day5 6 7-牛客67道剑指offer-JZ43、45、49、50、51、52、53、55、79、数组中只出现一次的数字
文章目录
- 1. JZ43 整数中1出现的次数(从1到n整数中1出现的次数)
- 2. JZ45 把数组排成最小的数
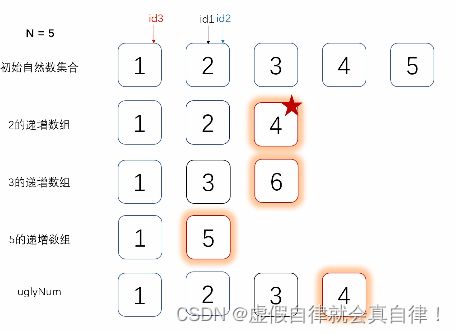
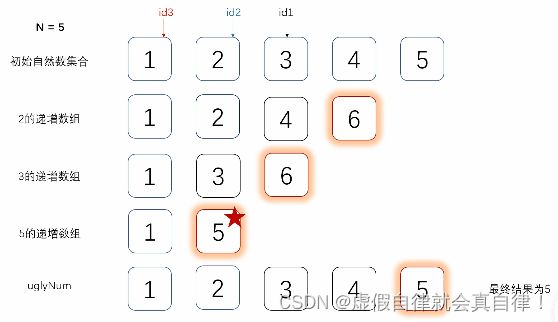
- 3. JZ49 丑数
-
- 最小堆
- 三指针法 动态规划
- 4. JZ50 第一个只出现一次的字符
- 5. JZ51 数组中的逆序对
- 6. JZ52 两个链表的第一个公共结点
-
- 迭代
- 递归
- 7. JZ53 数字在升序数组中出现的次数
- 8. JZ55 二叉树的深度
-
- 递归
- 迭代
- 9. JZ79 判断是不是平衡二叉树
-
- 自底向上 后序遍历
- 自上向底 前序遍历
- 10. 数组中只出现一次的数字
-
- 哈希表
- 位运算
- 补充内容 - 并归排序
1. JZ43 整数中1出现的次数(从1到n整数中1出现的次数)
 题目描述:输入一个整数 n ,求 1~n 这 n 个整数的十进制表示中 1 出现的次数。例如, 1~13 中包含 1 的数字有 1 、 10 、 11 、 12 、 13 因此共出现 6 次,注意:11 这种情况算两次。
题目描述:输入一个整数 n ,求 1~n 这 n 个整数的十进制表示中 1 出现的次数。例如, 1~13 中包含 1 的数字有 1 、 10 、 11 、 12 、 13 因此共出现 6 次,注意:11 这种情况算两次。
力扣K神的题解,在这里




- 总结起来就是,某位中 1 出现的次数,根据当前位 cur 的值,分为以下三种情况:
- 当 cur=0 时: 此位 1 的出现次数只由高位 high 决定,计算公式为:high×digit
- 当 cur=1 时: 此位 1 的出现次数由高位 high 和低位 low 决定,计算公式为:high×digit+low+1
- 当 cur=2~9 时: 此位 1 的出现次数只由高位 high 决定,计算公式为:(high+1)×digit
- 举例,n = 32104,从个位开始计算:
- 初始化 high=3210,cur=4,low=0,digit=1,result=0
- 每一轮计算如下:
| 位数 | high | cur | low | digit | 1的次数 | result |
|---|---|---|---|---|---|---|
| 个位 | 3210 | 4 | 0 | 1 | (3210+1)× 1 = 3211 | 3211 |
| 十位 | 321 | 0 | 4 | 10 | 321×10 = 3210 | 6421 |
| 百位 | 32 | 1 | 04 | 100 | 32×100+4+1 = 3205 | 9626 |
| 千位 | 3 | 2 | 104 | 1000 | (3+1)× 1000 = 4000 | 13626 |
| 万位 | 0 | 3 | 2101 | 10000 | (0+1)× 10000 = 10000 | 23626 |
- 每一位数计算完1的出现次数后,都要更新位数:
while (high != 0 || cur != 0) { // 当 high 和 cur 同时为 0 时,说明已经越过最高位,因此跳出
low += cur * digit; // 将 cur 加入 low ,组成下轮 low
cur = high % 10; // 下轮 cur 是本轮 high 的最低位
high /= 10; // 将本轮 high 最低位删除,得到下轮 high
digit *= 10; // 位因子每轮 × 10
}
class Solution {
public:
int NumberOf1Between1AndN_Solution(int n) {
int result = 0;
int digit = 1, low = 0, cur = n % 10, high = n / 10;
while (high != 0 || cur != 0) //high=0 说明位数遍历结束
{
if(cur == 0) result += high * digit;
else if (cur == 1) result += high * digit + low + 1;
else result += (high + 1) * digit;
//位数更新
low += cur * digit;
cur = high % 10; // 下一位位数 就是 当前高位 对10取余
high = high / 10;
digit *= 10; // 前进一位
}
return result;
}
};
- 另一种写法
int NumberOf1Between1AndN_Solution(int n)
{
if(n <= 0) return 0;
if(n< 10 ) return 1;
if(n == 10) return 2;
int pow = 1, high = n,last = 0;
while(high >= 10){
high = high/10;
pow *=10;
}
last = n - high*pow;// 除去最高位的数字,还剩下多少 0-999 1000- 1999 2000-2999 3000 3345
int cut = high == 1 ? last+1: pow;
return cut + high*NumberOf1Between1AndN_Solution(pow-1) + NumberOf1Between1AndN_Solution(last);
}
2. JZ45 把数组排成最小的数
-
思路是要求排成最小的数,那么数组中数字越大的越靠前,拼接的数字就越小。
-
按照一定规则把数组排序,保证数组中的数字是降序。写一个布尔类型的排序规则函数,作为sort的比较函数。排序后从头遍历,逐一拼接数字。
-
排序规则是两个整数拼接,比较大小,返回拼接后较小的结果。具体地,把数字a、b转成字符串ab、ba,返回ab < ba 的结果。如果ab < ba为真,说明a在前b在后的排序正确,即降序,否则为升序。例如3、11,因为113 < 311,所以返回113 < 311,排序后为11、3。
-
写法1
#include - 写法2
#include - 有两点要注意的:
- sort函数要定义为静态或者全局函数。sort中的比较函数cmpStr要声明为静态成员函数或全局函数,不能作为普通成员函数,否则会报错。 因为:非静态成员函数是依赖于具体对象的,而std::sort这类函数是全局的,因此无法再sort中调用非静态成员函数,所以cmpStr函数前面要加关键字static。
- 静态成员函数或者全局函数是不依赖于具体对象的,可以独立访问,无须创建任何对象实例就可以访问,同时静态成员函数不可以调用类的非静态成员。

/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
#include 3. JZ49 丑数

最小堆

#include 三指针法 动态规划



#include 4. JZ50 第一个只出现一次的字符
题目: 在一个长为 字符串中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1,需要区分大小写,从0开始计数。
class Solution {
public:
int FirstNotRepeatingChar(string str) {
//
if(str.size() == 0) return -1;
unordered_map<int, int> hashmap(str.size());
for(int i=0; i<str.size(); i++)
{
hashmap[str[i] - 'a']++;
}
for(int i=0; i<str.size(); i++)
{
if(hashmap[str[i] - 'a'] == 1) return i;
}
return -1;
}
};
5. JZ51 数组中的逆序对

构成逆序对的个数关键在于升序排列后该序列的长度,例如1、2、3,当遍历1时,长度=0,不构成逆序对;遍历2时,长度=1,逆序对数=2-1;遍历3时,长度=2,逆序对=3-1。所有逆序对数累加。
排序时使用并归排序,将数组分成两部分,按照升序排序。
- 并归排序 升序
class Solution {
public:
int InversePairs(vector<int>& nums) {
if( nums.size() <= 1) return 0;
vector<int> copy(nums);// 辅助数组,每次递归后有序
return InversePairscore(nums, copy, 0, nums.size()-1);
//for (int a : data) {
// cout << a << " ";
//}
//cout << endl;
//for (int a : copy) {
// cout << a << " ";
//}
//cout << endl;
}
int InversePairscore(vector<int>& nums, vector<int>& copyvector, int start, int end)
{
if (start >= end) return 0;
int mid = start + (end - start) / 2;
int low1 = start, high1 = mid, low2 = mid + 1, high2 = end;
int left = InversePairscore(copyvector, nums, low1, high1);//注意这里 copyvector和nums交换位置 相当于赋值 减少了数据交换的这一步
int right = InversePairscore(copyvector, nums, low2, high2);
long res = 0;
int copyIndex = low1;
// 归并排序:相当于两个有序数组合成一个有序表
//下面就开始两两进行比较,若前面的数大于后面的数,就构成逆序对
while (low1 <= high1 && low2 <= high2)
{
if(nums[low1] <= nums[low2])
copyvector[copyIndex++] = nums[low1++];
else
{
copyvector[copyIndex++] = nums[low2++];//说明 [low1,high1]此时都是大于 nums[low2]的
res += high1 - low1 + 1;//这里千万注意要 +1 ,因为high1 - low1 就少一个 比如 3-0 = 4,但其实是4个数
res %= 1000000007;
}
}
while(low1 <= high1)
copyvector[copyIndex++] = nums[low1++];
while(low2 <= high2)
copyvector[copyIndex++] = nums[low2++];
return (left + right + res) % 1000000007;
}
};
2. 题目难点
给定链表的头节点 head ,复制普通链表只需遍历链表,每轮建立新节点 + 构建前驱节点 pre 和当前节点 node 的引用指向即可。
本题链表的节点新增了 random 指针,指向链表中的 任意节点 或者 null 。这个 random 指针意味着在复制过程中,除了构建前驱节点和当前节点的引用指向 pre.next ,还要构建前驱节点和其随机节点的引用指向 pre.random 。
本题难点: 在复制链表的过程中构建新链表各节点的 random 引用指向。

3. 思路
class Solution {
public:
Node* copyRandomList(Node* head) {
Node* cur = head;
Node* dum = new Node(0), *pre = dum;
while(cur != nullptr) {
Node* node = new Node(cur->val); // 复制节点 cur
pre->next = node; // 新链表的 前驱节点 -> 当前节点
// pre->random = "???"; // 新链表的 「 前驱节点 -> 当前节点 」 无法确定
cur = cur->next; // 遍历下一节点
pre = node; // 保存当前新节点
}
return dum->next;
}
};
4. 哈希表 迭代写法

/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead) {
//哈希表
if(pHead == nullptr) return nullptr;
unordered_map<RandomListNode*, RandomListNode*> hashmap;//原结点 复制的新结点
RandomListNode* cur = pHead;
//1. 复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射 建立值映射
for(RandomListNode* p = cur; p != nullptr; p = p->next)
{
hashmap[p] = new RandomListNode(p->label);
}
//2. 构建新链表的 next 和 random 指向 建立指向映射
while(cur!=nullptr)
{
//新结点hashmap[cur]的 指向 hashmap[cur]->next 就是 原结点cur的指向 cur->next
hashmap[cur]->next = hashmap[cur->next];
hashmap[cur]->random = hashmap[cur->random];
cur = cur->next;
}
return hashmap[pHead];
}
};
5. 哈希表 递归写法
/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead) {
//2. 哈希表 递归
if(pHead == nullptr) return nullptr;
RandomListNode* newhead = new RandomListNode(pHead->label);//复制头结点
hashmap[newhead] = pHead;//“原节点 -> 新节点” 的 Map 映射 值映射
newhead->next = Clone(pHead->next);//next指向
if(pHead->random != nullptr) newhead->random = Clone(pHead->random);//如果有random指向
return hashmap[newhead];
}
private:
unordered_map<RandomListNode*, RandomListNode*> hashmap;//原结点 复制的新结点
};
6. 拼接 + 拆分 原地解法

/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead) {
if(pHead == nullptr) return nullptr;
//3. 拼接 + 拆分 原地解法
RandomListNode* cur = pHead;
//复制结点及next指向
while(cur != nullptr)
{
RandomListNode* temp = new RandomListNode(cur->label);//复制结点 新结点
temp->next = cur->next;// 新结点 -> 原下一个结点
cur->next = temp;// 原结点 -> 新结点
cur = temp->next;//cur = cur->next->next;//cur更新为 原结点的下一个结点
}
//复制结点的random指向
cur = pHead;
while (cur != nullptr)
{
//新结点cur->next 的random指向 = 原结点cur 的random指向
if(cur->random != nullptr) cur->next->random = cur->random->next;
cur = cur->next->next;//更新cur
}
//分离链表
cur = pHead->next;//新结点表头
RandomListNode* old = pHead, *result = pHead->next;
while(cur->next != nullptr)
{
old->next = old->next->next;//分离
cur->next = cur->next->next;
old = old->next;//更新
cur = cur->next;
}
old->next = nullptr;// 单独处理原链表尾节点
return result;
}
};
6. JZ52 两个链表的第一个公共结点
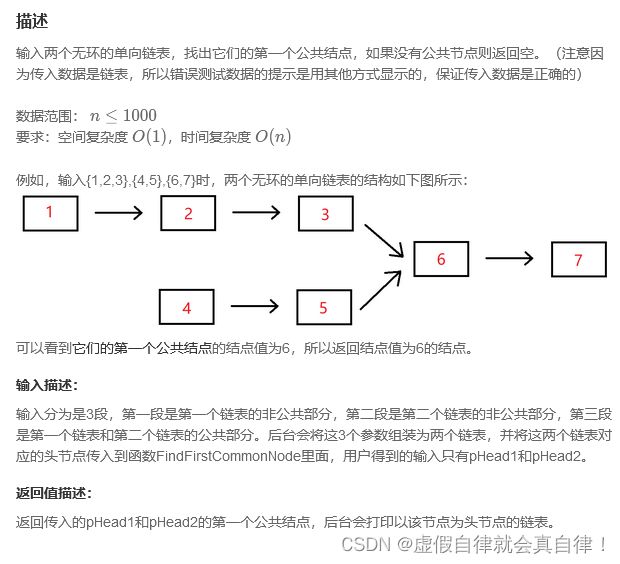
迭代
统计长度,长的链表先走 两个链表长度差 步,然后再一起走,同时比较结点是否相等
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
#include 递归
长度相同的:1. 有公共结点的,第一次就遍历到;2. 没有公共结点的,走到尾部NULL相遇,返回NULL;
长度不同的:1. 有公共结点的,第一遍差值就出来了,第二遍就会一起到公共结点;2. 没有公共结点的,第二次遍历一起到结尾NULL。
相当于省去了长度统计这一步,把链表看成一个环。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
#include 7. JZ53 数字在升序数组中出现的次数

一个是利用count函数,直接返回个数return count(nums.begin(), nums.end(), k);
另外一个是用二分法 return count(nums.begin(), nums.end(), k);z
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param nums int整型vector
* @param k int整型
* @return int整型
*/
int GetNumberOfK(vector<int>& nums, int k) {
return count(nums.begin(), nums.end(), k);
//二分法
int start = 0, mid = 0, end = nums.size()-1;//左闭右闭
while(start <= end)
{
mid = start + (end - start) / 2;
if(nums[mid] < k) start = mid+1;
else if (nums[mid] > k) end = mid;
else//找到其中一个k的位置
{
int index = mid-1;
int count=0;
count++;//记录当前k
//往回找到其他k
while(index >= 0 && nums[index] == k)
{
count++;
index--;
}
index = mid+1;
while(index <= end && nums[index] == k)
{
count++;
index++;
}
return count;
}
return 0;
}
}
};
8. JZ55 二叉树的深度

递归
看左右子树的长度;单层递归中,如果有左子树,左子树长度+1,如果有右子树,右子树长度+1;最后看哪个累加值最大。每一层+1是因为根节点的深度视为 1。有两种写法,如下:
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
int TreeDepth(TreeNode* pRoot) {
if(pRoot == nullptr) return 0;
//return dfs1(pRoot);//递归写法1
return dfs2(pRoot);//递归写法2
}
int dfs1(TreeNode* root)
{
if(root == nullptr) return 0;
int leftdepth = dfs1(root->left) + 1;
int rightdepth = dfs1(root->right) + 1;
return max(leftdepth, rightdepth);
}
int dfs2(TreeNode* root)
{
if(root == nullptr) return 0;
int left = dfs2(root->left);
int right = dfs2(root->right);
return max(left, right) + 1;
}
};
迭代
用一个元组对来维护当前遍历的结点及当前深度,队列实现,中序遍历
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
#include 9. JZ79 判断是不是平衡二叉树
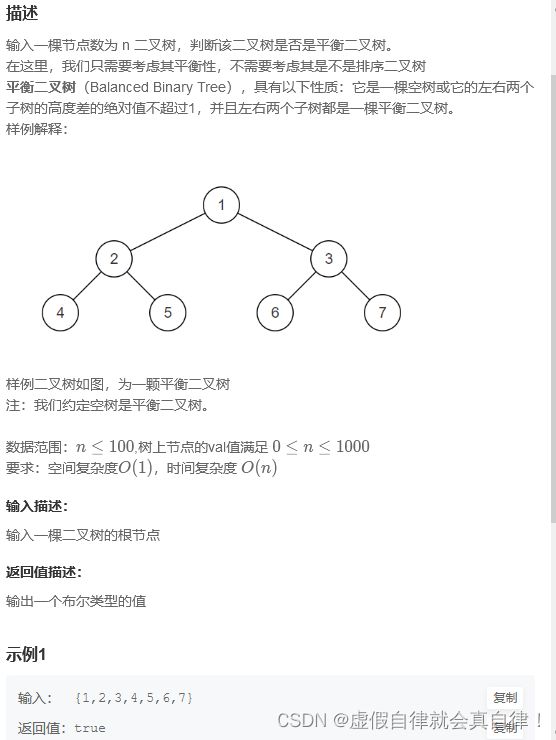
自底向上 后序遍历
- 判断一个数是否为平衡二叉树。平衡二叉树是左子树的高度与右子树的高度差的绝对值小于等于1,同样左子树是平衡二叉树,右子树为平衡二叉树。
- 统计深度,判断左右子树深度差的绝对值不超过1;后序遍历:左子树、右子树、根节点,先递归到叶子节点,然后在回溯的过程中来判断是否满足条件。
- 统计深度时,可以直接判断,如果不满足平衡二叉树的定义,则返回-1,并且如果左子树不满足条件了,直接返回-1,右子树也是如此,相当于剪枝,加速结束递归。
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
bool IsBalanced_Solution(TreeNode* pRoot) {
if(pRoot == nullptr) return true;
//自底向上
return getDepth1(pRoot) != -1;
}
int getDepth1(TreeNode * node){
if(node == nullptr) return 0;
int left = getDepth1(node->left);
if(left == -1) return -1;
int right = getDepth1(node->right);
if(right == -1) return -1;
if(abs(left - right) > 1) return -1;
else
return 1 + max(left,right);
}
};
自上向底 前序遍历
根据平衡二叉树定义,如果能够求出以每个结点为根的树的高度,然后再根据左右子树高度差绝对值小于等于1,就可以判断以每个结点为根的树是否满足定义。
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
return bool布尔型
bool IsBalanced_Solution(TreeNode* pRoot) {
if(pRoot == nullptr) return true;
//自上向底
int leftdepth = getDepth(pRoot->left), rightdepth = getDepth(pRoot->right);//根借点
if(abs(leftdepth - rightdepth) > 1) return false;
return IsBalanced_Solution(pRoot->left) && IsBalanced_Solution(pRoot->right); //继续判断左右子树
}
int getDepth(TreeNode* root)
{
if(root == nullptr) return 0;
int leftdepth = getDepth(root->left);
int rightdepth = getDepth(root->right);
return max(leftdepth, rightdepth) + 1;
}
};
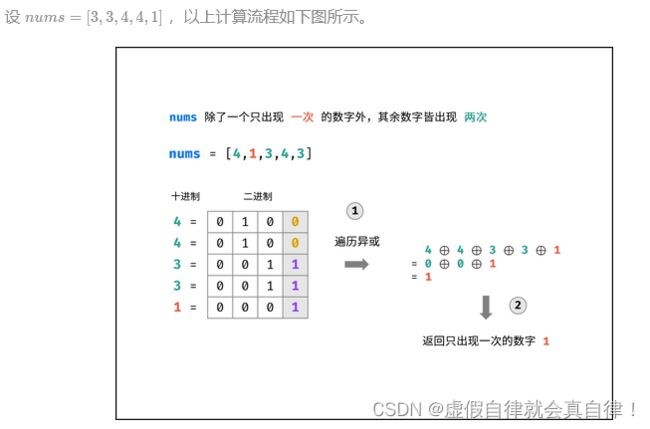
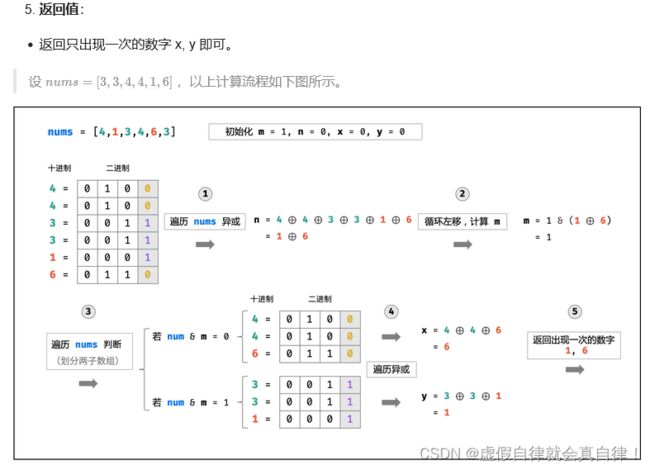
10. 数组中只出现一次的数字
描述:一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
哈希表
#include 位运算
又又又搬运力扣K神的题解了



- 异或操作图解
 力扣eddieVim的题解回答了我的问题
力扣eddieVim的题解回答了我的问题
-
为什么要异或:两个数异或的结果 就是 两个数数位不同结果的直观表现。
-
计算m的意义
- 数组依次遍历且疑惑操作后,找到两个不同的数了。此时难点在于如何对两个不同数字的分组。此时可以通过奇偶进行分组,那么就要想到 & 1 操作,通过判断最后一位二进制是否为 1 来辨别数字的奇偶性。
- 也就是说,通过 & 运算来判断数字的奇偶性,并据此将一位数字分成两组。因此只需要找出不同的数字m,即可完成分组( & m)操作。
- 两个数异或的结果就是两个数数位不同结果的直观表现,所以可以通过异或后的结果去找 m!所有的可行 m 个数,都与异或后1的位数有关。
- mask示例
num1: 101110 110 1111
num2: 111110 001 1001
num1^num2: 010000 111 0110
可行的mask: 010000 001 0010
010 0100
100
#include 补充内容 - 并归排序
sunny-ll的并归排序简明扼要地说明了并归排序了
- 问题分析
归并排序是比较稳定的排序方法。它的基本思想是把待排序的元素分解成两个规模大致相等的子序列。如果不易分解,将得到的子序列继续分解,直到子序列中包含的元素个数为1。因为单个元素的序列本身就是有序的,此时便可以进行合并,从而得到一个完整的有序序列。 - 算法设计
(1)分解: 将待排序的元素分成大小大致一样的两个子序列。
(2)治理: 对两个子序列进行个并排序。
(3)合并: 将排好序的有序子序列进行合并,得到最终的有序序列。
力扣第315、327、493题也是关于并归排序的,回头写。