借助 Flink 与 Pulsar,BIGO 打造实时消息处理系统
摘要:本文整理自 BIGO Staff Engineer 陈航在 Flink Forward Asia 2020 分享的议题《借助 Flink 与 Pulsar,BIGO 打造实时消息处理系统》。主要内容包括:
关于 BIGO
BIGO 为什么会选择 Apache Pulsar
Apache Pulsar 在 BIGO 中的角色
BIGO 借助 Apache Pulsar 和 Flink 构造实时消息流处理系统。
未来计划
借助于大数据和人工智能技术,BIGO 基于视频的服务和产品获得了广泛的欢迎,在 150 多个国家和地区获得了大量的用户。BIGO 主要有两款非常流行的产品,第一款是 BIGO Live,另外一款是 Likee。BIGO Live 是一个直播平台,而 Likee 是一个短视频平台。

二、为什么选择 Apache Pulsar
在过去的几年里,BIGO 的消息平台主要还是以开源的 Kafka 集群为主,但是随着业务的不断增长、用户不断扩充,整个消息流平台所承载的消息量和数据量也出现了成倍的增长,同时也对整个消息流系统提出了更高的要求。
主要体现在以下几个方面:
第一,它对整个系统的稳定性、可扩展性以及鲁棒性提出了更高的要求。
第二,由于我们是短视频推荐相关的服务,所以对整个消息流的低延迟也提出了非常高的要求。
随着数量增长,整个 BIGO 的消息流平台的团队在维护多个 Kafka 集群上付出了大量的工作,摆在我们面前的有很多 Kafka 集群运维相关的问题。这个时候,我们就在思考,我们是选择开源 Kafka 的一个基线版本进行自己的迭代开发呢?还是看一下开源社区里面有哪些可以借鉴的方案,来打造一个符合我们应用场景需求的消息流平台。
于是我们进行了一系列调研。在调研的过程中,我们的目光注意到了 Apache Pulsar,它有以下几点 feature 比较 match 我们的应用场景:
首先,它能够水平地扩展。我们知道对于 Kafka 而言,它是一个服务和存储绑定的系统。当我们需要去扩容一个集群的时候,单单把机器上线是不能够满足需求的,我们需要对整个 topic 的 partition 进行相应操作,这个时候就是耗人力去运维的。所以,我们需要有一个能够水平扩展的系统。而 Apache Pulsar 提供的是存储和服务分离的一个架构,使用的是 bookkeeper 作为底层的数据存储,上层有一个 broker 来提供相关的服务。
另外,就是它的 low latency 还有高吞吐、低延迟以及在雅虎的生产环境上面经受了大数据量的考验。
跨集群的复制等一系列的 feature 对于我们而言也是非常需要的。
并且,这样一个存储和服务分离的架构也极大地减少了人工运维的成本。
所以我们选择了 Apache Pulsar。

三、Apache Pulsar 在 BIGO 中的角色
1. 引入 Pulsar 的历程
在 2019 年 11 月,我们重新开始思考 BIGO 的应用场景下面所需要的消息流平台到底是什么样的。是基于一个开源的 Kakfa 框架去开发,还是选择另外一套整个消息流系统?
在 2019 年 11 月份,我们做了一次整个消息流平台的调研工作。在调研过程中,我们对比了 Kafka、RocketMQ、Apache Pulsar 等业界相近的相对的消息队列的实现。然后我们做了一系列的横向对比,并且跟我们的业务需求进行了相应的比较。最终发现使用 Apache Pulsar 能够解决我们生产上的一些问题,能够为我们的消息流平台提供非常好的运维相关的负担的减轻,以及整个系统的稳定性和吞吐的提升,所以我们就选择了 Apache Pulsar。
在 2019 年 12 月份,我们进行了一系列的压测。任何一个开源的框架,如果没有经过公司内部的大流量场景下的压测,是不敢上线的。所以从 2019 年 12 月份一直到 2020 年 4 月份,经过了一系列的长时间的压测工作。
在压测的过程中,我们同时也发现了 Apache Pulsar 的一些问题,并且给社区修了一系列的 bug。在 2020 年 4 月份,我们把 Apache Pulsar 部署在了我们的生产测试环境;在稳定运行一个月之后,我们就把它部署到了生产环境;在 2020 年 5 月份,正式上线。
现有的 Apache Pulsar 集群规模,目前有十几个 Apache Pulsar 的节点。整个集群的入流量是在 2~3 GB/s。随着时间的推移,也有越来越多的应用会不断地迁移到 Apache Pulsar 来替代现有的 Kafka 集群。

2. Apache Pulsar 的角色
Apache Pulsar 在整个流处理过程中提供的是一个 PUB-SUB 的角色。
首先,有 BIGO 这边的 Baina,一个 C++ 实现的消息收集服务,把相关的数据写到 Apache Pulsar 相关的 topic 里面去,这是第一种场景。
第二场景就是 KMM,也就是 Kafka 的 Mirror Maker。
第三种场景是 Flink。另外就是一些各种语言的客户端所实现的 producer。它的下游主要有 Flink、Flink SQL 以及各个语言所实现的 consumer,比如说 golang、JAVA,C++ 的等等。

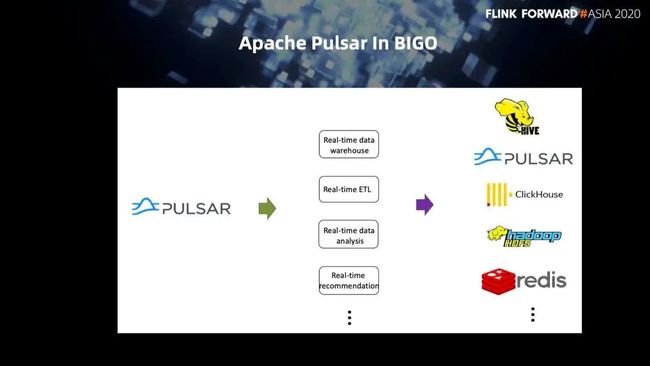
3. 下游支撑的业务场景
第一个是实时数仓,第二个是实时的 ETL,第三个是实时数据分析,另外就是实时推荐,还有更多的业务场景也在逐渐的介入。下游的数据会写到 HIVE、Pulsar 的 topic、ClickHouse、Hadoop、redis 等一系列下游的相关存储系统。
四、Apache Pulsar 和 Flink
构造实时消息流处理系统
这里需要分为以下三个方面来讲:
第一,是关于 Pulsar-Flink-Connector 的一些内幕。我相信在介绍 Pulsar-Flink-Connector 的一些内幕之后,大家会对整个 Flink 与 Pulsar 之间结合的关系会更加地清晰明亮,在使用过程中也会更加地清晰;
第二,是 BIGO 的一个 use case,就是使用 Apache Pulsar 和 Flink 来打造自己的实时 ETL 处理系统;
第三,是借助 Apache Pulsar 和 Flink 打造 AB-test 系统。
首先看一下 Pulsar-Flink-Connector 整个生产和消费的逻辑。它主要包括一个 source 的 API 和 sink 的 API。对于消费的时候,也就是使用一个 Pulsar-Flink-Connector 的 source 来订阅 Pulsar 的一个 topic。另外一个就是我们写一个 sink,会把 Flink 里面的数据写出到 Pulsar 的 topic 里面。下图左边的代码展示怎么去订阅这样一个 topic,实际上只需要 new 一个 FlinkPulsarSource 的一个流,然后把这条流加入到 DataStream 里面去就可以了。

对于 Flink 数据的写出而言,只需要 new 一个 FlinkPulsar 的 Sink,然后我们调用第二个 DataStream 的 sink 就可以把数据给写出去了。实际上,整个的实现而言,跟 Kafka 的 API 是非常类似的。这里需要注意的几点就是,对于 FlinkPulsarSource 里面需要传入的是 serviceUrl 以及 adminUrl。
serviceUrl 类似于 Kafka 的 broker_list;
adminUrl 就是我们去以管理员的方式来控制 Pulsar 的一些相关的操作。
Pulsar Flink 怎么样来订阅 Pulsar 的 topic,怎么样消费以及它的 offset 是怎么样 commit 回去的?
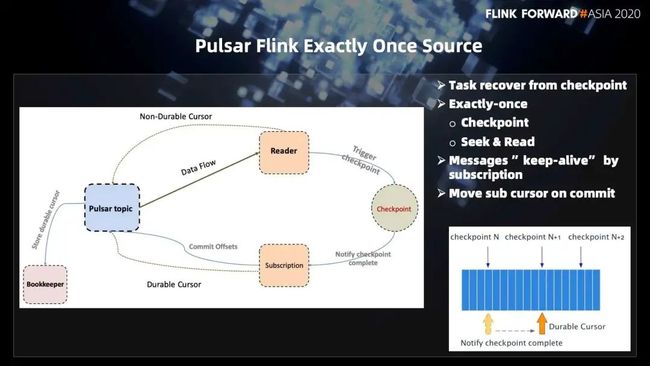
这里就会涉及到 Pulsar Flink 的 exactly-once source。咱们首先来看一下图左边部分。这个图里面有一个 Pulsar 的 topic,当我们 new 一个 PulsarFlinkSource 的时候,实际上会对每一个 Pulsar topic 的 partition 创建一个 reader。这个 reader 使用的是 Non-Durable Cursor,当这个 reader 订阅了这个 topic 之后,这个 topic 的数据流就会源源不断地流到这个 reader 的线程里面去。当 reader 的线程触发一次 checkpoint 的时候,这个 Flink 任务就会把自己的一些状态 checkpoint 起来。当 checkpoint 完成的时候,就会调用一次 Notify checkpoint complete 这样的一个方法。触发的是另外一个 subscription 的一个 commit。
这个 subscription 实际上是一个 durable cursor。当它 commit offset 的时候,这个 offset 会保存在 bookkeeper 里面,这是一个永久保存的 offset。这样做的好处是,当 checkpoint 失败或者 checkpoint 丢了的时候,我们需要以一个 subscription name 从 Pulsar 里面去恢复的时候,就可以从 bookkeeper 里面去把 message id 读出来,然后从这边恢复。
实际上对于 Pulsar-Flink-Connector 的消费而言,它是由一条数据流和一条控制流来组成的:
对于数据流,就是 Pulsar Topic 的数据源源不断的会流入到 reader 的这样一个线程里面,由 reader 线程进行相应的处理。
控制流就是通过 subscription name 来提交消费的 message id,也就是类似于 Kafka 的一个 offset,会提交到 Pulsar 的客户端来保证消费的位置。
接下来看一下 checkpoint 实现的流程。
首先,当我们去做 checkpoint N 的时候,当 N 结束了之后,它会把 durable cursor 进行一次 commit;
当我们去做 checkpoint N+1 的时候,N+1 完成之后,会接着去 commit N+1 的 durable cursor。
这样做的好处是,当这个任务失败之后,如果需要从某一个 checkpoint 恢复,只需要从 checkpoint 里面去读到上一次 checkpoint 成功的 offset 的 durable cursor 的 message id 的位置,就可以从上一次的位置去消费了。这也是保证 source 的 exactly once 的实现。
Topic/Partition 的 Discovery
第一点是,在 Pulsar-Flink-Connector 实现的逻辑里,会为每一个 Topic/Partition 分配一个 reader 的线程。
第二点是,每一个 task manager 会包括多个 reader 的线程,这地方会有一个什么样的映射关系?
举个例子:假设我们订阅的 Topic 里面,有 10 个 partition,Flink 里面只给它分配 5 个 task manager,那么怎么将 partition 映射到 5 个 task manager 里面去?这就会涉及到一个分配的逻辑。整个分配的逻辑,实际上是使用一个哈希的方式把某一个 Topic/Partition hash 到目标的 task manager 上面。
这就会存在一些隐患:当我们订阅了几百个甚至上千个 topic 的时候,可能会存在一定的分配不均衡。成百上千个 Topic/Partition 里面,并不是每一个 partition 的流量都是均衡的。假设我们订阅了十个 Topic,其中有九个 Topic 的流量很小,另外一个 Topic 的流量很大,那么均摊到某一个 partition 时候也是这样的。这个很大的 topic 的 Partition 的流量很大,另外 Topic/Partition 的流量很小。如果我们只是单纯地进行一次 hash 的话,就会造成某些 task manager 上面的流量不均衡,可能会导致频繁 GC 的问题。这个问题在下一个 use case 里会详细地提到,以及怎么样去解决它。
另外就是当某一个 Topic/Partition 进行一次分区扩容时,怎么样去自动订阅这样一个新的分区?在 Pulsar-Flink-Connector 里面会启动一个定时 check 的线程的逻辑。假设我们每一分钟 check 一次,是否有新的 partition 的加入,并且这个新 Topic/Partition 分配到了某一个 task manager 上面,那么这个 task manager 就会自动地新创建一个 reader 的线程,然后把这个 partition 订阅下来。
这整个的流程,会有一个 discover 会不断的去 check。当有新的 partition 的时候就会 new 一个 reader 起来。每一个 reader 独立消费某一个 Topic/Partition,把数据拿过来之后会定期进行自己的反序列化操作以及后续的处理。

上面讲到的是整个 connector 的一个逻辑。在 Pulsar-Flink-Connector 里面提供了 job 的方式,还提供了 catalog 的方式来消费 Pulsar 的 topic。但是目前它是没有提供 SQL DDL 的方式,在 BIGO 的应用场景里面大部分的 topic 都是以 json 的格式。大部分的数据,都是以 json 格式写入的。
对于这一类 json 格式的topic,它可能没有事先配置自己的 schema 就写进来了,那么我们在消费的时候,如果想用 SQL,怎么办呢?这里就需要用到 Flink DDL 的框架,所以 BIGO 的消息流平台团队在我们的使用过程中为 Pulsar-Flink-Connector 开发了 Flink SQL DDL 的支持。接下来看一下 Flink SQL DDL 的框架。
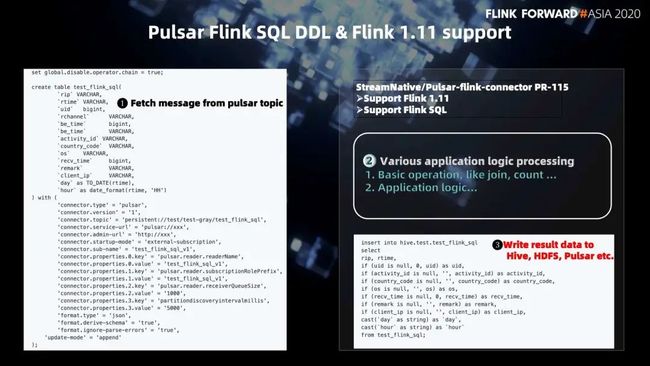
第一步,图左边就是 fetch message from Pulsar topic,首先会定义这个 topic 的里面数据的一个字段信息,也就是 create table test_Flink_SQL,这里面有 rid 等字段。下面的位置里面包含的是怎样去和 Pulsar 的服务端建立连接的,这里会指定 topic 名称,指定 service url,admin url 以及 subscribe name,还有一些一系列相关的配置操作。这样一段 SQL 的代码就能够很好地完成把数据从 Pulsar topic 里面给消费出来。
第二步,就可以进行一系列应用层相关逻辑的处理。比如做 join,count、union 等操作。另外就是一些应用层逻辑的处理,比如说去做统计相关的一些操作。在第二步操作完了之后,我们需要将最终的结果写出到第三方存储里面。第三方存储会包括 Hive 表、HDFS 和 Pulsar 的 topic 等。
对于最终的写入写出就会进入到第三步,我们会调用一个 insert into 的方法,直接把我们处理的结果,写出到相关的 Hive 表里面去,这就是整个 Flink SQL DDL 的一个处理逻辑。我们借助 Flink SQL DDL 能够很好地来实现我们的 AB test 相关的操作。那么在前面的讲解里面,我们可能会使用一个 job 的方式来提交,有了 Flink SQL DDL 的支持,我们就可以很方便地使用一个 SQL 的方式来消费 Pulsar 的 topic,会进行一系列逻辑处理,最终把结果写出去。
现在来看一下基于 SQL 方式的 use case。
■ Case 1
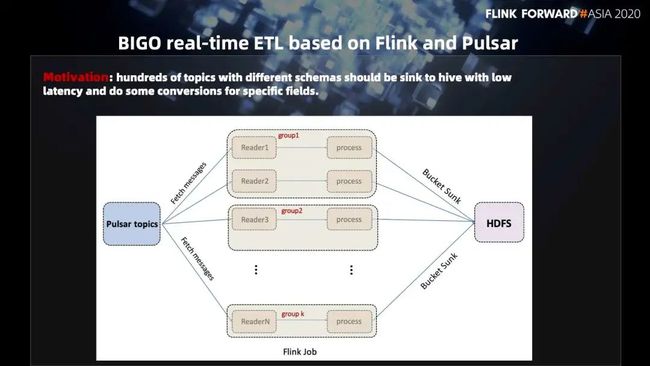
首先来看一下 BIGO reall-time ETL 的实现。这个实时 ETL 的背景,是我们在 Pulsar 里面,会有成百上千个 topic,每一个 topic 会有自己独立的 schema。我们现在的一个需求是想要把每一个 topic 使用自己的 schema 进行一次解析,把最终解析的结果以 bucket 的格式落到 HDFS 的 Hive 表上面去。对于这样一个需求,我们可能会有几种方案:
第一种方案,我们会直接使用 Pulsar 的 HDFS 的 connector,会把 topic 里面的数据会消费出来然后落到 HDFS 上面去,这样做的话,当我们需要对 topic 里面进行一系列的处理的时候,可能就不大好办了。另外一个就是我们有成百上千个 topic,那么也会有成百上千个 schema,也就是说我们可能要维护成百上千个线程,去解相应的 topic 里面的数据,然后把它落出去。这样对于整个任务的维护成本可能会比较高。
第二种方案。我们可以用 Flink SQL 去消费每个topic,每一个 SQL 指令自己的 schema,然后把这个 topic 给消费出来,之后进行一系列的处理,然后写出去。这种方式,实际上也会带来几百个甚至上千个 SQL 任务的维护工作。
第三个方案,我们想到了使用一个 Flink 任务来消费成百上千个 Pulsar 的 topic。然后进行一系列的 ETL 处理,首先进行 schema 的解析,然后进行一系列逻辑处理,最终把它写出到 HDFS 上面去。下面这张图,就是我们采用的第三种方案:使用一个 Flink 的 job 把成百上千个 topic 订阅了。订阅完了之后,获取相应的线程去消费。解析完了之后会经过一系列逻辑处理,最终显示到 HDFS 上面去。
这个 case 可能存在数据分布不均的问题。假设,我们有 500 个 topic,其中 400 个 topic 的流量很小,另外 100 个 topic 的流量很大。那么我们在订阅的时候,假设我起了 100 个 task manager 去消费。那么这可能就会按平均来算,有 5-10 个 topic partition 会落到同一个 task manager 上面去。如果我们不干预的话,由于这个 partition 自身的流量不均衡,可能会导致它从运行任务的进程的流量也是不均衡的,带来了频繁 GC 的问题。
为了解决消费端上面的 task manager 流量不均衡的情况。我们引入了一个 slot group 的概念。我们会事先对 topic partition 的流量进行一个预估,预估完了之后,会通过人工计算的方式把几个低流量的 topic 组合成同一个 group 里面。同一个 group 的 topic 会被放在同一个 slot 里面,然后去进行调度,这样就能够很好的去把 task manager 上面的消费流量不均的问题解决掉了,整个 Flink job 就会运行的很好。
■ Case 2
第二个 case 是一个 AB test 的应用场景,做这个 AB test 场景的一个初衷是什么呢?在我们实时的数仓里面,需要去产出小时级别的中间表,以及天级的中间表,给推荐算法的工程师以及数据分析师来使用。对于小时级别的中间表以及天级的中间表的产生,需要通过实时的去计算底层的各种类型的打点,比如用户观看的打点、某个视频的下发打点,还有用户其他行为的打点等等,会按照某一个维度进行聚合。聚合了之后会进行相关的一些统计,最终会形成一张宽带供推荐算法工程师以及数据分析师来使用。
如果我们不提供这样一个宽表的话,那么对于上层的业务方而言,可能要不断的去访问底层的表,对底层表进行各种相应的操作。这样不但会浪费数据分析师以及推荐算法工程师的时间,也会造成整个集群计算资源的浪费。那么在 BIGO 这边,之前的解决方案是使用 Hive。使用 Map Reduce 的方式,来把每张底层的表进行一次聚合操作。聚合完了之后会提供一个小时级别中间表以及天级的中间表给上层业务使用,这样做的弊端是:Hive Map Reduce 的时效性是没法保证的。所以我们就在想能否使用 Flink 流式计算的方式来提高实时数仓的数据产出效率。
接下来就是我们这边的一个解决方案:首先我们会用 Flink SQL 去消费 Pulsar 的 topic。从下图的左边来看,我们有 Topic A、Topic B 和 Topic K。每个 topic 有自己的 DDL。我们首先会使用 Flink SQL 加上每一个 topic 的 scanner,也就是 DDL 会把 topic 的数据从 Pulsar 里面加载出来,然后把它做成每个 topic 的一个视图。
这个地方我们就会有 Table A、Table B 和 Table K 的一个表。假设有 K 张表,那么我们需要对 K 张表进行一次聚合操作。假设是按照 uid 进行一次聚合,那么这个聚合有两种方式:
第一种方式是做 join。对于 Flink 而言,它的流式 join 可能耗时会比较长,整个计算资源的消耗也是非常大的。所以我们这边做了一个比较巧妙的方案就是使用 union 代替 join。我们会把 Table A、Table B 和 Table K 通过 union 的方式会生成一个 View X。然后把 View X 直接写出以小时为粒度,到 ClickHouse 供用户查询。在 union 的过程当中,我们还会做一些相关的聚合的操作。来把相关的指标给聚合起来供用户使用。这个就是小时级别的中间表。

对于天级的中间表而言,我们所遇到的挑战是:它并不是单单的只依赖了 Table A、Table B 和 Table K,可能还依赖了离线的表。假设有 Table a1、Table a2 和 Table a3 三张表。我们怎么样把实时的表和离线的表做一个关联?这里我们也是使用的一个比较巧妙的方式。
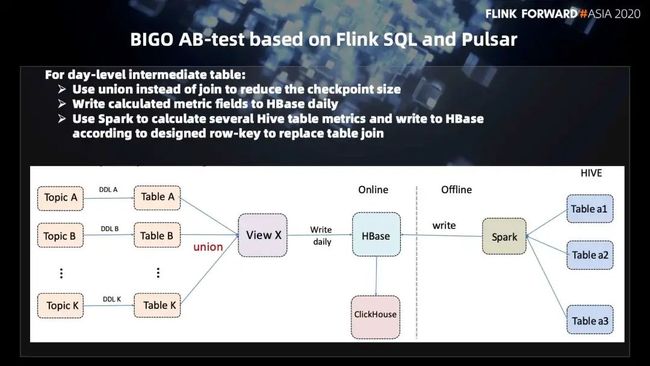
首先。在左边 Table A、Table B 和 Table K 会使用 Flink SQL 把数据从 Pulsar 消费出来,然后做成一个独立的 table。然后同样也是以 union 的方式把实时的流表给 union 起来,做一些统计相关的处理生成一个视图,一个View X。这个 View X 会根据我们精心设计过的一个 row-key,把它以天为维度写出到 HBase 里面去。
另外,对于离线而言。因为我们 Table A、Table B 和 Table K 只是代表了咱们实时的一些数据,对于离线的数据,也是需要 join 进来的,那么就会使用一个 Spark 来把 Table a1、Table a2 和 Table a3 相关的数据给 join 起来,然后也以相同的规则生成一个 row-key 写在 HBase 里面去。
对于 HBase 而言,它实际上提供的就是一个 join 操作,写到 HBase 就很好的避免了我们将 View X 以及 Spark 所生成的这样一张表做 join 了。因为如果是有相同的 key,那么假设 HBase 这样一张宽表有 100 列,View X 占了前 80 列,那么后面的 Spark 所算出来的这个表会自动地填充到那个后 20 列里面去,那么最终会生成同一个 row-key 的一个 100 维的一张宽表。那么我们接下来会把 HBase 里面这样一张宽表读出来,然后写到 ClickHouse 供上层用户去查询。这样就能够很好的去避免表之间的 join 操作,极大地提高 join 的效率。
五、未来工作
首先,我们会接着在 Pulsar-Flink-Connector 上面继续的去开发新的 feature 并且持续的去进行一系列的 bug 修复;
第二点,我们会更多的将 Flink 任务持续地从 Kakfa 迁移到 Apache Pulsar 上面去;
第三点,在我们整个的消息流平台里,之前使用的是 Kakfa,可能有成百上千个 Flink 的任务或者是其他的任务,使用 Kafka 的 API 来消费 Kafka 的 topic。如果不提供一个简单的方式让用户来消费 Pulsar 的 topic 的话,这个迁移工作是非常难进行的。所以我们会借助于 KOP,也就是 Kakfa on Pulsar,方便上层应用的迁移,有了这样一层 KOP 的一个 proxy,对于上面应用程序是不需要改任何的代码就能够自动的从 Kafka 切到 Pulsar 上面的;
第四点,我们打算实现一个批流统一的数据的消费,从 Pulsar topic 里面以批或者是流的方式来消费 topic 里的数据;
第五点,我们会持续加强 Pulsar 以及 bookkeeper 的稳定性以及吞吐的调优;
第六点,我们会持续的去优化 Bookkeeper 的 IO 协议栈。
识别下方二维码,回复“资料合集”,即可获得下载地址。感觉干货多,记得设为星标哦

历史精彩文章
1、原创|实时数仓实战项目-第一节
2、原创|实时数仓实战项目-第二节(数仓分层)
3、原创|实时数仓实战项目-第三节(数仓治理)
4、附PPT|2021年总结实时数仓最新架构图
5、原创|渣渣二本,喝下这杯逆袭鸡汤,看完年薪不到70万,算我输!!!
6、实时数仓实战项目-第四节(命名规范和分层设计)
7、Flink 在伴鱼的实践:如何保障数据的准确性
8、干货|ClickHouse源码阅读计划--理论&工具的准备