专项攻克——MySQL语句与底层原理剖析
文章目录
- 一、参考文献
- 二、基本格式
- 三、基本操作
-
- 3.1 插入
- 3.2 查询
- 3.3 更新
- 3.4 删除
-
- 3.4.1 delete
- 3.4.2 drop
- 3.4.3 truncate
- 四、进阶操作
-
- 4.1 操作符like、通配符
- 4.2 联合表操作
-
- 4.2.1 举例
- 4.3 嵌套操作
- 4.4 SQL常用函数
- 五、数据库索引
- 六、执行查询语句,期间发生了什么?
-
- 6.1 MySQL 的两层架构
-
- 6.1.1 Server 层
- 6.1.2 存储引擎层
-
- (1) Memory
- (2) MylSAM
- (3) InnoDB
- 6.2 详解InnoDB存储引擎
-
- 6.2.1 Buffer Pool 缓冲池
- 6.2.2 undo 日志文件
- 6.2.3 redo 日志文件
- 6.2.4 bin log文件
- 6.2.5 后台线程
一、参考文献
参考:菜鸟教程
二、基本格式
select * from 表名 left join 表名x on 条件1 where 条件2 group by … having … order by …
- 执行顺序:
from _
where __
group by _ :对结果集进行分组
having __:主要和GROUP BY子句配合使用,用于过滤聚合值
select (查看结果集中的哪个列,或列的计算结果)
DISTINCT:去重
order by __
LIMIT
举例:从多个班级中,选出这些条件的班级——数学平均成绩大于75分、平均成绩按从高到低排名最前三的班级。
SQL:select 班级, avg(数学成绩) as 数学平均成绩 where 数学成绩 is not null group by 班级 having 数学平均成绩 > 75 order by 数学平均成绩 desc limit 0, 3。
执行步骤:
- 执行 FROM 子句, 从学生成绩表中组装数据源的数据。
- 执行 WHERE 子句, 筛选学生成绩表中所有学生的数学成绩不为 NULL 的数据 。
- 执行 GROUP BY 子句, 把学生成绩表按 “班级” 字段进行分组。
- 计算 avg 聚合函数, 按group by的班级分组求出 数学平均成绩。
- 执行 HAVING 子句, 筛选出班级 数学平均成绩大于 75 分的。
- 执行SELECT语句,选择数据,继续执行后面几个步骤。
- 执行 ORDER BY 子句, 把最后的结果按 “数学平均成绩” 进行排序。
- 执行LIMIT ,限制仅返回3条数据。结合ORDER BY 子句,即返回所有班级中数学平均成绩的前三的班级及其数学平均成绩。
三、基本操作
3.1 插入
INSERT INTO table_name (column_name1,column_name2,…) VALUES (value1,value2,…)
3.2 查询
查询某些字段:SELECT column_name1,column_name2 FROM table_name;
3.3 更新
UPDATE table_name SET column1=value1,column2=value2,… WHERE some_column=some_value;
3.4 删除
3.4.1 delete
delete语句执行删除的过程是从表中删除行,并且同时将行删除操作作为事务记录在日志中保存,
以便进行进行回滚操作。
请注意添加where:如果省略了 WHERE 子句,所有的记录都将被删除!
例如,DELETE FROM table_name WHERE some_column=some_value;
3.4.2 drop
- drop会删除内容和定义,释放空间。即,把整个表去掉,以后要新增数据是不可能的,只能新增一个表。
- drop语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);
- 依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
drop table 表名称 eg: drop table dbo.Sys_Test
3.4.3 truncate
- truncate (清空表中数据):不删除定义(保留表的数据结构)、删除内容、释放空间、重置主键/自动增长列计数器。
- 与drop不同,truncate 只是清空表数据。
- 注意:truncate 不能删除行数据,要删就会把表清空。
truncate table 表名称
比如,runcate table dbo.Sys_Test
四、进阶操作
4.1 操作符like、通配符
like:
(1)选取 name 以字母 “G” 开始的所有客户:SELECT * FROM Websites WHERE name LIKE ‘G%’;
(2)选取 name 以字母 “k” 结尾的所有客户:SELECT * FROM Websites WHERE name LIKE ‘%k’;
(3)选取 name 包含模式 “oo” 的所有客户:SELECT * FROM Websites WHERE name LIKE ‘%oo%’;
(4)选取 name 不包含模式 “oo” 的所有客户:SELECT * FROM Websites WHERE name NOT LIKE ‘%oo%’;
通配符:
| 通配符 | 描述 | 例子 |
|---|---|---|
| % | 替代 0 个或多个字符 | 选取 url 以字母 “https” 开始的所有网站SELECT * FROM Websites WHERE url LIKE ‘https%’ |
| _ | 替代一个字符 | 选取 name 以 “G” 开始,然后是一个任意字符,然后是 “o”,然后是一个任意字符,然后是 “le” 的所有网站SELECT * FROM Websites WHERE name LIKE ‘G_o_le’ |
| [charlist] (MySQL不支持 ) | 字符列中的任何单一字符 | (1)选取 name 以 “G”、“F” 或 “s” 开始的所有网站SELECT * FROM Websites WHERE name REGEXP ‘^ [GFs]’;(2)选取 name 以 A 到 H 字母开头的网站SELECT * FROM Websites WHERE name REGEXP ‘^ [A-H]’ |
| [^charlist] 或 [!charlist](MySQL不支持) | 不在字符列中的任何单一字符 | 选取 name 不以 A 到 H 字母开头的网站SELECT * FROM Websites WHERE name REGEXP ‘^ [^A-H]’ |
4.2 联合表操作
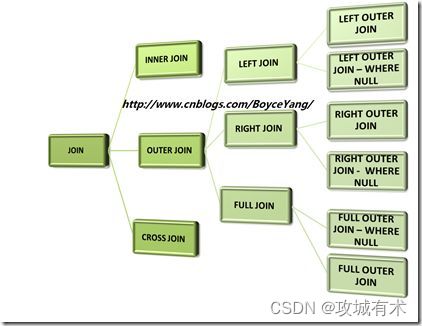
inner join:返回两张表的交集部分;inner join = join
left join:以左表为主表,返回所有左表的数据;left outer join = left join
right join:以右表为主表,返回所有右表的数据;right outer join = right join
FULL JOIN:完全连接可看作是两张表的并集。如果匹配列的值在两个表中匹配,那么返回数据行,否则返回空值。
4.2.1 举例
参考知乎文章
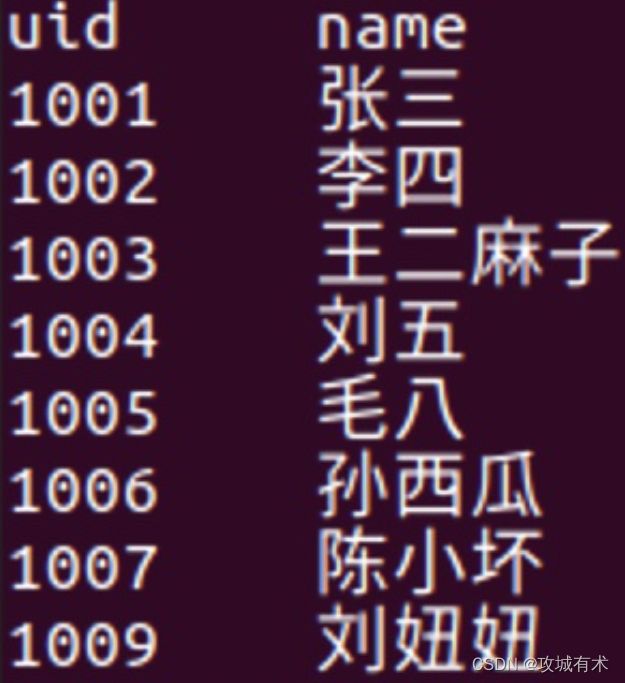
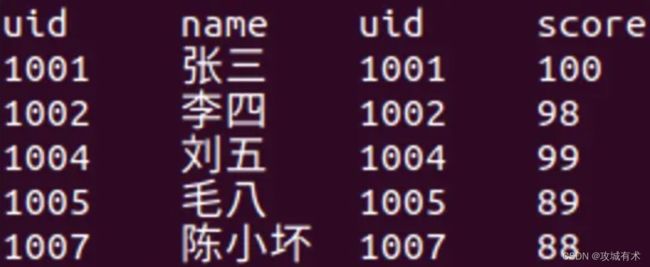
(1)person表
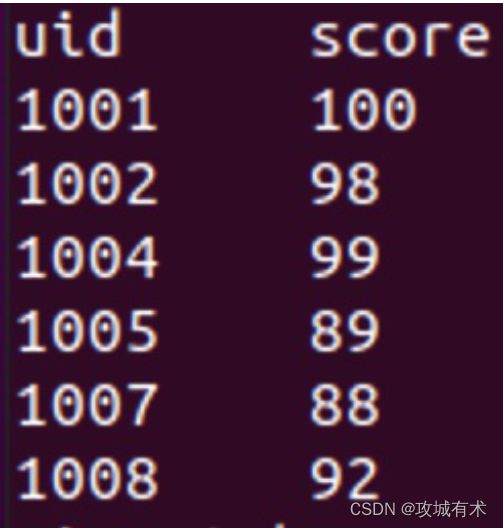
(2)score表
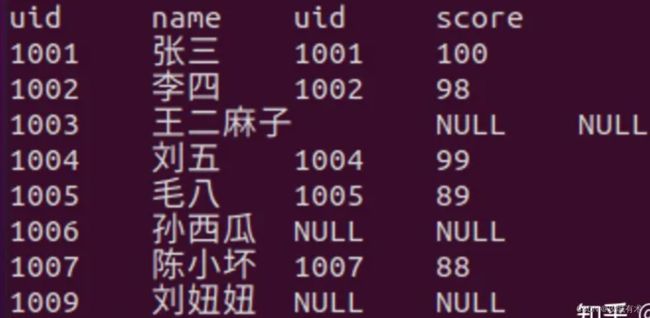
举例
- select * from person t1 left join score t2 on t1.uid = t2.uid
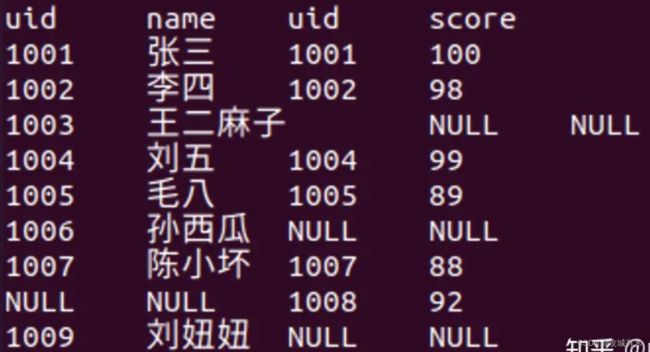
- select * from person t1 join scorep t2 on t1.uid = t2.uid
- select * from person t1 full join scorep t2 on t1.uid = t2.uid
4.3 嵌套操作
略
代码尽量避免嵌套,原因:
- 难写,一旦写错就很难定位,还可能把数据库跑死。
- SQL调试难,只能自己一步步执行子语句调试。
- 长SQL,后期想跟随业务修改太难了。
- 长SQL,过段时间连自己都看不懂,重新看懂跟又开发了一遍似的。
- 复杂 SQL 还会影响数据库移植,在一个数据库上使用的函数放到另一数据库可能不支持。
4.4 SQL常用函数
- 求平均值:avg()
- 求和:sum()
- 求总行数:count
- 求最大值:max()
- 求最小值:min()
- 求第n+1名到第n+m名:limit n,m
五、数据库索引
参考前面写的文章:索引
六、执行查询语句,期间发生了什么?
参考博客:一条SQL查询语句是如何执行的?
MySQL是典型的 C/S架构(客户端/服务器架构),客户端进程向服务端进程发送一段文本(MySQL指令),服务器进程进行语句处理,然后执行并返回结果。
6.1 MySQL 的两层架构
6.1.1 Server 层
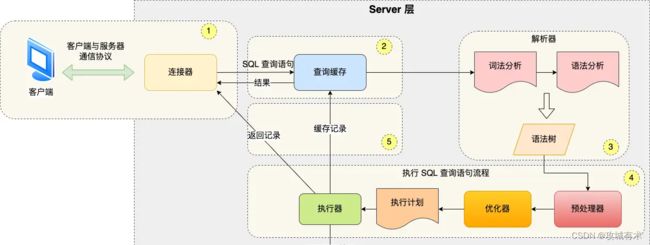
Server 层,是MySQL的核心功能模块,负责建立连接、分析和执行 SQL,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等)都在 Server 层实现。
- 执行一条 SQL 查询语句,期间发生了什么?
-
连接器:
- 建立连接,
- 管理连接。建立连接之后,除非客户端主动断开连接,否则服务器会等待客户端发送请求。但是线程的创建和保持是需要消耗服务器资源的,因此服务器会把长时间不活动的客户端连接断开。
- 校验用户身份;
-
查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块。
-
解析 SQL,通过解析器对 SQL 查询语句进行如下操作,方便后续模块读取表名、字段、语句类型
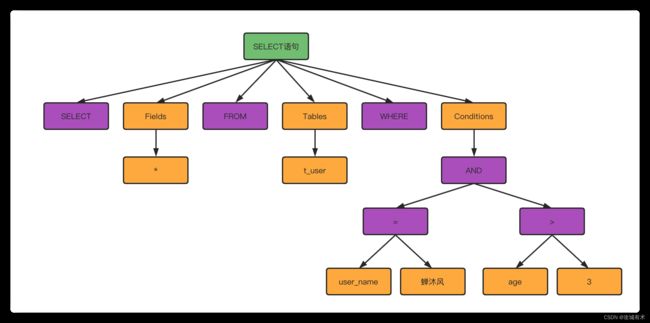
- 词法分析。就是把一条完整的SQL语句打碎成一个个单词,比如,MySQL会把SELECT识别成查询语句;把字符串t_user识别成“表名 t_user”;把字符串user_name识别成“列 user_name"。
- 语法分析。语法分析器会根据语法规则,生成解析树,从而判断SQL 语句是否满足语法,比如单引号是否闭合,关键词拼写是否正确等。
- 构建语法树。
解析树
-
执行 SQL:执行 SQL 共有三个阶段:
-
预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表的所有列。
-
优化阶段:基于查询成本的考虑, 查询优化器会选择成本最小的执行计划;
- MySQL作者担心我们写的SQL太垃圾,所以有设计出查询优化器,辅助我们提高查询效率。
- 查询优化器,会根据解析树生成不同的执行计划(Execution Plan),然后选择一种成本最小的执行计划。这里的成本指【I/O成本 + CPU成本】
- IO 成本: 即从磁盘把数据加载到内存的成本,默认情况下,读取数据页的 IO 成本是 1,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理,所以 MySQL 每次会读取一整页,一页的成本就是 1。所以 IO 的成本主要和页的大小有关
- CPU 成本:将数据读入内存后,还要检测数据是否满足条件和排序等 CPU 操作的成本,显然它与行数有关,默认情况下,检测记录的成本是 0.2。
-
执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端。
-
-
存储引擎处理数据
-
6.1.2 存储引擎层
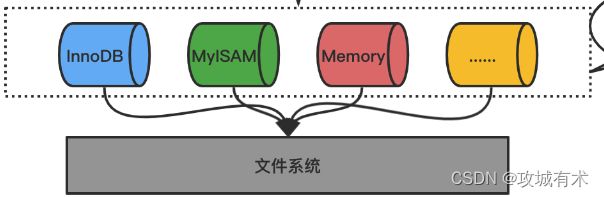
补充知识:
MySQL支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。从 MySQL 5.5 版本开始,MySQL默认InnoDB为存储引擎 。我们常说的索引数据结构,就是由存储引擎层实现的。不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是 B+树,且是默认使用。在数据表中创建的主键索引和二级索引,默认使用的是 B+ 树索引。
- 存储引擎层,负责数据存储和提取,比如数据存储在内存还是磁盘、怎么从表里读取数据,怎么把数据写入表中。
- 表是由一行一行的记录组成的,但这只是逻辑上的概念,其实只是看上去是这样而已。
- 为什么需要多种存储引擎?不同存储引擎特性不同,存储引擎只是读写MySQL数据的插件,可以根据不同目随意更换。
- 如何选择存储引擎?
(1)对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
(2)如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
(3)如果需要一个用于查询的临时表,可以选择Memory。
(1) Memory
Memory存储引擎,以前也称堆引擎,它将所有数据存储在RAM内存中,以便快速访问。
特点:
- 把数据放在内存里面,读写的速度很快。但是,数据库重启或者崩溃,数据会全部消失;
- 只适合做临时表。
(2) MylSAM
应用范围比较小,表级锁限制了读/写性能,因此在Web和数据仓库配置中,通常用于只读或以读为主的工作。
特点:
- 支持表级别的锁(插入和更新会锁表),不支持事务;
- 拥有较高的插入(insert)和查询(select)速度;
- 存储了表的行数(count速度更快)。
怎么快速向数据库插入100万条数据?
- 可以先用MylSAM插入数据,然后修改存储引擎为InnoDB。
- ALTER TABLE 表名 ENGINE = 存储引擎名称;
(3) InnoDB
MySQL 5.7及更新版中的默认存储引擎。InnoDB是事务安全(兼容ACID),它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁和Oracle风格的一致非锁读提高了多用户并发性。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性,InnoDB还支持外键引用完整性约束。
特点:
- 支持事务,支持外键,因此数据的完整性、一致性更高;
- 支持行级别的锁和表级别的锁;
- 支持读写并发,写不阻塞读(MVCC);
- 特殊的索引存放方式,可以减少IO,提升査询效率。
番外:为什么MySQL越来越像Oracle?
InnoDB是InnobaseOy公司开发的,它和MySQL AB公司合作开源了InnoDB的代码。但是,MySQL的竞争对手Oracle把InnobaseOy收购了。后来2008年Sun公司(开发Java语言的Sun)收购了MySQL AB,2009年Sun公司又被Oracle收购了,所以MySQL和 InnoDB又是一家了。
6.2 详解InnoDB存储引擎
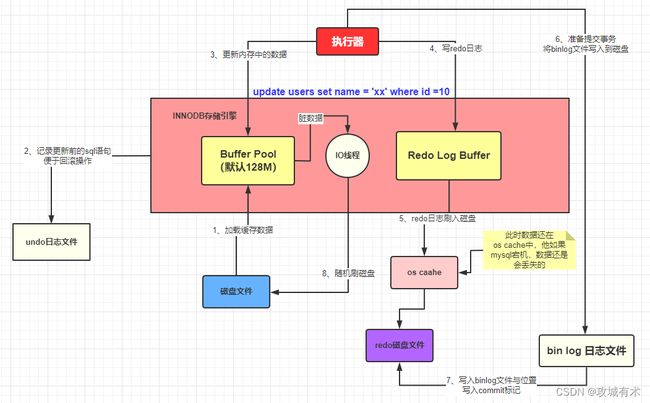
- 事务在InnoDB中从提交到完成的整个流程:
- 准备更新一条 SQL 语句
- MySQL(innodb)会先去缓冲池(BufferPool)中去查找这条数据,没找到就会去磁盘中查找,如果查找到就会将这条数据加载到缓冲池(BufferPool)中。
- 在加载到 Buffer Pool 的同时,会将这条数据的原始记录保存到 undo 日志文件中。
- innodb 会在 Buffer Pool 中执行更新操作。
- 更新后的数据会记录在 redo log buffer 中。
- 提交事务时,会将内存 redo log buffer 中的数据写入到磁盘的 redo log 文件中。
- 提交事务时,MySQL还会:(1)将本次修改的数据记录到 bin log文件中;(2)将本次修改的bin log文件名和修改的内容在bin log中的位置记录到redo log中;(3)在redo log中写入 commit 标记,标识本次事务被成功提交了。
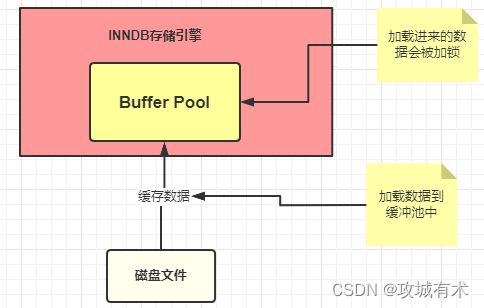
6.2.1 Buffer Pool 缓冲池
缓冲池 Buffer Pool,是InnoDB非常重要的组件。MySQL 的数据最终是存储在磁盘中的,有了 Buffer Pool,第一次查询时就会将查询结果存到Buffer Pool,之后再有请求时就会先从缓冲池中查询,没查到再去磁盘中I/O查找,然后在放到 Buffer Pool 中。
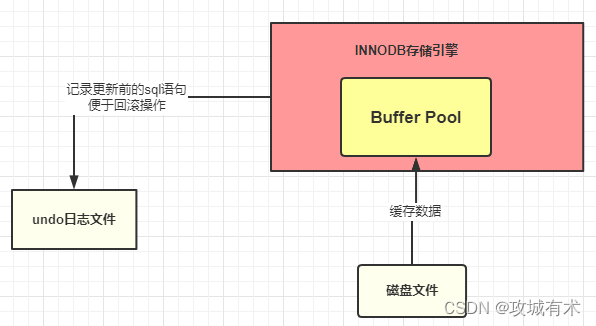
6.2.2 undo 日志文件
在准备更新一条语句的时候,该条语句已经被加载到 Buffer pool 中了,实际上这里还会同时在 undo 日志文件记录下更新前的值。
为什么要记录更新前的值?
Innodb 存储引擎的最大特点就是支持事务,如果本次更新失败,也就是事务提交失败,那么该事务中的所有的操作都必须回滚到执行前的样子,也就是说当事务失败的时候,也不会对原始数据有影响
6.2.3 redo 日志文件
- redo log buffer:内存缓存,记录将要做的一些操作。
- redo log:磁盘文件,记录数据被修改后的样子。
MySQL 为了提高效率,会将更新操作先放在内存中去完成,然后会在事务提交后 将其持久化到磁盘日志文件中。
知识补充:
- 如果 redo log Buffer 刷入磁盘前,MySQL宕机了,缓存会丢失,没关系,因为 MySQL 会认为本次事务是失败的,所以数据依旧是更新前的样子,没有任何影响。
- 如果 redo log Buffer 刷入磁盘后,MySQL宕机了,缓存会丢失,也没关系,因为 redo log buffer 中的数据已经被写入到磁盘redo log了,下次重启时 MySQL 会将 redo log 文件内容恢复到 Buffer Pool 中(和 Redis 的持久化机制类似,Redis 启动时会检查 RDB 或者 AOF 或者两者都检查,根据持久化的文件将数据恢复到内存中)。
刷入磁盘参数设置:
- 通过 innodb_flush_log_at_trx_commit 参数设置刷入磁盘,0 表示不刷入磁盘,1 表示立即刷入磁盘,2 表示先刷到 os cache)
6.2.4 bin log文件
bin log 记录对数据库的整个修改操作(对主从复制非常有用)
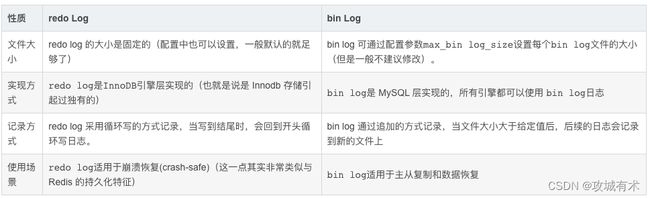
-
bin log刷盘策略
可以通过sync_bin log修改策略。
为0表示:提交事务后,先写入os cache,数据不会直接到磁盘中,如果宕机,bin log数据会丢失。
建议将sync_bin log设置为 1 表示直接将数据写入到磁盘文件中。 -
bin log在redo log中被记录
提交事务时,MySQL还会:(1)将本次修改的数据记录到 bin log文件中;(2)将本次修改的bin log文件名和修改的内容在bin log中的位置记录到redo log中;(3)在redo log中写入 commit 标记,标识本次事务被成功提交了。
如果数据刚被写入到bin log文件,数据库宕机了,数据会丢失吗?——不会丢失
- 只要redo log最后没有 commit 标记,就说明本次的事务是失败的,但是数据已经被记录到redo log的磁盘文件中了,MySQL 重启时,会将 redo log 中的数据恢复(加载)到Buffer Pool。
6.2.5 后台线程
疑问:上面仅描述了在内存中的更新操作,哪怕是宕机又恢复了也仅是将更新后的记录加载到Buffer Pool中,这时 MySQL 数据库中的这条记录依旧是旧值,内存数据依旧是脏数据,MySQL怎么保持内存和数据库表数据统一的呢?
解答:MySQL 有个后台线程,它会在某个时机将Buffer Pool 中的脏数据刷到磁盘表中,保持内存和数据库数据统一。