(100) //最大迭代次数
.setRegParam(0.3) //设置正则化参数,防止过拟合
.setElasticNetParam(0.8) //弹性网络参数
使用线性回归实例来训练数据
val model = regression //线性回归实例
.setLabelCol("price") //指定标签列
.setFeaturesCol("features") //特征向量
.fit(train) //训练
使用训练好的模型,用于测试数据集的预测
val result = model.transform(test)
注意
fit方法: 使用训练数据集train训练
transform方法:使用测试数据集test做预测的
最后查询,预测结果
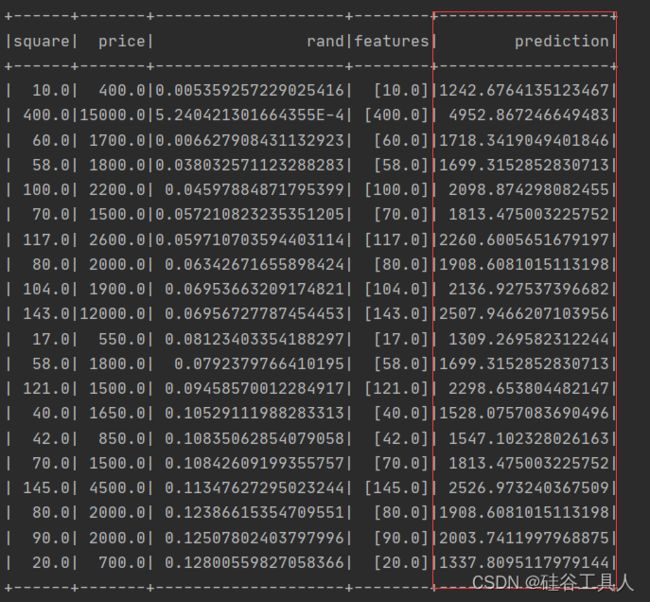
result.show()
下面prediction字段即为预测的结果,通过测试集的预测结果和price列的实际值对比。
可以发现用线性回归(使用面积特征)来预测实际的房价并不准确。
所以本例子仅仅实现了一个机器学习的工程化的具体步骤。
(1)数据的加载
(2)指定特征值
(3)拆分数据集
(4)模型训练
(5)利用训练的模型预测结果。
6.3 逻辑回归(logisticRegression)
逻辑回归是一种广义上的线性回归,但是与线性回归模型不同的是,其中引入了非线性函数。
逻辑回归原理:
Sigmoid函数,也即Logister函数,是一个非线性函数。
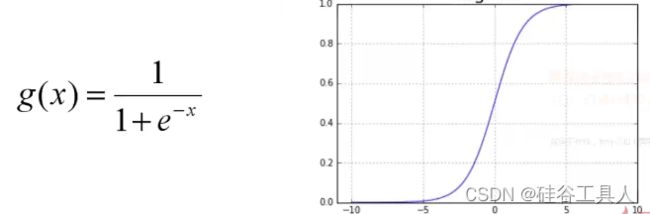
6.3.1 正则化原理
过拟合、欠拟合、刚刚好
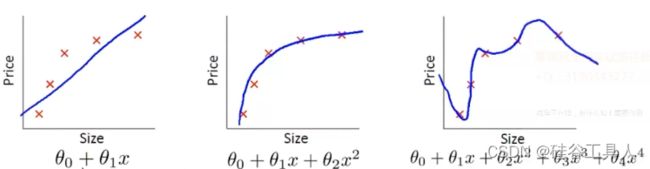
对于过拟合现象,往往都是模型过于复杂,超过实际需要。
因此,在损失函数的计算中,对模型的复杂程度进行量化,越复杂的模型,越对其进行“惩罚”,以便使模型更加“中庸”。
以上即是正则化的思想,通过动态调节惩罚程度,来防止模型过于复杂。
6.3.2 逻辑回归案例
使用的数据集依然是上面的线性回归的数据集:
val lr = new LogisticRegression()
.setLabelCol("price")
.setFeaturesCol("features")
.setRegParam(0.3)
.setElasticNetParam(0.8)
.setMaxIter(10)
//训练
val model = lr.fit(train)
//预测
val result = model.transform(test)
result.show()
可以发现用逻辑回归(使用面积特征)来预测实际的房价并不准确。

6.4 保序回归
6.4.1 介绍
保序回归的应用
保序回归用于拟合非递减数据,不需要事先判断线性与否,只需数据总体的趋势是非递减的即可。
例如研究某种药物的使用剂量与药效的关系。
6.4.2 原理
6.4.3 实践
//保序回归
val ir = new IsotonicRegression()
.setLabelCol("price")
.setFeaturesCol("features")
//训练
val model = ir.fit(train)
val result = model.transform(test)
result.show()
可以发现用保序回归(使用面积特征)来预测实际的房价还是比较准确的。

6.2 最小二乘法
一种优化方法
6.3 随机梯度下降
概念解释:
随机梯度下降是一种机器学习中常用的优化方法,它是通过不断迭代更新的手段,来寻找一个函数的全局最优解的方法。
随机梯度下降特别适合变量众多,受控系统复杂的模型,尤其在深度学习中具有十分重要的作用。
梯度是微积分中的一个算子,用来求某函数在该点沿着哪条路径变化最快,通俗理解就是在哪个路径上几何形态更为陡峭。
数学表达式(以二元函数为例):
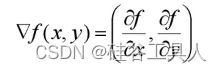
随机梯度下降原理:
线性模型的梯度下降推导过程:

随机梯度下降的优点:
随机梯度下降的“随机”体现在进行梯度计算的样本是随机抽取的n个,与直接采用全部样本相比,这样计算量更少。
随机梯度下降善于解决大量训练样本的情况
学习率决定了梯度下降的速度,同时,在SGD的基础上引入了“动量”的概念,从而进一步加速收敛速度优化算法也陆续被提出。
7.分类算法
参考文章:https://www.showmeai.tech/tutorials/34?articleId=189
7.1 朴素贝叶斯算法
7.1.1 简介
朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的一种分类方法
朴素贝叶斯算法是一种基于联合概率分布的统计学习
7.1.2 贝叶斯定理
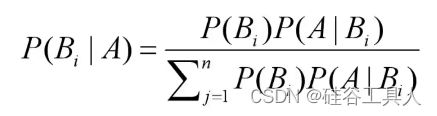
贝叶斯定理的三个应用:
(1)朴素贝叶斯分类器
(2)判别函数和决策面
(3)贝叶斯参数估计
7.1.2 朴素贝叶斯算法

7.1.3 朴素贝叶斯分类实例
这里是鸢尾花分类,通过朴素贝叶斯来实现分类。
def naiveBayesDemo(data:Dataset[Row]) = {
data.show(10)
//特征包装
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3")) //输入特征
.setOutputCol("features")
val ds = assembler.transform(data)
//拆分成训练集和预测集合
val Array(train,test) = ds.randomSplit(Array(0.8,0.2))
//贝叶斯训练
val bayes = new NaiveBayes().setFeaturesCol("features").setLabelCol("label")
val model = bayes.fit(train) //训练数据集
val result = model.transform(test) //预测结果
result.show()
}
/**
* 数据集预处理
* @param spark
* @return
*/
def dataProcess(spark:SparkSession):Dataset[Row] = {
val df = spark.read.format("csv").load(path + "/ai_demo/file/iris.data")
val random = new Random()
import spark.implicits._
val df2 = df.map(x=>{
val label = x.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
}
(
x.getString(0).toDouble,
x.getString(1).toDouble,
x.getString(2).toDouble,
x.getString(3).toDouble,
label,
random.nextDouble()
)
}).toDF("_c0","_c1","_c2","_c3","label","rand").sort("rand") //打乱顺序
df2
}
朴素贝叶斯分类支持多特征分类,预测的结果也是非常准确。
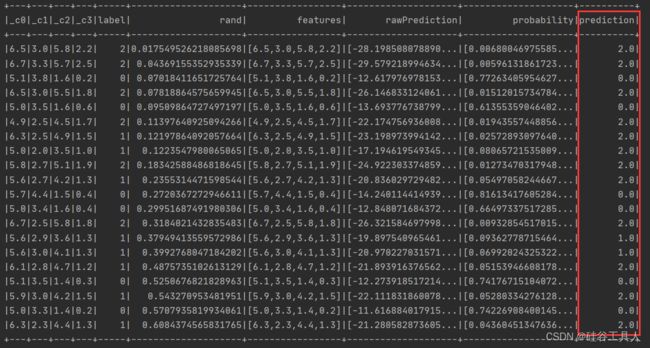
7.2 支持向量机(svm)
7.2.1 支持向量机介绍
7.2.2 支持向量机算法原理
简单的分类,通过划分“阈值”。
SVM处理非线性的问题
SVM的核函数:
SVM虽然只能进行线性分类,但是,可以通过引入核函数,将非线性的数据转化为另一个空间中的线性可分数据。
这叫做支持向量机的核技巧,可以认为是支持向量机的精髓之一。
7.2.3 支持向量机实例
//支持向量机分类
def svmDemo(data:Dataset[Row]) = {
// data.show(10)
val data2 = data.filter("label = 1 or label = 0")
//特征包装
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3")) //输入特征
.setOutputCol("features")
val ds = assembler.transform(data2)
//拆分成训练集和预测集合
val Array(train,test) = ds.randomSplit(Array(0.8,0.2))
val svm = new LinearSVC()
.setMaxIter(20).setRegParam(0.1)
.setFeaturesCol("features").setLabelCol("label")
val model = svm.fit(train)
val result = model.transform(test)
result.show()
}
/**
* 数据集预处理
* @param spark
* @return
*/
def dataProcess(spark:SparkSession):Dataset[Row] = {
val df = spark.read.format("csv").load(path + "/ai_demo/file/iris.data")
val random = new Random()
import spark.implicits._
val df2 = df.map(x=>{
val label = x.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
}
(
x.getString(0).toDouble,
x.getString(1).toDouble,
x.getString(2).toDouble,
x.getString(3).toDouble,
label,
random.nextDouble()
)
}).toDF("_c0","_c1","_c2","_c3","label","rand").sort("rand") //打乱顺序
df2
}
def getSpark():SparkSession = {
val conf = new SparkConf().setMaster("local[*]").setAppName("ai")
SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
}
svm本身是支持多分类的,但是在spark的ml包中的svm只支持二分类,所以使用的数据集只保留了label为0和1两个标签。
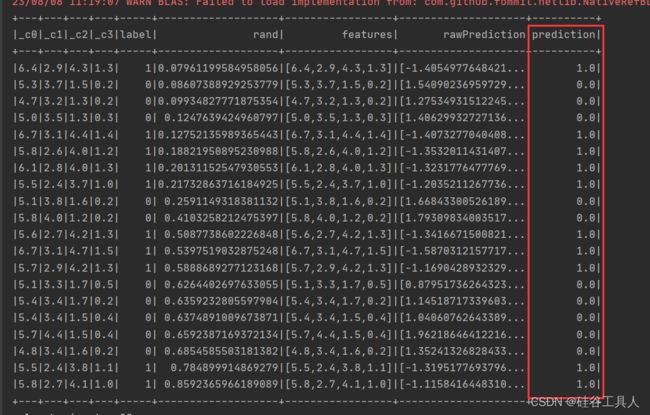
通过svm分类算法,我们可以看到预测结果非常准确。
7.3 决策树
7.3.1 决策树介绍
7.3.2 决策树算法概述
- 决策树的优点:
决策树原理简单,易于实现
决策树能够实现多分类
能够在较短的时间内对大型数据源作出预测,预测性能较好 - 决策树的缺点:
对输入的特征要求较高,很多情况下需要做预处理
识别类别过多时,发生错误的概率较大。
7.3.3 决策树算法原理
如果展示的是一个能否批准贷款的决策树
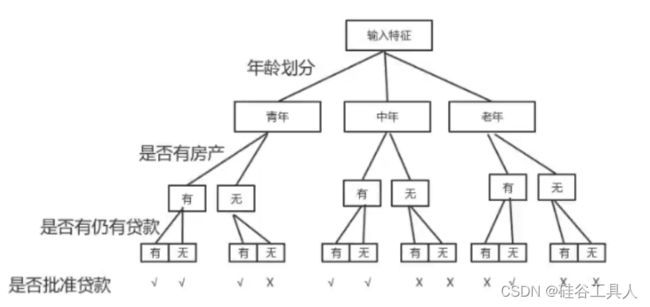
决策树的特征选择:
信息增益(信息熵)
当得知x而使得y的不确定性减少的程度,即为信息增益。
决策树之ID3算法
- ID3算法是一种决策树生成算法,其对于决策树各个节点应用信息增益准则,从而选取特征。
在树的每一层进行递归,从而构建整棵树。
决策树之CART算法
CART即分类与回归决策树,其中一棵二叉树,根据判断结果划分“是否”二分类。
决策树生成:基于训练集生成一个尽可能大的决策树。
决策树剪枝:使用验证对生成的决策树进行剪枝,以便使损失函数最小化。
7.3.4 决策树案例
/**
* 决策树分类
*/
def decisionTreeDemo(data:Dataset[Row]) = {
//特征提取
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3")) //输入特征
.setOutputCol("features")
val dt = assembler.transform(data)
//准备数据集
val Array(train,test) = dt.randomSplit(Array(0.8,0.2))
val decisionTree = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("label")
//模型训练
val model = decisionTree.fit(train)
val result = model.transform(test)
result.show()
//预测评估器
val evalutor = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evalutor.evaluate(result)
println("accuracy:" + accuracy)
}

最后可以看到预测评估器的分值为0.896,所以分类结果准确率还是比较高的。
无监督学习
8.聚类算法
8.1 Kmeans算法(迭代算法)
8.1.1 Kmeans算法的描述
设置需要聚类的类别个数K,以及n个训练样本,随机初始化K个聚类中心。
计算每个样本与聚类中心的距离,样本选择最近的聚类中心作为其类别;重新选择聚类中心
迭代执行上一步,直到算法收敛。
8.1.2 Kmeans算法案例
def clusteringDemo(data:Dataset[Row]) = {
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val Array(train,test) = dataset.randomSplit(Array(0.8,0.2))
val kmeans = new KMeans().setFeaturesCol("features")
.setK(3) //聚类份数
.setSeed(1L) //随机种子
.setMaxIter(20) //最大迭代数
val model = kmeans.fit(train)
val result = model.transform(test)
result.show()
}

8.2 LDA算法
8.2.1 LDA算法概述
(主要用于自然语言处理,可以应用文档主题分类)
LDA即文档主题生成模型,该算法是一种无监督学习
将主题对应聚类中心,文档作为样本,则LDA也是一种聚类算法
该算法用来将多个文档划分为K个主题,与Kmeans类似
8.2.2 LDA算法原理
LDA是一种基于概率统计的生成算法
LDA算法一种常用的主题模型,可以对文档主题进行聚类,同样也可以用在其他非文档的数据中。
LDA算法是通过找到词、文档与主题三者之间的统计学关系进行推断的。
文档的条件概率:

8.2.3 LDA算法案例
def ldaDemo(data:Dataset[Row]) = {
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val Array(train,test) = dataset.randomSplit(Array(0.8,0.2))
val lda = new LDA().setFeaturesCol("features")
.setK(3)
.setMaxIter(40)
val model = lda.fit(train)
val prediction = model.transform(train)
val ll = model.logLikelihood(train) //最大似然估计
val lp = model.logPerplexity(train)
val topics = model.describeTopics(3)
prediction.select("label","topicDistribution").show(false)
topics.show(false)
println(s"The lower bound on the log likelihood of then entire corpus: $ll")
println(s"The upper bound on the perplexity: $lp")
}
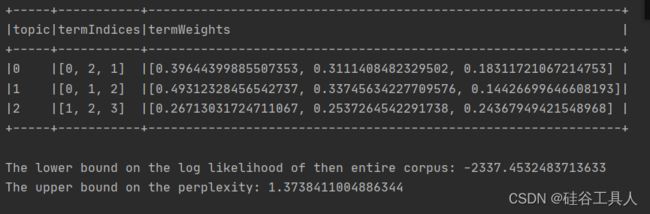
termIndices 表示的是词
termWeights 表示的是词的权重
9.降维
9.1 PCA算法
9.1.1 PCA算法介绍
如何降维:
从高纬度变为低纬度的过程就是降维。
例如拍照就是把处在三维空间中的人物转换到二维平面的照片中。
降维有线性的,也有非线性的方法,在机器学习中,可以简化运算,减少特征量。
PCA算法是一种常用的线性降维算法,算法类似于“投影”
降维简化了数据集,故可以视为一个压缩过程,在压缩过程中可能会有信息丢失。
PCA算法可以用来精简特征,还可以应用在图像处理中,例如PCA算法用来人脸识别,
9.1.2 PCA算法原理
PCA是基于K-L变化实现的一种算法
PCA算法在实现上用到了协方差矩阵,以及矩阵的特征分解
基本主要内容在于求出协方差矩阵,然后求协方差矩阵的特征值与特征向量
PCA算法步骤:
(1)输入n行m列的矩阵X,代表m条n维数据
(2)将矩阵X的每一行进行零均值化处理
(3)求出X的协方差矩阵C
(4)求出协方差矩阵C的特征值和特征向量(特征分解)
(5)将特征向量按照特征值的大小从上到下依次排列,取k行,作为矩阵P
(6)求出矩阵P与X矩阵叉乘的结果,即为降维值k维的m条数据
9.1.3 PCA实例
/**
* 利用PCA算法将4个特征降维为3个特征
* 并且计算特征量减少时,准确率变化
* @param data
*/
def pcaDemo(data:Dataset[Row]) = {
//输入4个特征,转成向量featrues
val assembler = new VectorAssembler()
.setInputCols(Array("_c0","_c1","_c2","_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val pca = new PCA()
.setInputCol("features") //将向量features转换为向量features2
.setOutputCol("features2")
.setK(3) //设置输出向量的特征数为3
val pcaModel = pca.fit(dataset) //训练
val dataset2 = pcaModel.transform(dataset) //将4个特征转换为3个特征
val Array(train,test) = dataset2.randomSplit(Array(0.8,0.2))
val dt = new DecisionTreeClassifier()
.setFeaturesCol("feature2")
.setLabelCol("label")
val model = dt.fit(train)
val result = model.transform(test)
result.show()
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(result)
println(s"""accuracy is $accuracy""") //当4个特征降维3个特征时,验证分类算法结果的准确率
}
10.文本情感分类
10.1 TF-IDF算法
10.2 TF-IDF实例
11.推荐系统
11.1 推荐系统简介
11.2 推荐系统的原理
物品信息、用户信息、用户对物品的偏好程度
基于用户:相似用户的喜好推荐
基于内容:基于用户的兴趣相似标签推荐
协同过滤算法
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性
然后基于这些关联性进行推荐,基于协同过滤的推荐可以分为三个子类:
基于用户的推荐(user-based)
基于项目的推荐(item-based)
基于模型的推荐 (rating 评分)
如何选择:
amazon - 物品数量相对稳定,且远少于用户数 (item)
新闻网站 - 用户数量相对稳定,且远少于新闻 (user)