yolov5、YOLOv7、YOLOv8改进:注意力机制CA
论文题目:《Coordinate Attention for Efficient Mobile NetWork Design》
论文地址: https://arxiv.org/pdf/2103.02907.pdf

本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,Coordinate注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
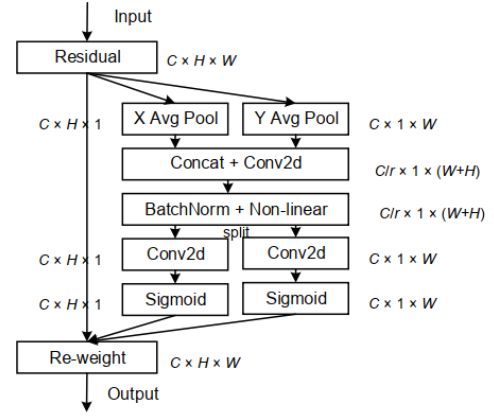
不同于通道注意力将输入通过2D全局池化转化为单个特征向量,CoordAttention将通道注意力分解为两个沿着不同方向聚合特征的1D特征编码过程。这样的好处是可以沿着一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。然后,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,它们可以互补地应用到输入特征图来增强感兴趣的目标的表示
下面附上改进代码
YOLOv5改进:
common中加入
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
# Coordinate Attention for Efficient Mobile Network Design
'''
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting
model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a
novel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, which
we call “coordinate attention”. Unlike channel attention
that transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding
processes that aggregate features along the two spatial directions, respectively
'''
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
pool_h = nn.AdaptiveAvgPool2d((h, 1))
pool_w = nn.AdaptiveAvgPool2d((1, w))
x_h = pool_h(x)
x_w = pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
在yolo.py中注册
找到parse.model模块 加入下列代码
elif m in [CA]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
添加配置文件
# YOLOv5 , GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth iscyy multiple
width_multiple: 0.50 # layer channel iscyy multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CA, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
到此YOLOv5就改好了
下面介绍yolov7
同样在common中加入以下代码
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CA(nn.Module):
# Coordinate Attention for Efficient Mobile Network Design
'''
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting
model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a
novel attention mechanism for mobile iscyy networks by embedding positional information into channel attention, which
we call “coordinate attention”. Unlike channel attention
that transforms a feature tensor to a single feature vector iscyy via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding
processes that aggregate features along the two spatial directions, respectively
'''
def __init__(self, inp, oup, reduction=32):
super(CA, self).__init__()
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
pool_h = nn.AdaptiveAvgPool2d((h, 1))
pool_w = nn.AdaptiveAvgPool2d((1, w))
x_h = pool_h(x)
x_w = pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
在yolo.py中注册
找到parse.model模块 加入下列代码
elif m in [CA]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
添加配置文件
# YOLOv7 , GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel iscyy multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, C3, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, C3, [1024]],
[-1, 1, Conv, [256, 3, 1]],
]
# yolov7 head by iscyy
head:
[[-1, 1, SPPCSPC, [512]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[31, 1, Conv, [256, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3, [128]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[18, 1, Conv, [128, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3, [128]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, CA, [128]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 44], 1, Concat, [1]],
[-1, 1, C3, [256]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 39], 1, Concat, [1]],
[-1, 3, C3, [512]],
# 检测头 -----------------------------
[49, 1, RepConv, [256, 3, 1]],
[55, 1, RepConv, [512, 3, 1]],
[61, 1, RepConv, [1024, 3, 1]],
[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
至此v7就配置完成了
v8的配置同v5是一样的。