【编程二三事】ES究竟是个啥?
在最近的项目中,总是或多或少接触到了搜索的能力。而在这些项目之中,或多或少都离不开一个中间件 - ElasticSearch。
今天忙里偷闲,就来好好了解下这个中间件是用来干什么的。
ES是什么?
ES全称ElasticSearch,是个基于Lucene的搜索服务器。其作为一个高度可拓展的开源全文搜索和分析引擎,可用于快速对大数据进行存储,搜索和分析。
ElasticSearch和Logstash(数据收集、日志解析引擎)、Kibana(分析和可视化平台)一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前被称为ELK技术栈)。
为什么要用ES?
传统关系数据库的缺陷
为了了解ES的优势在哪,我们首先需要回顾传统的mysql数据库作为搜索的时候都有哪些缺陷。
在我们日常搜索的时候,我们都需要通过输入关键词,去检索出来相关的数据。
以搜索“搜索引擎”为例子,你在百度、搜狗等搜索引擎中输入这个关键字,就会得到一系列的搜索结果:
如果这些结果都存储在Mysql数据库中,它大致会呈现如下的存储样式:

每一行会存储唯一标识id、数据内容。
因此,如果需要按照关系型数据库的方式,需要逐行进行搜索匹配相关词,甚至需要用上模糊搜索,如:‘LIKE %xx%’ 等。
且在mysql中,像这类模糊搜索语句,mysql是无法对其建立索引的。因此如果在大数据量下搜索将变得十分缓慢、困难。
而且另外一个点在于,对于搜索引擎来说,还需要将用户输入的词做拆分,依旧是以”搜索引擎“为例子,那么搜索结果其实需要同时包含“搜索”、“引擎”、“搜索引擎”的结果,而这无疑又一次加大了采用关系型数据库实现的复杂性。
总结下来,使用关系型数据库处理搜索问题,主要有两个较大的问题:模糊搜索困难、分词查询支持困难。
那么为什么关系型数据库会有这样的问题呢?本质上是关系型数据库的正排索引限制了其搜索性能。你可能这里会好奇了。什么是正排索引呀?
以上面的数据为例子,正排索引就是先找到对应的文章,而后才能够知道每个文章中对应的词是什么。绘制成图片大概就是下面的样子:
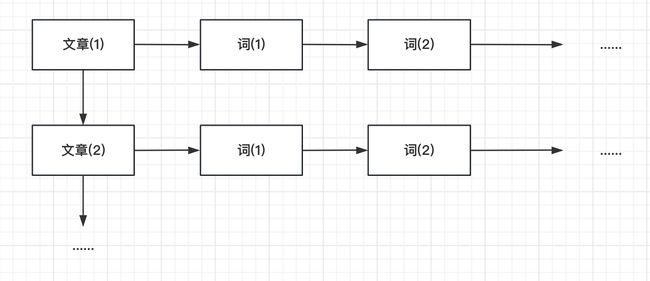
因此,如果用这样正排索引的方式搜索,相当于每次都要进行全表的扫描、匹配,那么自然很难支持搜索的能力。
ElasticSearch优势
倒排索引
上面我们总结了传统数据库实现搜索的主要难度在于:模糊搜索困难、分词查询困难。
而其归根结底是由于数据库的组织方式是通过正排索引实现的。导致了每次搜索需要匹配的难度大。
那么,这里可能就有聪明的同学想到了,如果根据文章搜索词的难度大,那么是否转变一下存储方式,先存词,再存文章,不就可以一下子搜索到了嘛!
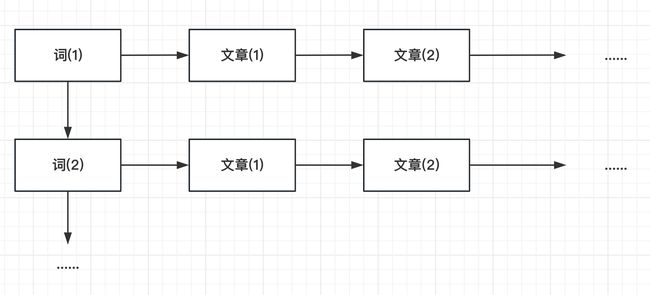
如果你想到了这个,那么恭喜你,你已经具备从零开始研发ES的潜力的。没错,ES为了支持快捷的搜索,底层的实现也是这么做的,而这种实现方法就是大名鼎鼎的----“倒排索引”。
数据存储结构
要更深入的了解ES的倒排索引的设计逻辑,我们可以先参照Mysql的数据存储设计介绍几个ES中的常见名词:
| Mysql等关系数据库 | ElasticSearch数据库 |
|---|---|
| 数据库(dataBase) | 索引(index) |
| 表(table) | 类型(type) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
结合同Mysql的定义对比,我们就不难理解如下的ES数据代表什么含义了:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "china",
"_type": "_doc",
"_id": "beijing",
"_score": 1.0,
"_source": {
"name": "beijing"
}
}
]
}
}
像如上的数据,就是实际通过es查询得到的数据。其中的__index就是代表所属的数据索引; __type就是指所属的的文档类型,__id就是对应分词出来的结果内容
那么我们现在已经知道了ES是如何存储数据的,那么还有个问题:ES建立倒排索引的流程是怎样的呢?这个说来也并不困难,主要有以下四步:
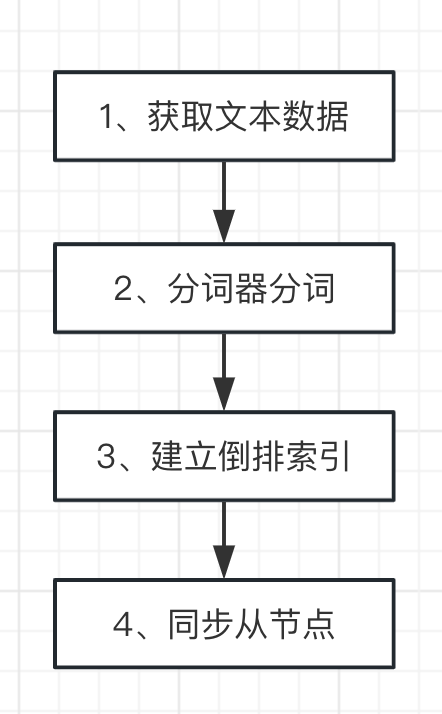
第一步,首先就是需要获取文本数据,常见的方法就有网页爬虫、logstash搜集的方式。
第二步,等到数据收集完成以后,我们需要采用分词器进行分词。就是需要将咱们的文本数据拆分成多个细小的单词,用于后续的倒排索引的建立。
第三步,就是生成倒排索引了。
第四步,就是将相关数据同步到集群中的其他节点上。
存在缺陷
那么说了这么多,ES就没有缺点吗?那当然也不是的,从上述的数据处理流程、处理原理来看,Es主要有两个问题:
1、需要分词,写入存储较慢。
2、需要建立的索引量大。
这两种问题也不难理解。对于ES来说,一个文本存储的方式写入的时候需先分词,拆分成多个词才可以插入到索引中。而进行分词的时候就会耗费较多的时间。
同时相比传统的正排索引,原本只需要建立一个索引的文章,现在需要按照词拆分后建立索引。因此创建出的数量就会比原本多得多。
ES的实际应用
上文介绍了ES的原理、优势和劣势。那么什么场景下会用到ES呢?其实最常见的场景就是日志实时分析。
这是推动 ES 快速发展的场景,从官方统计数字、云上运营经验看,占据了 ES 使用场景的 70%+。Elastic Stack 提供的完整日志解决方案,已经助力 ES 成为日志实时分析的开源首先方案。
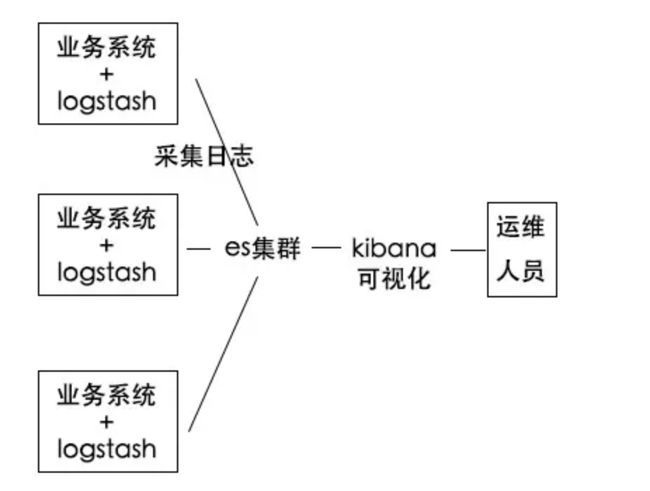
简单来说,日志实时分析主要有三个主要部分组成:logstash、ES集群、kibana。logstash负责收集各个业务系统的日志并推送到ES集群,ES将接收到的日志数据收集起来建立索引。kibana则是提供了一个可视化的搜索能力,用于支持运维人员进行相关报错日志的搜索。
参考文献
ES是什么?
Elasticsearch最新完整版教程通俗易懂,最适合后端编程人员的elasticsearch快速实战教程_ES搜索引擎之核心技术+实战教学
终于有人把Elasticsearch原理讲透了!