基于《Arbitrary Style Transfer with Style-Attentional Networks》的视频风格迁移
一、方法介绍
本文是参照Arbitrary Style Transfer With Style-Attentional Networks[1]中图像风格迁移的方法去实现视频风格迁移。其工作的主要贡献为:
1)提出了SANet去灵活匹配风格特征和内容特征在语义上相近的部分;
2)针对SANet和decoder组成的网络提出了新的损失函数;
3)风格化图像的效率以及质量都很高。
源码:https://github.com/GlebBrykin/SANET
1.1总体结构
图1是论文[1]方法的总体框架。

图1 算法框架
从图1中看出该算法主要由编码器、SANet以及解码器构成。编码器使用的是预训练好的VGG19,用来提取内容图像和风格图像的特征,SANet负责将来自VGG19的Style feature map和Content feature map根据其注意力进行结合,而解码器的网络结构则是与编码器所对称的,可以利用结合后的feature map进行图像的重建,得到的图像即为风格化后的图像。本算法利用了VGG19的Relu4_1和Relu5_1两个网络层输出的特征去进行结合,这是因为只使用Relu4_1可以很好保留风格图像和内容图像的全局结构,但其局部风格显示效果不好。而Relu5_1对其局部风格表现的效果较好,因为其接受域更大。所以利用Relu4_1和Relu5_1输出的特征都利用两个SANet结合后再整合得到最终的风格图像。其效果展示见图2。

图2 不同网络层特征进行风格化的效果对比
1.2 SANet
下面对算法中建立的SANet进行简单的介绍,其网络结构见图3。

图3 SANet结构
SANet主要由3个(1,1)的卷积层构成,其输入Fc和Fs为VGG19输出的内容图像和风格图像的特征图。对其先进行归一化处理得到![]() 和
和![]() ,然后通过f和g计算其注意力,公式如下:
,然后通过f和g计算其注意力,公式如下:
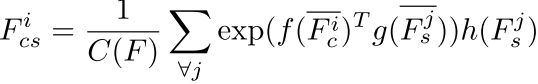
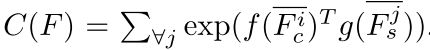
C(F)为归一化因子。SANet可以通过学习来映射内容和样式特征图之间的关系(例如相似度),从而在内容特征图的每个位置嵌入适当的风格特征。
1.3损失函数
本文训练所使用的损失函数由三部分组成,分别是传统的风格和内容损失以及本文新提出的identity损失。
![]()
![]()
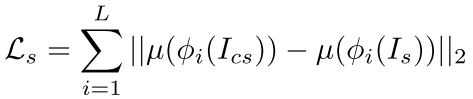
![]()
如图1显示,我们借助了预训练好的encoder去计算损失函数。其中内容损失计算的是风格化图像通过encoder的特征与原内容图像的特征归一化后的欧几里得距离。风格损失是计算的Relu1_1,Relu2_1,Relu3_1,Relu4_1,和Relu5_1上的AdaIN风格损失。Identity损失的计算过程见图4。

图4 identity损失计算图
输入的内容图像和风格图像为同一张图,再利用得到的风格化图像与原图在像素级上和感知层上计算差异。
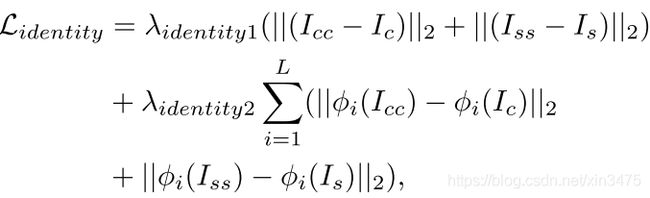
图5展示了损失函数中权重对风格迁移结果的影响。其中(a)将λidentity1、λidentity2和λs分别固定为0、0和5,并将λc从1增大到50所获得的结果;(b)通过将λc和λs分别固定为0和5,并将λidentity1和λidentity2分别从1到100和从50到5,000增大获得的结果。

图5 不同权重配比下的风格化结果
在没有identity损失的情况下,如果增加内容损失的权重,则可以保留内容结构,但是由于内容损失和风格损失之间的权衡,风格的特征会逐渐消失。 相反,在没有内容损失的情况下增加identity损失的权重,可以在保持风格的同时尽可能多地保留内容图像的结构。但是,无法避免内容结构的失真。因此,采用了内容损失和identity损失的组合来维护内容结构,同时丰富风格特征。
二、改进
源码:https://github.com/EnchanterXiao/video-style-transfer
2.1 基础模型
我们使用的基础模型,是上文预训练的模型。使用的内容图像数据集为COCO2014,风格图像数据集为WikiArt。优化函数使用的是Adam,初始学习率为1e-4,batch size为5(5对内容和风格图像),迭代的次数为500000。其参数配置为λc=1,λs=3,λidentity1=50,λidentity2=1。
2.2添加损失函数
由于原文的目的是图像的风格迁移,当将其直接应用于视频风格迁移时,其输出的结果在流畅度上并不是十分令人满意的。所以我们们通过添加时序上的平滑损失和图像空间上的平滑损失,来增加视频的流畅度。
图像空间上的平滑损失来源于文[2],通过计算生成图像在水平和垂直轴上的平均梯度作为损失函数。

时序上的一致性通过查找文献,发现一般主要由两种方式去进行实现,一类从模型角度引入 voxel 的关联,另一类从损失函数的角度限制。在视频风格迁移中,时序损失函数上比较常见的方法是计算前后帧输入图像的光流,其利用t-1帧的输出图像以及光流预测t帧的图像,再与t帧的输出结果计算差异。但是,我们在自制视频数据集上进行损失函数的测试时,发现了两个问题:一是训练时间的增长较多,二是相邻帧的图像利用光流预测后的差异有时候要比直接计算的差异还大。基于以上原因,我们选择了论文[3]中提出的思路,直接用相邻帧之间的特征图的差作为时序上的损失。但是个人感觉该loss虽然可以保证视频的平滑,但是也可能抑制帧之间该有的变化。

2.3 视频数据集
为了提升该模型在视频迁移上的效果,我们利用视频序列制作了专门的内容图像的数据集。我们从videvo.net上随机下载了63个短视频,其时长都在30s以下,将其解帧,其中60个视频序列为训练集,大约27000张图片,3个作为测试集。
2.4 实验
我们的实验是微调文[1]中预训练好的模型,加入2.2中的损失函数。利用2.3中的数据集和WikiArt数据集进行训练。相关参数与2.1保持一致,新添加的损失函数权重分别为λt=2,λtv=20。同时对训练数据的抽取方法进行调整,随机抽取图片时会同时返回它的前一帧图片。进行100000次的迭代,在NVIDIA Titan X上的训练时间约为30小时,学习曲线见图6。
微调之后的结果对于视频风格迁移的效果明显优于基准模型,效果对比请见demo附图。



图6学习曲线(从上到下依次是Lt、Ltv以及Ltotal的loss曲线)


参考文献
- Park D Y, Lee K H. Arbitrary Style Transfer With Style-Attentional Networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 5880-5888.
- Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
- Pan Y, Qiu Z, Yao T, et al. To create what you tell: Generating videos from captions[C]//Proceedings of the 25th ACM international conference on Multimedia. ACM, 2017: 1789-1798.