六天速通javaweb(后续深入学在这丰富)
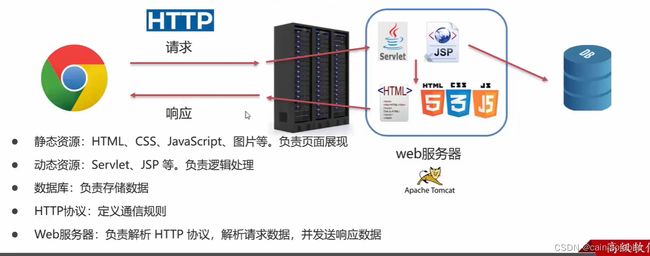
javaweb整体结构

——————————————————————————————
1.HTTP
定义:超文本传输协议,规定了浏览器和服务器之间传输的规则
特点:
- 基于TCP协议:面向连接,安全。
- 基于请求-响应模型:一次请求对应一次响应
- HTTP协议是无状态的协议:对于事务处理没有记忆能力,每次请求-响应 都是独立的:速度快但是多次请求不能共享数据,可以通过cookie,session来解决(会话技术)。
(1)请求数据格式

- 请求行:请求数据的第一行。GET表示请求方式(get和post等,在html那里讲过),/表示请求资源路径,HTTP/1.1表示协议版本。三个中间以空格分隔
- 请求头:第二行开始。格式为key: value形式。

- 请求体:POST请求独有的。在post请求的最后一部分,存放请求参数
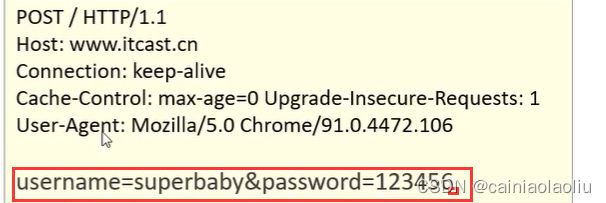
对于get和post的区别,就是:get请求参数放在请求行里,没有请求体,并且大小有限制
post的请求放在请求体中,大小没有限制。
(1)响应数据格式

7. 响应行:HTTP的版本号+响应状态码(200表示响应成功),OK表示状态码描述。

更多详细响应状态码见:https://cloud.tencent.com/developer/chapter/13553
8. 响应头:从第二行开始,格式也是key:value的形式。(后边加一个空行与响应体隔开)

- 响应体
传输流程是:我们写服务端软件,申请socket,然后输入流输出流。但是这个比较通用,就封装在了tomcat里
2.Tomcat
tomcat是一个web服务器。准确的说也是一个软件,这个软件对HTTP协议进行封装,使程序员不必直接对协议进行操作,让web开发更加便捷,主要功能是“提供网上信息浏览服务”。
- 作用:封装HTTP协议操作,简化开发。将web项目部署 到web服务器,对外提供网上浏览服务。
- 支持servlet/JSP少量javaEE规范,也称web容器,serclet容器
一些文件的常识:

下载:直接在官网,免费的,下载了以后解压就可以了。
打开:bin目录里的startup.bat,双击就打开了(sh结尾的是linux的)
关闭:ctrl + c 或者点shutfoen.bat。不要直接点×
可以把默认端口号改成80,因为http协议的默认端口号为80,这样我们就不用写端口号也能访问到。
打开时,如果说端口冲突,那就找到那个程序把他关了就行了。
如果闪退,就是环境变量没有配置好java。tomcat要用java跑,所以他需要能找到java在哪。
访问哪个项目:就是在localhost:80/项目名字
我们一般配置直接放到webapps文件夹下就好,但是我们挪文件夹可能比较慢,这时可以把文件打包成war包(通过idea插件就可以),把war包放过去,tomcat会自动解压。
项目结构
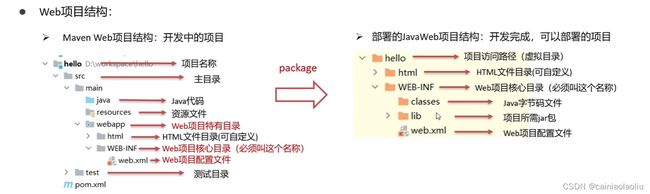
创建方式:
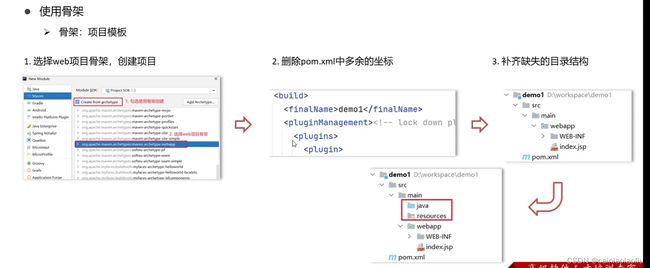

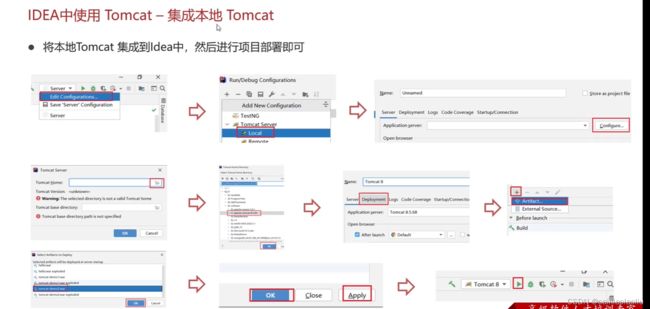
怎么使用idea更快的部署到tomcat中
1.把tomcat集成到idea
2.使用idea中的tomcat插件
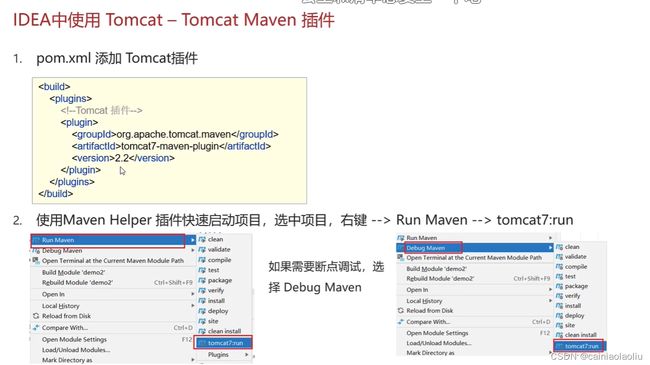
tomcat_01
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
这里可以设置端口

3.Servlet
是一门动态web资源开发技术
是javaEE的规范之一。提到规范就应该想到接口。将来我们需要定义servlet类实现servlet接口,并由web服务器运行servlet
(1)快速入门
- 创建web’项目,导入servlet依赖
javax.servlet
javax.servlet-api
3.1.0
provided
-
定义一个类,实现Servlet接口,并重写接口中的所有方法,并在service方法中输入一句话,会被输出到控制台,表明servlet被执行了。
-
配置:在类上使用@WebServlet注解,配置该Servlet的访问路径
@WebServlet("/demo1")
public class SetveltDemo implements Servlet{ }
- 访问:启动Tomcat,浏览器输入URL访问该Servlet
http://localhost:8080/web-demo/demo1
(2)Servlet的执行流程和生命周期
为什么输入域名就能自己跑起来?它的对象是谁创建的?他的方法是谁调用的?
是tomcat进行创建和调用的。
生命周期:一个对象从创建到销毁的整个过程
servelt运行在tomcat容器中(web服务器),其生命周期由容器来管理,分为四个阶段
- 加载和实例化阶段:默认情况下,当servlet第一次被访问的时候,由容器来创建servlet对象(可以改边注解后边括号里属性,loadOnStartup的值,等于负整数的时候,就是第一次访问才创建。等于0以上的时候,就是服务器启动的时候创建,数字越小优先级越高)
- 初始化:实例化后,init方法会自动被容器调用,完成一些如加载配置文件、创建连接等初始化工作,该方法只调用一次。
- 请求处理:每次请求servlet时,容器都会调用servlet都会调用service方法对请求进行处理
- 服务终止:当需要释放内存或者容器关闭时,容器就会调用servlet实例的destroy方法完成资源的释放(init方法里面申请的资源)。在destory方法调用后,容器就会释放这个servlet实例,该实例随后会被java垃圾收集器所回收。(这里注意,强制关闭时不会执行的,也就是不会调用这个方法来释放资源了,点tomcaat的叉叉时强制关闭,点idea里的红方块也是强制关闭)——正确的关闭:打开的时候,在idea下方的Terminal也就是控制台,输入mvn tomcat7:run方法开启服务,输入ctrl+c就可以安全退出。
(3)servlet方法介绍
除了上面那三个方法,还有两个,但是不常用
geetServletInfo:返回版权等信息的,我们一般就直接return ”“;空字符串就行
getServletConfig:返回一个ServletConfig对象。
(4)servlet体系结构(HttpServlet)

我们将来开发B/S架构的web项目,都是针对HTTP协议,所以我们自定义Servlet,直接继承HttpServlet类,然后重写他的doGet和doPost方法即可(分别对应get和post请求方式的处理逻辑)。
为什么要区分get和post的方法?因为不同的请求方式,他们呢分别写在不同的地方。一个在请求行,一个在请求体。如果我们就普通实现接口,那么也需要在service里获取请求方式,再做操作。
HttpServlet分开get和post的实现原理:一个抽象类实现了servlet接口,然后他继承这个抽象类,重写了抽象类的所有方法(其实就相当于实现了接口)。然后添加了两个方法doGet和doPost,他的service方法里有一个判断语句,就是当get请求的时候,就会执行doGet方法中的代码,post进来的时候,就会执行doPost方法的代码。————重点来了:我们访问的直接就是我们自己写的继承了HttpServle的类,而我们的类里面只重写了两个do的方法,没有service,所以他会去这个类的父类去执行,也就是HttpServlet,这个方法会判断get还是post。然后get的话去找doGet方法,由于我们doGget被我们重写了,所以他还会回到子类里来执行doGet,而不会执行HttpServlet里的doGet。post亦然。。
——————————————————————————————————————————
下面是做一个html提交信息到servlet,然后感应get还是post的实验
实验:
1.先把Servlet的继承写好,如果是get方法就打印get,如果是post发送过来的就打印post
@WebServlet("/demo1")
public class ServletDome1 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("get..");
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println("post..");
}
}
然后开启tomcat(接口打开)
写html,把他的发送地址写sevlet的地址
然后打开html,输入信息点发送,servlet就能接收到了。
————————————————————————————————————————
(5)urlPattern配置:
- 一个Servlet,可以配置多个urlPattern
@WebServlet(urlPatterns = {“/demo1”,/demo2}) - urlPattern配置规则
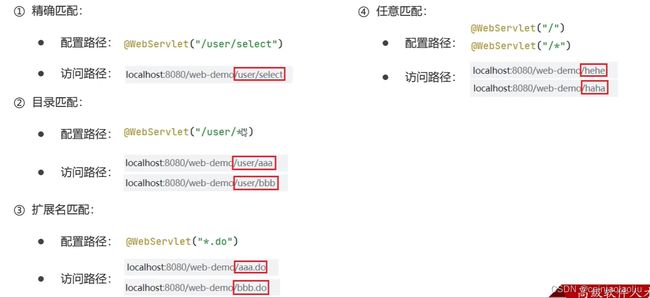
如果输入的同时满足多个项目的配置路径,那么会有一个优先级
精确>目录>拓展名>/*>/
这里有两个点:第一拓展名不可以前面加斜杠,不然会报错
第二,不要使用/,不然就会覆盖掉DefaultServlet,导致项目中的静态资源无法访问。
(6)xml方式
也可以写Servlet,但是过时了,就是把注解的内容卸载xml里。
——————————————————————————————————————————
(7)小结
ok到这里来捋一下网络编程、tomcat、servlet的串联思路。
一般的网络通信需要服务端、客户端一边一个socket,然后两边通过socket把网络变成了流对象,客户端(浏览器)向这个流对象输出流或者读入,然后服务端通过这个socket用输入流读入或者输出。
socket由于用起来比较复杂,每次需要对一个端口new一个seversocket对象,再通过这个对象获取socket,再建流,再通过流传递。
我们就把他用tomcat封装起来,tomcat可以自动完成这一系列操作,自动的new seversocket,默认端口是8080,然后自动的获取这个端口的socket。并且把流这个过程也封装了。
把项目部署到toncat,其实就是部署服务端的过程,我们的浏览器相当于客户端。我们打开了tomcat相当于打开了服务端的socket接口,别人输入域名,其实就相当于一个客户端连接了你的服务端接口,所以我们要输入协议名(以什么连接方式)+ip(哪个主机)+端口(哪个服务)+项目名(socket中的哪个项目)。然后连接上以后,就会返回一个页面,根据你选择连接的项目不同,当然会返回不同的内容,你连接的html自然就会返回一个页面。这样tomcat的作用就是这样,简化建立连接和输入输出的繁琐,直接建立,并且根据项目名字返回你要的东西。
什么是Servlet?他的作用并不是简化,而是承担动态作用的。html、css、js都是静态资源,每个人看到的都是一样的,但是没法处理一系列操作以及沟通数据库(暂时想法,对错有待深入)。servlet正是进行这一系列动态操作的,我们都知道,像前面html的表单,会提交吧,提交到我们服务器这里来,就是提交给servlet进行处理的。
他不是一种特殊的东西,他只是一个java语言的代码而已,就是一个接口,我们需要实现接口的方法即可。(这里常用接口抽象类的实现类的继承,详细的看上面)
然后,这里我们跟前面的html串起来的话,html的表单会有一个属性action,就是提交给谁,我们就可以写sevlet的url,这样就会提交过去,然后他会处理。
4.servlet(request,response)
(1)Request
请求的数据放在request对象里,我们通过调用这个对象的方法来获取这些数据
①Request继承体系
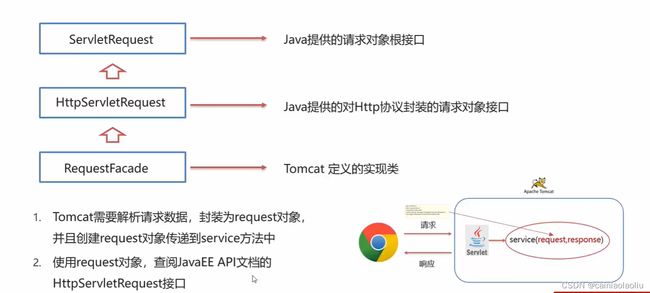
②Request获取请求数据
请求数据分为三部分:请求行、请求头、请求体
-
请求行:这部分就是一个包含三部分的字符串:请求方式+URL+?+参数+协议版本
String getMethod():获取请求方式
String getContextPath:获得虚拟目录(项目访问路径)/request_demo
StringBuffer getRequestURL:获取其URL,也就是ip+端口+路径(统一资源定位符)http……/request_demo/req1
String getRequestURI(统一资源标识符)/request_demo/req1(多了个具体名字)
String getQuerString:获取get请求的请求参数:“username=zhangsan&id=2” -
请求头;头的名称:头的值
String getHeader(String name)根据请求头名称获取值 -
请求体:键值对,等号连接的参数信息(表单参数)
getInputStream获取字节输入流
getReader获取字符输入流
这里由于post和get的参数放在不同地方,所以我们需要分别写两套重复的方法,比较麻烦。所以我们有一个通用的方法,然后再doPost里调用doGet,在使用这个通用的方法。
这个通用的方法就是,无论是在请求行还是请求体的参数,都i会给你放到map< String,String[,]>里,根据键值来取值。当然也可以直接取,一些方法如下。(键值相同的两个会放到数组里,比如复选框,就是多个值)
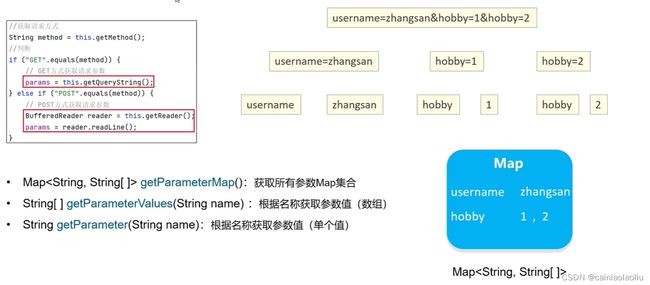
我们可以修改servlet创建模板,让她一开始就全都写好,hdoPost转到get也能写好。。
中文乱码问题
post的乱码:post的获取原理是流获取,所以我们把流的编码设置成UTF-8就行
request.setCharacterEncoding("UTF-8");
get的乱码:
get是字符串读入的:String getQuerString
首先要清楚这个过程,是怎么传递的:我们输入中文(UTF-8)–》浏览器给我们会自动转成URL编码(十六进制)–》tomcat会解码URL,转成ISO-8859-1的字符串。
要想解决这个问题,首先想到能不能把解码方式转成U8?可惜tomcat的这个是写死的,所以我们需要对ISO-8859-1这个字符串下手。虽然编码格式不一样,但是他们对应的二进制位是一样的,所以我们可以把他们转成byte的形式(字节形式,每个字节是四个比特位,转成的十进制数),然后把这个byte数组转成u的字符串就可以了。
具体操作:
//首先把字符串按对应编码转成字节数组
byte[] bytes = username.getBytes(StandardCharsets_8859_1);
//然后把字节数组转成UTF8
username = new String(bytes,StandardCharsets.UTF_8);
//可以把上面两个合二为一
username = new String(username.getBytes(StandardCharsets_8859_1),StandardCharsets.UTF_8);
细节:转码过程细节是怎么样呢?
URL编码方式:四个比特位为一个16进制数,每两个16进制前面加上百分号
比如“张三”这个汉字:会按UTF-8编码转成6个字节(一个汉字3个字节),一个字节8个比特位。也就是48个比特位。
然后每个字节也就是每8位,用两个十六进制表示,然后前面加百分号即可。

解码过程同理
③Request请求转发
资源A 处理完转给 资源B 处理,处理完再响应,只需要在A中加上一行代码即可
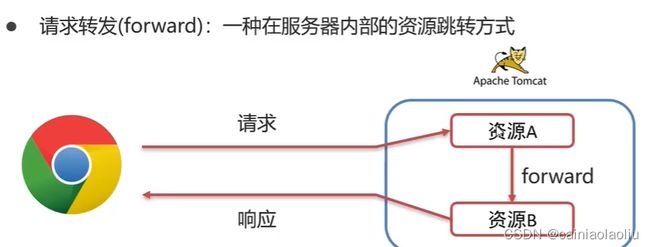
req.getRequestDispatcher("资源B路径").forward(req.resp);
//请求转发资源间共享数据:使用request对象,下面这些是request的一些方法
//其实就是调用request的这些方法,往里面放东西而已
//第一个是放一个key和一个value
void setAttribute(String name,Object o) //存储数据到request域中
Object getAttribute(String name); //根据key,获取值
void removeAttribute(String name); //根据key,删除该键值对
特点:
浏览器地址栏路径不会改变
只能转发到当前服务器的内部资源
一次请求,一次响应。
(2)Response
设置响应数据,用到时候就取出来
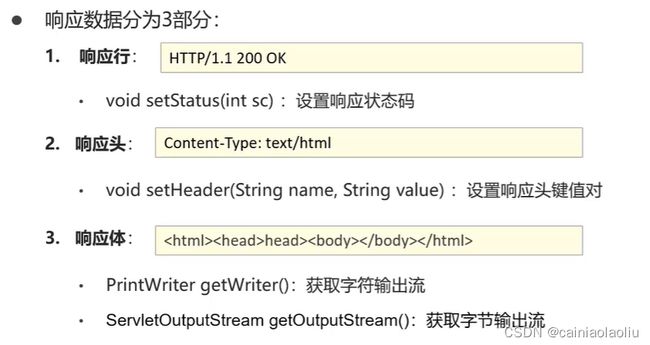
①Response设置响应数据功能介绍
②Respnose完成重定向
什么是重定向?——浏览器访问资源A ,A处理不来要B处理。然后A给浏览器一个重定向响应(302状态码),意思是告诉你这个请求我处理不了,你去找资源B,资源B的路径也会随着重定向在响应头里返回

代码实现:
//设置响应状态码302
response.setStatus(302);
//设置响应头Location(value位资源B的地址)
response.setHeader("Location","地址");
//由于302和location关键字都是固定的,所以我们通常用封装后的代码简化
response.sendRedirect("地址");
特点:
浏览器地址栏发生变化
可以重定位到任意资源
两次请求,不能通过request共享资源。
什么时候要加虚拟目录?什么时候只用名字就可以?
给服务器使用,比如转发,就不用虚拟目录
但是给浏览器用的都要加虚拟目录(就是URL那一套)
动态获取虚拟目录:
String contextPath = request.getContextPath();
//重定向
response.sendRedirect(contextPath+"/resp2");
③Response响应字符数据
通过
PrintWriter write = response.getWriter获取字符输出流
然后写就可以
write.write("")
在写之前可以设置一下content-type,就可以告诉浏览器下面是html的,按照html来解析
resopnse.setHeader("content-type","text/html")
中文也会乱码。可以通过设置流的编码,同时也把html设置了
response.setContentType("text/html;charst=utf-8")
不需要关response获取的流,响应结束response会被销毁。
④Response响应字节数据
获取字节输出流(音频图片视频等)
1.读取文件
FilerInputStream fis = new FilInputStream("视频地址");
2.获取字节输出流
ServletOutputStream os = response.getOutputStream();
3.完成流的copy
byte[] buff = new byte[1024];
int len = 0;
while((len = fis.read(buff)) != -1){
os.write(buff,0,len);
}
fis.close;
当然,第三步是底层,我们现在一般用工具类,完成复制
也就是IOUtils这个工具类的copy接口
IOUtils.copy(fis,os);
这个工具类需要导坐标(使用的时候导包别倒错,是阿帕奇的)

5.会话技术
会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。在一次会话可以包含多次请求和响应。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一台浏览器,一边在同一次会话的多次请求间共享技术。(比如我们在购物的时候,同一个用户点击不同的功能,也就是发送不同的请求,就需要几次请求共享用户名等数据)
因为HTTP协议是无状态的,每次浏览器向服务器请求时,服务器都将视该请求为新的请求。(因为如果携带数据的话,那么HTTP的携带数据量会越来越大,后续的访问会变慢)所以我们要想要共享数据的话,就需要用会话跟踪技术。
实现方式:
客户端会话跟踪技术:Cookie(把数据放在客户端)
服务端会话跟踪技术:Session(把数据放在服务端)
原理只是数据放的位置不同而已
(1)Cookie(客户端会话跟踪)
①Cookie基本使用
将数据保存到客户端,以后每次请求都携带Cookie数据进行访问。
我们主要是服务端开发, 关心的是发送Cookie对象给浏览器,以及从浏览器获取Cookie对象。至于Cookie在浏览器怎么储存的,我们不关心。
发送cookie
- 创建Cookie对象,设置数据
Cookie cookie = new Cookie("key","value");
- 发送Cookie到客户端,使用response对象
response.addCookie(cookie);
获取cookie
- 因为传来的不止是一个cookie,所以我们要获取所有的cookie(数组形式),然后遍历
Cookie[] cookies = request.getCookie();
- 遍历数组(在里面加判断语句,获得自己想要的那个cookie)
for(Cookie cookie : Cookie){
String name = cookie.getName();
String value = cookie.getValue();
}
②Cookie原理
cookie实现是基于http协议的
发送cookie——response
响应头加了个set-cookie参数
获取cookie——request
请求头加了个cookie
③Cookie细节
- cookie的存活时间:默认是存放在浏览器的内存中,当浏览器关闭,内存释放,则cookie被销毁。
当然,我们有时候需要浏览器关了下一次开也能存在(比如记住密码功能),可以使用一个自带的api。——setMaxAge(int seconds):设置cookie的存活时间
输入正数——到时间自动删除
输入负数——默认关闭浏览器就销毁
零——删除对应cookie
//创建cookie
Cookie cookie = new Cookie("key","value");
//设置存活时间2424秒
cookie.setMaxAge(2424);
//发送cookie
response.addCookie(cookie);
- 存中文
cookie不能存中文,不然会报错(报500)
要想存中文,就得先转码(转URL),然后取的时候再转回去。
//转成URL编码方式
String value = URLEncoder.encode("张三","UTF-8");
//解码
URLDecoder.decode(value,"UTF-8");
(1)Session(服务器会话跟踪)
客户端存数据,不是很安全,因为一直在网络中传输
Session是服务器中的对象,每个servlet都可以获取同一个Session对象,这样就可以共享了。
①使用规则
- 获取session对象
//javaEE提供了HttpSession接口,来实现功能(用request来获取session)
//这里的request需要时GttpServletRequest类型的,如果不时要强转
HttpSession session = request.getSession();
- 使用Session对象功能
//存储数据到session域中
void setAttribute(String name,Object o);
//根据key,获取值
Object getAttribute(String name);
//根据key删除对应数据
void removeAttribute(String name);
②原理
我们前面说,同一个浏览器开启会话,然后会话期间可以多次请求多次响应而保存数据,我们把数据放在session里,每次获取session
这里就存在一个问题,怎么能保证我同一个浏览器请求时,获取的是同一个session呢?如果不是同一个session,那么不就出问题了嘛(如图,同一个浏览器的请求,才会获取到同一个session)
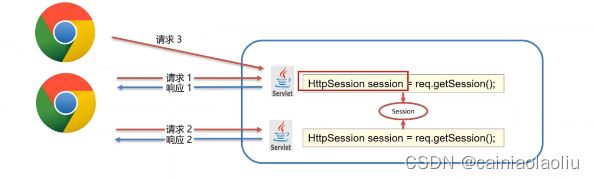
实现原理:session是基于cookie的
其实就是获取的session有一个id
然后通过cookie发给浏览器
下一次再后获取他的cookie里的session的id
③细节
-
Session 钝化、活化
服务器重启后,Session的数据是否还在?钝化:在服务器正常关闭后,tomcat会自动把数据加载到硬盘的文件中
活化:在启动服务器后,从文件中加载数据到session中。
也就是不会丢失但是,如果浏览器关了,那么cookie也没了(默认生命周期为-1).那再打开就不是原来的session了——不能长期存
-
Session销毁
①session默认情况下无操作30分钟就会销毁(也可以设置)(就是可能有的页面会提示,你已经长时间没操作,将要自动退出)

②可以自毁(也就是退出登录的感觉)
调用session对象的invalidate方法
(3)cookie和session异同
相同点:二者都是用来完成一次对话期间多次请求的数据共享的
不同点:
- 存储位置不同
- 安全性:cookie需要一直传递,会被截获,不安全。session安全。
- 数据大小:cookie最大3KB,session无大小限制。
- 存储时间:cookie可以长期储存(自己设置0,-1,或者秒数 ),session默认三分钟
- 服务器性能:cookie不占服务器资源,session占服务器资源
5.filter过滤器
请求和响应会通过过滤器(也就是会执行过滤器里的代码)(拦截并放行)
一般完成一些通用的操作,比如权限控制、统一编码处理、敏感字符处理等……
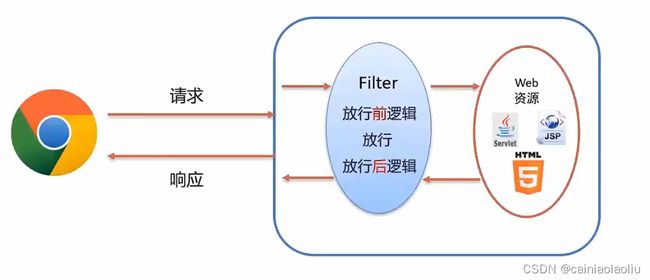
(1)快速入门
定义类,实现Filter接口,并重写其所有方法(三个方法)
//三个方法分别是初始化init、销毁destory以及doFilter执行方法
//前两个和servlet里的是一样的作用
//具体拦截后的操作写在doFilter方法里
//在doFileter要放行,请求才能通过过滤器——chain.doFilter(request,response)
给类加注解
@WebFilter(“/*”) //括号里代表的是拦截的请求范围

(2)执行流程
请求的时候,会被拦截,然后处理后放行
然后响应的时候,是不是还需要过滤,那么过滤的时候,是从头开始执行,还是执行放行之后的逻辑呢?

如图,是执行放行之后的逻辑,因为如果从头开始,那就是执行了两遍相同代码了。
怎么实现的呢?doFilter的参数是request、response、chain,一般我们会在放行前,对request数据进行处理,然后在放行语句之后,写response的代码

(3)细节
拦截路径的配置:

过滤器链:一个web应用,可以配置多个过滤器,称为过滤器链
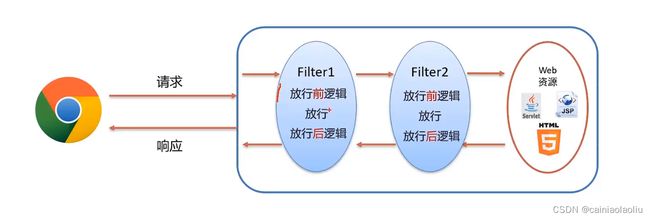
过滤器的执行顺序:按照过滤器的名字,一个一个字比较,先执行小的。
(4)案例——登陆拦截(无验证环节)
访问服务器资源的时候,首先要进行登陆验证,如果没有登录,就自动跳转到登录界面
1.如何判断用户是否登录?——session中是否有user对象
有:说明已经登录,直接放行
无:跳转到登录界面,并给出提示信息
2.登录或注册的时候,这两个页面也是服务器中的,所以我们应该允许访问的页面时登录页和注册页的时候,也可以过拦截。
5.监听器
