【C++】STL map和set用法基本介绍
map、set用法简介
- 前言
- 正式开始
-
- set
-
- 构造
- erase
- find
- swap
- count
- lower_bound 和 upper_bound
-
- lower_bound
- upper_bound
- equal_range
-
- pair
- multiuset
-
- find
- erase
- count
- map
-
- 构造
- insert
- [ ]
-
- [ ]底层原理
- multimap
- 两道题目
-
- 前K个高频单词
- 两个数组的交集

前言
首先,使用map和set最少要了解二叉搜索树,如果点进来的同学对于二叉搜索树还不熟悉的话,可以先看看我这篇博客:【C++】二叉搜索树。
当然,如果想要更深入的理解map和set的话,肯定是还要学更高级一点的树的,就比如说AVL树、红黑树,但是这里只想要简单用用的话,二叉搜索树先搞清楚就差不多够用了。
本篇主要讲讲map和set的基本用法,最后会有两道题来巩固一下。
后面的两篇博客来说一说关于AVL树的实现和红黑树的实现来更好的理解map和set。
正式开始
STL将容器分为两种。
一种是序列式容器,也就是数据结构中的线性表,包括有vector、list、deque等等。
还有一种是关联式容器,比如我们这里要讲的map和set。关联就是指存放的元素之间是相互关联的,可以通过某一元素来找到其他元素,不像vector那样的,各存各的元素。
那么set和map对应到前一篇的二叉搜索树中分别就是key模型和key/value模型。
先来说set。
还是cplusplus的网站:set,里面的接口我挑着讲。
set

如上所示,三个模版参数。
- T就相当于是key。
- compare是仿函数,默认情况下的是less,就是左<根<右。如果传的是greater就是左>根>右。
- alloc就是给内存池,这个参数和之前那些容器一样,还没有到该讲的时候,先不讲。
构造

这三个最常用的就是无参构造。
无参构造初始化了之后就不断插入:

insert接口如下:

还是插值、按位置插、迭代器区间。后两个用的都很少。
第一个插值的返回值这里先不细讲等会讲map的时候会说。
如果我们想要遍历的话可以用迭代器:

这里set的迭代器只支持访问,不支持修改,如果直接*it修改的话会报错。
当然有了迭代器就支持范围for:

C++11里面还有个用大括号初始化的:

这个演示一下:
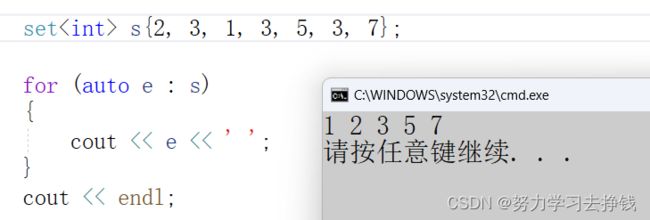
这里插入的时候会直接去重,然后遍历的时候打印出来是有序的,这也和二叉搜索树的特性是相符的。
迭代器区间构造用到的场景比较少。

我们可以将compare改为greater的,这样遍历的时候用正向迭代器就变成了降序:

如果用less但是还想排降序的话,可以用反向迭代器:

拷贝构造用的也比较少,因为拷贝构造的开销还是比较大的,用的时候要慎重。
还可以用数组来初始化:

erase

删除,值、位置、迭代器区间。后两个不常用,演示第一个:
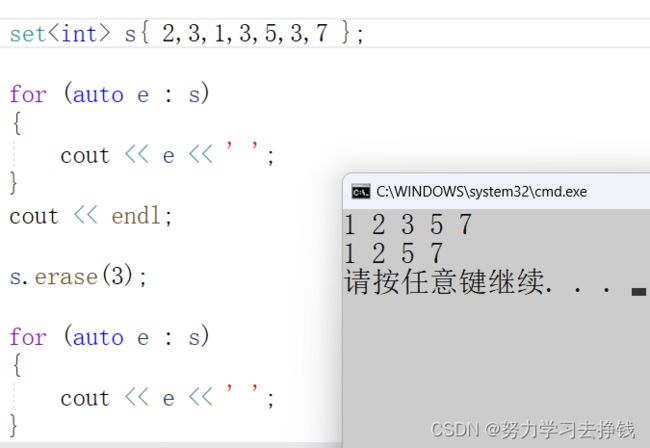

find

find的值如果存在,就返回那个值对应的迭代器。如果不存在,就返回end()。
这里可以用find来查找并删除某值。
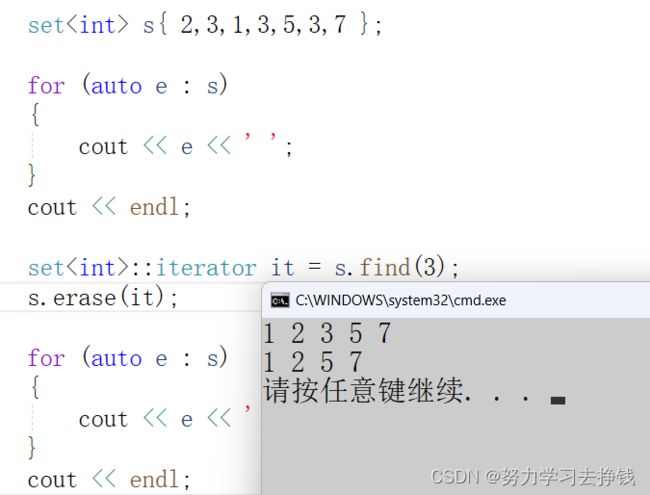
因为可能有值不存在的情况,所以上述的写法是不严谨的,如果删除一个不存在的数就会出问题:

上面是debug的,如果是release的话就会直接出问题,因为release下会省略assert:

所以应该这样写:

判断一下是不是end,是了再删除,不是的话就别删。
这里里比直接erase值更好的一点是,如果某个值不存在,那么就可以打印出该值不存在的信息,如果是直接用erase删除的话,就没法打印了。

如果不需要打印信息的话可以直接用erase删值。
swap

两个set的对象交换的时候就用set的swap,因为set的swap就是简单的将根节点的指针交换就行了。不要用算法库中的swap,赋值和拷贝构造的开销会很大。
count

这个函数就是统计某个值出现的次数,可以说对于set来说没有什么用,因为set中的值永远出现的是一次。
set中有这个函数单纯是为了使得库提供的函数接口的一致性而给的,因为multiset中就有这个count,而multiset就和set的底层一样,但是multiset允许键值冗余,所以可以有多个值同时存在,我们就可以在multiset中使用count。
不过我们可以用count来判断某个值是否存在,如果存在返回1,如果不存在返回0。

lower_bound 和 upper_bound
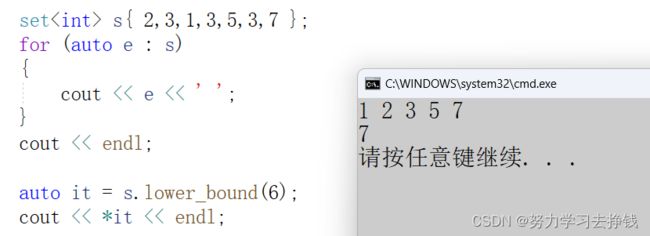
lower_bound
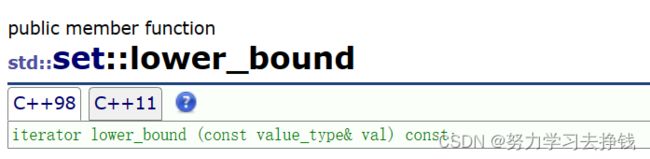
这个函数返回>=val的值的迭代器,如果这个>=的值存在的话,就返回这个值的迭代器,如果不存在的话就返回end。

upper_bound
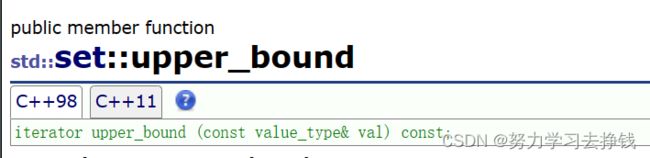
这个是返回>的值的迭代器。
直接给个和lower_bound一块的示例:

equal_range

这里的返回值为pair,这里讲一讲。
pair

就是一个存放一对值的结构体。
两个值库中定义的名字是first和second。
大概代码如下:
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
所以就好说了。
上面的返回值为pair,而且pair中两个参数的类型是迭代器。也就是返回两个值的迭代器。
返回的是一个左闭右开的区间:[x, y)。(x,y均为迭代器)
如果val的值存在于树中,x=val,y为++x。
如果val不存在,但还在值的范围内,x>val,y=x;不在范围内,x,y都是end()。


multiuset
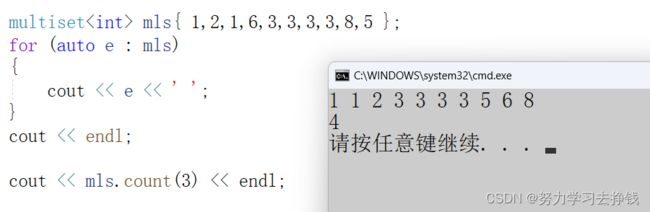
上面也提到了,这个类型支持键值冗余,也就是可以同时存放多个值。
演示一下:

这里的multiset就是单纯的排序了。没有了去重的功能。
find
这里find的话,如果值没有重复,就返回那个值的迭代器,如果重复了,就返回中序遍历顺序下该值第一次出现的值的迭代器。

如果想要访问第二次出现的值的话++一下返回的迭代器就好了。
erase
这里如果是删除重复的值的话,比如说x,会把x全部删除。

和上面给迭代器的删除不一样。
count
这个上面也提过了,这里可以用。
其他功能就跟set类似了,这里就不继续讲,multiset了。
map
map也分map和multimap,和上面一样,multimap允许键值冗余,而map不允许。
二者都是二叉搜索树中的 key/value 模型。
先来说map。

这里有四个模版参数。
第一个是键值key,这个值是用来进行关键字的比较的。
第二个是附加项T,这就是一个与key相关的一个值,插入的时候是按照key比较的,而不是T。也就是二叉搜索树中key/value模型中的value。
第三个是仿函数Compare,默认值也是less,不过less只有一个key,也就是比较的时候按照key比较,T不会参与。
第四个是内存池,暂时不讲。里面的那个pair前面也讲过了。
map中有几个内嵌类型(map中typedef的类型)要说一下。

- key_type 模版参数中的第一个参数key
- mapped_type 模版参数中的第二个参数T
- value_type pair
- key_compare 模版参数中的第三个参数Compare
构造
一般没有直接初始化的时候就给值的,直接调用一下默认构造然后再插入或者用[ ]就行。
所以这里就不讲了。注意一下拷贝构造慎用,消耗较大。
insert

这里insert,看第一个,返回值先不说,先说参数。
参数为value_type,也就是pair
那么我们用的时候要这样(下面的例子为写一个字典):

可以看到,排序的时候是按照ASCII排的。
但是这样有点麻烦了。
可以用匿名对象:

但是也没有方便到哪去。
我们可以typedef一下pair:

还有一个接口,专门用来搞pair的。
就是make_pair。

这个函数的大概实现为:

其实就是搞了个pair的对象。
用用:

用的时候可以不像pair那样显示写类型,make_pair是一个函数模版。
上面的都是用范围for来遍历的,下面来说说用迭代器遍历。

上面可以看到,it解引用得到的是pair类型的对象,然后一个 . 访问其first和second。
如果我们想用指针呢?
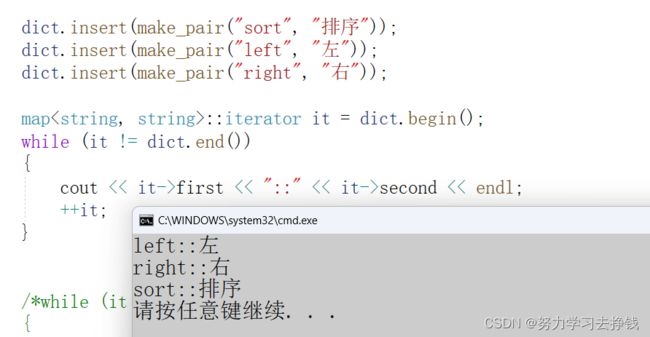
前面list模拟实现的博客中也讲过了,it->返回的是pair类型的指针,如果想要再访问pair中的成员时,就要再加一个->,但是这里为了可读性,编译器做了优化,直接省略掉了一个->。
注意到我上面用范围for的时候里面的赋值为const auto& e的,重在引用,因为map中的存放的为pair类型的数据,如果pair中又存放了string或者其他自定义类型的数据的话,用引用效率就会高不少。
其实上面的insert用的也不多,我只是为了给大家演示演示。
用的最多的还是[ ]。
[ ]
这个才是最需要学的。
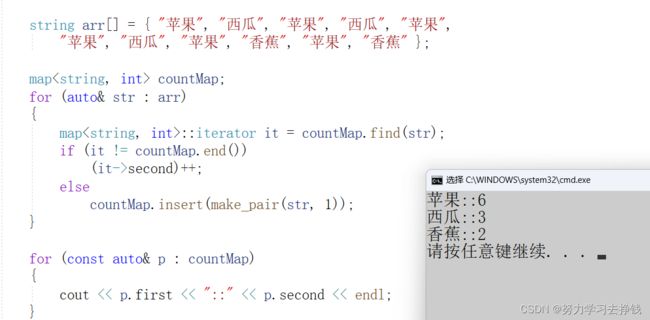
如果我们想要用map统计……出现的次数,怎么搞呢?
比如:统计这里面各个水果出现的次数。
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果",
"苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
两种方法:
- 用insert
代码如下:
- 用[ ]
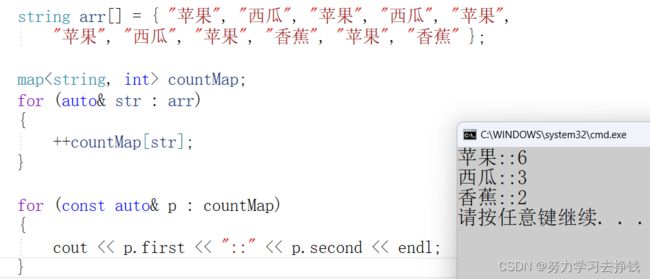
可以看到,用[ ]非常的方便。
那么[ ]底层不了解的话,上面是很难看懂的,下面就来说说。
[ ]底层原理

返回值是mapped_type就是第二个模版参数T。也就是对应到pair中的second的类型。
实际的返回值是这样的:

新手可能一眼就被吓到了。我们来逐个分析分析。
首先里面有个insert,用到了这个函数的返回值。
那么insert返回值刚刚没讲,就是要在这里讲。
对比一下上面的调用的话,就是第一个插值的insert,返回值为pair
看下库中的解释:

意思就是上面提供的第一个insert函数返回了一个pair类型的对象(假如说是x),不管是插入了新元素(假如说新插入的元素是y)或是原来map中就有这个元素y(原来有的话就不会插入),x的first都会指向insert之后的map中的元素y,也就是那个元素的迭代器;如果原来map中没有这个新插入的元素y,x的second就是true,代表插入成功了,如果原来map中有这个新插入的元素y,x的second就是false,代表插入失败了。
再看一下函数调用:

我把insert对应的括号的匹配给画出来了,去掉之后是:

其返回值是pair对象,然后访问了这个对象的first,first为迭代器,指向新插入的pair,解引用之后又访问了其指向的pair的second,也就是第二个模版参数T。所以最终返回值类型就是第二个模版参数T,对应的就是insert之后的pair的second。
对应到我们上面的countMap[str],其最终的返回值就是striing对象所对应的int。
所以当我们第一次用[ ]的时候,是没有str的,先插入了,然后再让对应的int++了一下。
再看一下上面调用的insert,调用时传参为make_pair(k,mapped_type()),也就是说second会调用其默认构造函数,而上面的int默认值就是0。所以插入之后为0,返回之后再++正好为1,所以插入一次就加一。就达到了统计次数的目的。
如果感觉上面的[ ]重载实现的太难以理解了,我们也可以自己来实现一下:

再总结一下[ ]的返回值:
- map中有这个key,返回的是T的引用。即查找+修改T的功能。
- map中没有这个key,插入一个pair(key, T())并返回T的引用。 即插入+修改T的功能。
现在我们再来写刚刚写过的词典的话就非常简单了。


map中还有个at,也可以返回T的引用,和[ ]不一样的是,at不在的话是抛异常:

可以看到将map的时候有一大堆的pair,可以说pair就是专门为[ ]准备的。
再来说一点关于multimap的
multimap
就说一点,允许键值冗余。
如果允许键值冗余的话,就不能用[ ]和at了,因为如果有重复的元素,编译器不知道该匹配哪个,直接报错:

但是好处就是我们可以插入相同的K值了。

left有左边,也有剩余的意思。可以看到,插入了两次左边,一次剩余。
剩下的就不说了。
下面来两道题来练练手:
两道题目
两道题目链接:
前K个高频单词
两个数组的交集
前K个高频单词

这道题乍一看是topK问题,有的同学就想到了用堆来写。确实可以。
法一:优先级队列
我们先用map来统计一下各个单词出现的次数。然后再根据出现的次数来将map中的各个pair放到优先级队列(大堆)中,然后就可以不断获取堆顶元素来获取topK个单词。
但是题目中要求,各个单词要按照出现频率来排序,当两个单词出现的频率相同时,按照字典序排序,也就是按照ASCII来排。
最终实现的代码如下:
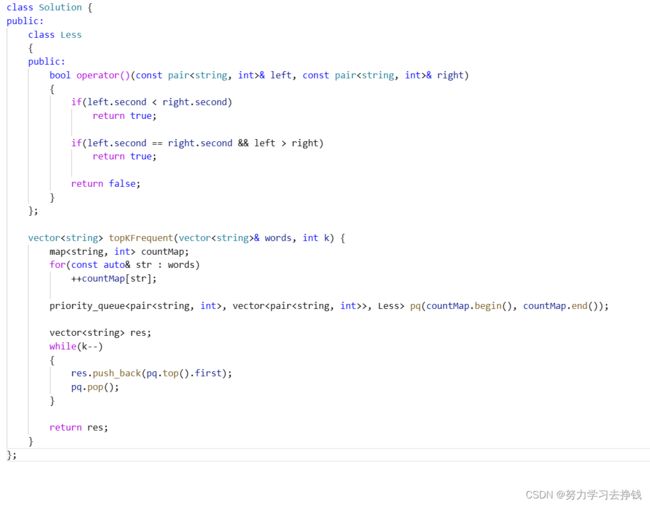
用到仿函数的时候,里面的逻辑有点绕。
法二:数组排序
我们先用map统计次数,此时map中的各个pair的顺序是按照string来排的。然后我们将map中的各个pair放入到数组中,用数组按照pair的second来进行排序。同样也是要写仿函数来控制频率相同的情况。
实现代码如下:

方法三:两个map
两个map,一个用来统计出现次数,一个用来根据次数排序。

两个数组的交集
这道题其实可以直接用双指针,但用双指针的话还要先排序再去重,太麻烦了,我们可以直接用set。
求交集有一个思路。在两个数组有序且不重复的前提下,比如说:

分为上下两个数组。
每个都从头开始遍历:

因为是有序的,所以当某个值 it1 小比另一个值 it2 小的时候,那么 it1 一定比另一个数组中的所有数都小。it2同理。所以小的时候就让其++,然后再对比,等的时候就同时++。当一个走到尽头时,就说明没有交集可找了,此时停下来就行。
因为需要排序 + 去重,而set正好能够满足这个条件,代码如下:

同样的思路,我们可以用来求差集。

就讲到这。
到此结束。。。