【go语言学习笔记】03 Go 语言深入理解
文章目录
-
- 一、指针详解
-
- 1. 指针的声明和定义
- 2. 指针的操作
-
- 2.1 获取指针指向的值
- 2.2 修改指针指向的值
- 2.3 给指针变量分配内存
- 3. 指针接收者
- 4. 什么情况下使用指针
- 5. 指向接口的指针
- 二、参数传递
-
- 1. 值类型
- 2. 指针类型
- 3. 引用类型
-
- 3.1 map
- 3.2 chan
- 4. 类型的零值
- 三、内存分配
-
- 1. 变量
-
- 1.1 声明
- 1.2 赋值
- 2. new 函数
- 3. 指针变量初始化工厂函数
- 4. make 函数
- 四、运行时反射
-
- 1. 反射
-
- 1.1 reflect.Value 和 reflect.Type
- 1.2 reflect.Value
-
- 1.2.1 reflect.Value 结构体定义
- 1.2.2 reflect.Value 与原始类型互转
- 1.2.3 修改对应的值
- 1.2.4 获取对应的底层类型
- 1.3 reflect.Type
-
- 1.3.1 reflect.Type 接口定义
- 1.3.2 遍历结构体的字段和方法
- 1.3.3 是否实现某接口
- 1.4 例子:通过反射调用结构体方法
- 2. 字符串和结构体互转
-
- 2.1 JSON 和 Struct 互转
- 2.2 Struct Tag
- 2.3 Struct 转 JSON 示例
- 3. 反射定律
- 五、非类型安全
-
- 1. 指针类型转换
- 2. unsafe.Pointer(指针类型转换)
- 3. uintptr 指针类型(指针运算)
- 4. 指针转换规则
- 5. unsafe.Sizeof
- 6. unsafe.Alignof
-
- 6.1 内存对齐
- 6.2 unsafe.Alignof 函数
- 六、SliceHeader
-
- 1. 数组
- 2. 切片
-
- 2.1 动态扩容
- 2.2 数据结构
- 2.3 高效的原因
- 3. string 和 []byte 互转
一、指针详解
1. 指针的声明和定义
在 Go 语言中,获取一个变量的指针非常容易,使用取地址符 & 就可以
func main() {
name:="小明"
nameP:=&name//取地址
fmt.Println("name变量的值为:",name)
fmt.Println("name变量的内存地址为:",nameP)
}
指针类型非常廉价,只占用 4 个或者 8 个字节的内存大小。
在 Go 语言中使用类型名称前加 * 的方式,即可表示一个对应的指针类型。比如 int 类型的指针类型是 *int,float64 类型的指针类型是 *float64,自定义结构体 A 的指针类型是 *A。总之,指针类型就是在对应的类型前加 * 号。
不同的指针类型是无法相互赋值的,比如你不能对一个 string 类型的变量取地址然后赋值给 *int指针类型,编译器会提示你 Cannot use ‘&name’ (type *string) as type *int in assignment。
声明一个指针类型的变量外,也可以使用 var 关键字声明。
var intP *int
intP = &name //指针类型不同,无法赋值
通过 var 声明的指针变量是不能直接赋值和取值的,因为这时候它仅仅是个变量,还没有对应的内存地址,它的值是 nil。
和普通类型不一样的是,指针类型还可以通过内置的 new 函数来声明,如下所示:
intP1:=new(int)
内置的 new 函数有一个参数,可以传递类型给它。它会返回对应的指针类型,比如上述示例中会返回一个 *int 类型的 intP1。
2. 指针的操作
在 Go 语言中指针的操作无非是两种:一种是获取指针指向的值,一种是修改指针指向的值。
2.1 获取指针指向的值
nameV:=*nameP
fmt.Println("nameP指针指向的值为:",nameV)
要获取指针指向的值,只需要在指针变量前加 * 号即可。
2.2 修改指针指向的值
*nameP = "小明和小王" //修改指针指向的值
fmt.Println("nameP指针指向的值为:",*nameP)
fmt.Println("name变量的值为:",name)
上例中 nameP 指针指向的值和变量 name 的值都会被改变。因为变量 name 存储数据的内存就是指针 nameP 指向的内存,这块内存被 nameP 修改后,变量 name 的值也被修改了。
2.3 给指针变量分配内存
通过 var 关键字直接定义的指针变量是不能进行赋值操作的,因为它的值为 nil,也就是还没有指向的内存地址。
var intP *int
*intP =10
运行的时候会提示 invalid memory address or nil pointer dereference。
这时只需要通过 new 函数给它分配一块内存就可以了,如下所示:
var intP *int = new(int)
//更推荐简短声明法,这里是为了演示
//intP:=new(int)
3. 指针接收者
这个概念之前有过详细介绍,对于是否使用指针类型作为接收者,有以下几点参考:
- 如果接收者类型是 map、slice、channel 这类引用类型,不使用指针;
- 如果需要修改接收者,那么需要使用指针;
- 如果接收者是比较大的类型,可以考虑使用指针,因为内存拷贝廉价,所以效率高。
所以对于是否使用指针类型作为接收者,还需要根据实际情况考虑。
4. 什么情况下使用指针
指针的好处:
- 可以修改指向数据的值;
- 在变量赋值,参数传值的时候可以节省内存。
不过 Go 语言作为一种高级语言,在指针的使用上还是比较克制的。它在设计的时候就对指针进行了诸多限制,比如指针不能进行运行,也不能获取常量的指针。所以在思考是否使用时,也要保持克制的心态。
以下是几点使用指针的建议:
- 不要对 map、slice、channel 这类引用类型使用指针;
- 如果需要修改方法接收者内部的数据或者状态时,需要使用指针;
- 如果需要修改参数的值或者内部数据时,也需要使用指针类型的参数;
- 如果是比较大的结构体,每次参数传递或者调用方法都要内存拷贝,内存占用多,这时候可以考虑使用指针;
- 像 int、bool 这样的小数据类型没必要使用指针;
- 如果需要并发安全,则尽可能地不要使用指针,使用指针一定要保证并发安全;
- 指针最好不要嵌套,也就是不要使用一个指向指针的指针,虽然 Go 语言允许这么做,但是这会使你的代码变得异常复杂。
在 Go 语言的开发中要尽可能地使用值类型,而不是指针类型,因为值类型可以使开发变得更简单,并且也是并发安全的。
5. 指向接口的指针
值类型作为接收者实现了接口,那么它的指针类型也就实现了该接口。
type address struct {
province string
city string
}
func (addr address) String() string{
return fmt.Sprintf("the addr is %s%s",addr.province,addr.city)
}
func main() {
add := address{province: "北京", city: "北京"}
printString(add)
printString(&add)
}
func printString(s fmt.Stringer) {
fmt.Println(s.String())
}
基于以上结论,看是否可以定义一个指向接口的指针。如下所示:
var si fmt.Stringer =address{province: "上海",city: "上海"}
printString(si)
sip:=&si
printString(sip)
上例中无法把指向接口的指针 sip 作为参数传递给函数 printString,Go 语言的编译器会提示如下错误信息:
./main.go:42:13: cannot use sip (type *fmt.Stringer) as type fmt.Stringer in argument to printString:
*fmt.Stringer is pointer to interface, not interface
虽然指向具体类型的指针可以实现一个接口,但是指向接口的指针永远不可能实现该接口。
二、参数传递
在 Go 语言中,函数的参数传递只有值传递,而且传递的实参都是原始数据的一份拷贝。如果拷贝的内容是值类型的,那么在函数中就无法修改原始数据;如果拷贝的内容是指针(或者可以理解为引用类型 map、chan 等),那么就可以在函数中修改原始数据。
1. 值类型
在go语言中, struct、浮点型、整型、字符串、布尔、数组都是值类型。
2. 指针类型
指针类型的变量保存的值就是数据对应的内存地址,所以在函数参数传递是传值的原则下,拷贝的值也是内存地址。
3. 引用类型
引用类型包括 map 和 chan。
3.1 map
示例:
func main() {
m:=make(map[string]int)
m["小明"] = 18
fmt.Println("小明的年龄为",m["小明"])
modifyMap(m)
fmt.Println("小明的年龄为",m["小明"])
}
func modifyMap(p map[string]int) {
p["小明"] =20
}
输出如下:
小明的年龄为 18
小明的年龄为 20
在 Go 语言中,任何创建 map 的代码(不管是字面量还是 make 函数)最终调用的都是 runtime.makemap 函数。
用字面量或者 make 函数的方式创建 map,并转换成 makemap 函数的调用,这个转换是 Go 语言编译器自动帮我们做的。
从下面的代码可以看到,makemap 函数返回的是一个 *hmap 类型,也就是说返回的是一个指针,所以创建的 map 其实就是一个 *hmap。
// makemap implements Go map creation for make(map[k]v, hint).
func makemap(t *maptype, hint int, h *hmap) *hmap{
//省略无关代码
}
因为 Go 语言的 map 类型本质上就是 *hmap,所以根据替换的原则,刚刚定义的 modifyMap(p map) 函数其实就是 modifyMap(p *hmap)。这也是通过 map 类型的参数可以修改原始数据的原因,因为它本质上就是个指针。
修改上述示例,打印 map 类型的变量和参数对应的内存地址,如下面的代码所示:
func main(){
//省略其他没有修改的代码
fmt.Printf("main函数:m的内存地址为%p\n",m)
}
func modifyMap(p map[string]int) {
fmt.Printf("modifyMap函数:p的内存地址为%p\n",p)
//省略其他没有修改的代码
}
输出如下:
小明的年龄为 18
main函数:m的内存地址为0xc000060180
modifyMap函数:p的内存地址为0xc000060180
小明的年龄为 20
可以看到,它们的内存地址一模一样。Go 语言通过 make 函数或字面量的包装为我们省去了指针的操作,让我们可以更容易地使用 map。
这里的 map 可以理解为引用类型,但是它本质上是个指针,只是可以叫作引用类型而已。在参数传递时,它还是值传递,并不是其他编程语言中所谓的引用传递。
3.2 chan
chan 可以理解为引用类型,它本质上也是个指针。
func makechan(t *chantype, size int64) *hchan {
//省略无关代码
}
严格来说,Go 语言没有引用类型,但是可以把 map、chan 称为引用类型,这样便于理解。除了 map、chan 之外,Go 语言中的函数、接口、slice 切片都可以称为引用类型。
指针类型也可以理解为是一种引用类型。
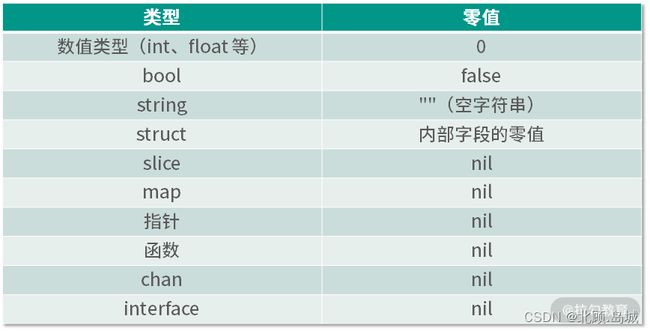
4. 类型的零值
在 Go 语言中,定义变量要么通过声明、要么通过 make 和 new 函数,不一样的是 make 和 new 函数属于显式声明并初始化。如果声明的变量没有显式声明初始化,那么该变量的默认值就是对应类型的零值。
从下面的表格可以看到,可以称为引用类型的零值都是 nil。
三、内存分配
在 C/C++ 这类语言中,内存是由开发者自己管理的,需要主动申请和释放,而在 Go 语言中则是由该语言自己管理的,开发者不用做太多干涉,只需要声明变量,Go 语言就会根据变量的类型自动分配相应的内存。
Go 语言程序所管理的虚拟内存空间会被分为两部分:堆内存和栈内存。栈内存主要由 Go 语言来管理,开发者无法干涉太多,程序的数据大部分都分配在堆内存上,一个程序的大部分内存占用也是在堆内存上。
Go 语言的内存垃圾回收是针对堆内存的垃圾回收。
new 函数只用于分配内存,并且把内存清零,也就是返回一个指向对应类型零值的指针。new 函数一般用于需要显式地返回指针的情况,不是太常用。
make 函数只用于 slice、chan 和 map 这三种内置类型的创建和初始化,因为这三种类型的结构比较复杂,比如 slice 要提前初始化好内部元素的类型,slice 的长度和容量等,这样才可以更好地使用它们。
1. 变量
1.1 声明
单纯声明一个变量,可以通过 var 关键字
var s string
该示例只是声明了一个变量 s,类型为 string,并没有对它进行初始化,所以它的值为 string 的零值,也就是 “”(空字符串)。
声明一个指针类型的变量如下:
var sp *string
它同样没有被初始化,所以它的值是 *string 类型的零值,也就是 nil。
1.2 赋值
如果在声明一个变量的时候就给这个变量赋值,这种操作就称为变量的初始化。如果要对一个变量初始化,可以有三种办法。
- 声明时直接初始化,比如 var s string = “小明”。
- 声明后再进行初始化,比如 s=“小明”(假设已经声明变量 s)。
- 使用 := 简单声明,比如 s:=“小明”。
在下面的示例代码中,声明了一个指针类型的变量 sp,然后把该变量的值修改为“小明”。
func main() {
var sp *string
*sp = "小明"
fmt.Println(*sp)
}
运行这些代码会看到如下错误信息:
panic: runtime error: invalid memory address or nil pointer dereference
这是因为指针类型的变量如果没有分配内存,就默认是零值 nil,它没有指向的内存,所以无法使用,强行使用就会得到以上 nil 指针错误。
而对于值类型来说,即使只声明一个变量,没有对其初始化,该变量也会有分配好的内存。比如在下面的示例中声明了一个变量 s,并没有对其初始化,但是可以通过 &s 获取它的内存地址。
func main() {
var s string
fmt.Printf("%p\n",&s)
}
如果要对一个变量赋值,这个变量必须有对应的分配好的内存,这样才可以对这块内存操作,完成赋值的目的。
其实不止赋值操作,对于指针变量,如果没有分配内存,取值操作一样会报 nil 异常,因为没有可以操作的内存。
所以一个变量必须要经过声明、内存分配才能赋值,才可以在声明的时候进行初始化。指针类型在声明的时候,Go 语言并没有自动分配内存,所以不能对其进行赋值操作,这和值类型不一样。
map 和 chan 也一样,因为它们本质上也是指针类型。
2. new 函数
对于上面的例子,可以使用 new 函数进行如下改造:
func main() {
var sp *string
sp = new(string)//关键点
*sp = "小明"
fmt.Println(*sp)
}
以上代码的关键点在于通过内置的 new 函数生成了一个 *string,并赋值给了变量 sp。现在再运行程序就正常了。
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type
内置函数 new 的作用就是根据传入的类型申请一块内存,然后返回指向这块内存的指针,指针指向的数据就是该类型的零值。
比如传入的类型是 string,那么返回的就是 string 指针,这个 string 指针指向的数据就是空字符串,如下所示:
sp1 = new(string)
fmt.Println(*sp1)//打印空字符串,也就是string的零值。
3. 指针变量初始化工厂函数
示例:
func NewPerson() *person{
p:=new(person)
p.name = "小明"
p.age = 20
return p
}
这个代码示例中的 NewPerson 函数就是工厂函数,除了使用 new 函数创建一个 person 指针外,还对它进行了初始化。通过 NewPerson 函数做一层包装,把内存分配(new 函数)和初始化(赋值)都完成了。
为了让自定义的工厂函数 NewPerson 更加通用,可以让它接受 name 和 age 参数,如下所示:
pp:=NewPerson("小明",20)
func NewPerson(name string,age int) *person{
p:=new(person)
p.name = name
p.age = age
return p
}
这些代码的效果和刚刚的示例一样,但是 NewPerson 函数更通用,因为可以传递不同的参数,构建出不同的 *person 变量。
4. make 函数
以 map 的创建为例,在使用 make 函数创建 map 的时候,其实调用的是 makemap 函数,如下所示:
// makemap implements Go map creation for make(map[k]v, hint).
func makemap(t *maptype, hint int, h *hmap) *hmap{
//省略无关代码
}
makemap 函数返回的是 *hmap 类型,而 hmap 是一个结构体,它的定义如下面的代码所示:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
可以看到, 平时使用的 map 关键字其实非常复杂,它包含 map 的大小 count、存储桶 buckets 等。要想使用这样的 hmap,不是简单地通过 new 函数返回一个 *hmap 就可以,还需要对其进行初始化,这就是 make 函数要做的事情,如下所示:
m:=make(map[string]int,10)
其实 make 函数就是 map 类型的工厂函数,它可以根据传递它的 K-V 键值对类型,创建不同类型的 map,同时可以初始化 map 的大小。
make 函数不只是 map 类型的工厂函数,还是 chan、slice 的工厂函数。它同时可以用于 slice、chan 和 map 这三种类型的初始化。
四、运行时反射
在反射中,reflect.Value 对应的是变量的值,如果需要进行和变量的值有关的操作,应该优先使用 reflect.Value,比如获取变量的值、修改变量的值等。reflect.Type 对应的是变量的类型,如果需要进行和变量的类型本身有关的操作,应该优先使用 reflect.Type,比如获取结构体内的字段、类型拥有的方法集等。
反射虽然很强大,可以简化编程、减少重复代码,但是过度使用会让你的代码变得复杂混乱。所以除非非常必要,否则尽可能少地使用它们。
1. 反射
和 Java 语言一样,Go 语言也有运行时反射,提供了一种可以在运行时操作任意类型对象的能力。比如查看一个接口变量的具体类型、看看一个结构体有多少字段、修改某个字段的值等。
Go 语言是静态编译类语言,比如在定义一个变量的时候,已经知道了它是什么类型。但是有些事情只有在运行时才知道。比如定义了一个函数,它有一个 interface{} 类型的参数,这就意味着调用者可以传递任何类型的参数给这个函数。在这种情况下,如果想知道调用者传递的是什么类型的参数,就需要用到反射。如果想知道一个结构体有哪些字段和方法,也需要反射。
以常用的函数 fmt.Println 为例,如下所示:
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
例子中 fmt.Println 的源代码有一个可变参数,类型为 interface{},这意味着可以传递零个或者多个任意类型参数给它,都能被正确打印。
1.1 reflect.Value 和 reflect.Type
在 Go 语言的反射定义中,任何接口都由两部分组成:接口的具体类型,以及具体类型对应的值。比如 var i int = 3,因为 interface{} 可以表示任何类型,所以变量 i 可以转为 interface{}。可以把变量 i 当成一个接口,那么这个变量在 Go 反射中的表示就是
interface{} 是空接口,可以表示任何类型,也就是说可以把任何类型转换为空接口,它通常用于反射、类型断言,以减少重复代码,简化编程。
在 Go 反射中,标准库提供了两种类型 reflect.Value 和 reflect.Type 来分别表示变量的值和类型,并且提供了两个函数 reflect.ValueOf 和 reflect.TypeOf 分别获取任意对象的 reflect.Value 和 reflect.Type。
代码示例:
func main() {
i:=3
iv:=reflect.ValueOf(i)
it:=reflect.TypeOf(i)
fmt.Println(iv,it)//3 int
}
1.2 reflect.Value
reflect.Value 可以通过函数 reflect.ValueOf 获得。
1.2.1 reflect.Value 结构体定义
在 Go 语言中,reflect.Value 被定义为一个 struct 结构体,它的定义如下面的代码所示:
type Value struct {
typ *rtype
ptr unsafe.Pointer
flag
}
可以看到 reflect.Value 结构体的字段都是私有的,也就是说只能使用 reflect.Value 的方法。
它的常用方法如下所示:
//针对具体类型的系列方法
//以下是用于获取对应的值
Bool
Bytes
Complex
Float
Int
String
Uint
CanSet //是否可以修改对应的值
// 以下是用于修改对应的值
Set
SetBool
SetBytes
SetComplex
SetFloat
SetInt
SetString
Elem //获取指针指向的值,一般用于修改对应的值
//以下Field系列方法用于获取struct类型中的字段
Field
FieldByIndex
FieldByName
FieldByNameFunc
Interface //获取对应的原始类型
IsNil //值是否为nil
IsZero //值是否是零值
Kind //获取对应的类型类别,比如Array、Slice、Map等
//获取对应的方法
Method
MethodByName
NumField //获取struct类型中字段的数量
NumMethod//类型上方法集的数量
Type//获取对应的reflect.Type
上述方法主要有三类:
- 一类用于获取和修改对应的值;
- 一类和 struct 类型的字段有关,用于获取对应的字段;
- 一类和类型上的方法集有关,用于获取对应的方法。
1.2.2 reflect.Value 与原始类型互转
reflect.Value 为我们提供了 Inteface 方法,如下面的代码所示:
func main() {
i:=3
//int to reflect.Value
iv:=reflect.ValueOf(i)
//reflect.Value to int
i1:=iv.Interface().(int)
fmt.Println(i1)
}
1.2.3 修改对应的值
(1)修改变量的值
func main() {
i:=3
ipv:=reflect.ValueOf(&i)
ipv.Elem().SetInt(4)
fmt.Println(i)
}
上述代码通过反射修改了一个变量。因为 reflect.ValueOf 函数返回的是一份值的拷贝,所以要传入变量的指针才可以。 因为传递的是一个指针,所以需要调用 Elem 方法找到这个指针指向的值,这样才能修改。 最后就可以使用 SetInt 方法修改值了。
修改一个变量的值的几个关键点:
- 传递指针(可寻址);
- 通过 Elem 方法获取指向的值,才可以保证值可以被修改。
reflect.Value 为我们提供了 CanSet 方法判断是否可以修改该变量。
(2)修改 struct 结构体字段的值
有以下步骤:
- 传递一个 struct 结构体的指针,获取对应的 reflect.Value;
- 通过 Elem 方法获取指针指向的值;
- 通过 Field 方法获取要修改的字段;
- 通过 Set 系列方法修改成对应的值。
代码示例:
func main() {
p:=person{Name: "小明",Age: 20}
ppv:=reflect.ValueOf(&p)
ppv.Elem().Field(0).SetString("张三")
fmt.Println(p)
}
type person struct {
Name string
Age int
}
(3)总结
总结一下通过反射修改一个值的规则。
- 可被寻址,通俗地讲就是要向 reflect.ValueOf 函数传递一个指针作为参数。
- 如果要修改 struct 结构体字段值的话,该字段需要是可导出的,而不是私有的,也就是该字段的首字母为大写。
- 记得使用 Elem 方法获得指针指向的值,这样才能调用 Set 系列方法进行修改。
1.2.4 获取对应的底层类型
底层类型对应的主要是基础类型,比如接口、结构体、指针…因为可以通过 type 关键字声明很多新的类型。比如在上面的例子中,变量 p 的实际类型是 person,但是 person 对应的底层类型是 struct 这个结构体类型,而 &p 对应的则是指针类型。
func main() {
p:=person{Name: "小明",Age: 20}
ppv:=reflect.ValueOf(&p)
fmt.Println(ppv.Kind())
pv:=reflect.ValueOf(p)
fmt.Println(pv.Kind())
}
结果输出:
ptr
struct
Kind 方法返回一个 Kind 类型的值,它是一个常量,有以下可供使用的值:
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
可以看到 Kind 常量列表已经包含了 Go 语言的所有底层类型。
1.3 reflect.Type
reflect.Value 可以用于与值有关的操作中,而如果是和变量类型本身有关的操作,则最好使用 reflect.Type,比如要获取结构体对应的字段名称或方法。
要反射获取一个变量的 reflect.Type,可以通过函数 reflect.TypeOf。
1.3.1 reflect.Type 接口定义
和 reflect.Value 不同,reflect.Type 是一个接口,所以只能使用它的方法。
以下是 reflect.Type 接口常用的方法。从这个列表来看,大部分都和 reflect.Value 的方法功能相同。
type Type interface {
Implements(u Type) bool
AssignableTo(u Type) bool
ConvertibleTo(u Type) bool
Comparable() bool
//以下这些方法和Value结构体的功能相同
Kind() Kind
Method(int) Method
MethodByName(string) (Method, bool)
NumMethod() int
Elem() Type
Field(i int) StructField
FieldByIndex(index []int) StructField
FieldByName(name string) (StructField, bool)
FieldByNameFunc(match func(string) bool) (StructField, bool)
NumField() int
}
其中几个特有的方法如下:
- Implements 方法用于判断是否实现了接口 u;
- AssignableTo 方法用于判断是否可以赋值给类型 u,其实就是是否可以使用 =,即赋值运算符;
- ConvertibleTo 方法用于判断是否可以转换成类型 u,其实就是是否可以进行类型转换;
- Comparable 方法用于判断该类型是否是可比较的,其实就是是否可以使用关系运算符进行比较。
1.3.2 遍历结构体的字段和方法
给前面示例中的 person 结构体增加一个方法 String,如下所示:
func (p person) String() string{
return fmt.Sprintf("Name is %s,Age is %d",p.Name,p.Age)
}
可以通过 NumField 方法获取结构体字段的数量,然后使用 for 循环,通过 Field 方法就可以遍历结构体的字段,并打印出字段名称。同理,遍历结构体的方法也是同样的思路,代码也类似,如下所示:
func main() {
p:=person{Name: "小明",Age: 20}
pt:=reflect.TypeOf(p)
//遍历person的字段
for i:=0;i<pt.NumField();i++{
fmt.Println("字段:",pt.Field(i).Name)
}
//遍历person的方法
for i:=0;i<pt.NumMethod();i++{
fmt.Println("方法:",pt.Method(i).Name)
}
}
输出结果:
字段: Name
字段: Age
方法: String
可以通过 FieldByName 方法获取指定的字段,也可以通过 MethodByName 方法获取指定的方法,这在需要获取某个特定的字段或者方法时非常高效,而不是使用遍历。
1.3.3 是否实现某接口
通过 reflect.Type 还可以判断是否实现了某接口。
func main() {
p:=person{Name: "小明",Age: 20}
pt:=reflect.TypeOf(p)
stringerType:=reflect.TypeOf((*fmt.Stringer)(nil)).Elem()
writerType:=reflect.TypeOf((*io.Writer)(nil)).Elem()
fmt.Println("是否实现了fmt.Stringer:",pt.Implements(stringerType))
fmt.Println("是否实现了io.Writer:",pt.Implements(writerType))
}
尽可能通过类型断言的方式判断是否实现了某接口,而不是通过反射。
运行上述示例,可以看到如下结果:
是否实现了fmt.Stringer: true
是否实现了io.Writer: false
1.4 例子:通过反射调用结构体方法
以 person 这个结构体类型为例,为它增加一个方法 Print,功能是打印一段文本,示例代码如下:
func (p person) Print(prefix string){
fmt.Printf("%s:Name is %s,Age is %d\n",prefix,p.Name,p.Age)
}
通过反射调用 Print 方法示例代码如下:
func main() {
p:=person{Name: "小明",Age: 20}
pv:=reflect.ValueOf(p)
//反射调用person的Print方法
mPrint:=pv.MethodByName("Print")
args:=[]reflect.Value{reflect.ValueOf("登录")}
mPrint.Call(args)
}
从示例中可以看到,要想通过反射调用一个方法,首先要通过 MethodByName 方法找到相应的方法。因为 Print 方法需要参数,所以需要声明参数,它的类型是 []reflect.Value,也就是示例中的 args 变量,最后就可以通过 Call 方法反射调用 Print 方法了。
上述代码和直接调用 Print 方法是一样的结果。
2. 字符串和结构体互转
2.1 JSON 和 Struct 互转
Go 语言的标准库有一个 json 包,通过它可以把 JSON 字符串转为一个 struct 结构体,也可以把一个 struct 结构体转为一个 json 字符串。
func main() {
p:=person{Name: "小明",Age: 20}
//struct to json
jsonB,err:=json.Marshal(p)
if err==nil {
fmt.Println(string(jsonB))
}
//json to struct
respJSON:="{\"Name\":\"李四\",\"Age\":40}"
json.Unmarshal([]byte(respJSON),&p)
fmt.Println(p)
}
通过 json.Marshal 函数,可以把一个 struct 转为 JSON 字符串。通过 json.Unmarshal 函数,可以把一个 JSON 字符串转为 struct。
上述代码输出为:
{"Name":"小明","Age":20}
Name is 李四,Age is 40
2.2 Struct Tag
struct tag 是一个添加在 struct 字段上的标记,使用它进行辅助,可以完成一些额外的操作,比如 json 和 struct 互转。在上面的示例中,如果想把输出的 json 字符串的 Key 改为小写的 name 和 age,可以通过为 struct 字段添加 tag 的方式,示例代码如下:
type person struct {
Name string `json:"name"`
Age int `json:"age"`
}
为 struct 字段添加 tag 的方法很简单,只需要在字段后面通过反引号把一个键值对包住即可。
json 作为 Key,是 Go 语言自带的 json 包解析 JSON 的一种约定,它会通过 json 这个 Key 找到对应的值,用于 JSON 的 Key 值。
通过 struct tag 指定了可以使用 name 和 age 作为 json 的 Key,代码就可以修改成如下所示:
respJSON:="{\"name\":\"李四\",\"age\":40}"
输出为:
{"name":"张三","age":20}
Name is 李四,Age is 40
在 JSON 和 struct 互转过程中, json 包是如何获得 tag 的?
//遍历person字段中key为json的tag
for i:=0;i<pt.NumField();i++{
sf:=pt.Field(i)
fmt.Printf("字段%s上,json tag为%s\n",sf.Name,sf.Tag.Get("json"))
}
要想获得字段上的 tag,就要先反射获得对应的字段,可以通过 Field 方法做到。该方法返回一个 StructField 结构体,它有一个字段是 Tag,存有字段的所有 tag。示例中要获得 Key 为 json 的 tag,所以只需要调用 sf.Tag.Get(“json”) 即可。
结构体的字段可以有多个 tag,用于不同的场景,比如 json 转换、bson 转换、orm 解析等。如果有多个 tag,要使用空格分隔。采用不同的 Key 可以获得不同的 tag,如下面的代码所示:
//遍历person字段中key为json、bson的tag
for i:=0;i<pt.NumField();i++{
sf:=pt.Field(i)
fmt.Printf("字段%s上,json tag为%s\n",sf.Name,sf.Tag.Get("json"))
fmt.Printf("字段%s上,bson tag为%s\n",sf.Name,sf.Tag.Get("bson"))
}
type person struct {
Name string `json:"name" bson:"b_name"`
Age int `json:"age" bson:"b_age"`
}
2.3 Struct 转 JSON 示例
func main() {
p:=person{Name: "小明",Age: 20}
pv:=reflect.ValueOf(p)
pt:=reflect.TypeOf(p)
//自己实现的struct to json
jsonBuilder:=strings.Builder{}
jsonBuilder.WriteString("{")
num:=pt.NumField()
for i:=0;i<num;i++{
jsonTag:=pt.Field(i).Tag.Get("json") //获取json tag
jsonBuilder.WriteString("\""+jsonTag+"\"")
jsonBuilder.WriteString(":")
//获取字段的值
jsonBuilder.WriteString(fmt.Sprintf("\"%v\"",pv.Field(i)))
if i<num-1{
jsonBuilder.WriteString(",")
}
}
jsonBuilder.WriteString("}")
fmt.Println(jsonBuilder.String())//打印json字符串
}
在上述示例中,自定义的 jsonBuilder 负责 json 字符串的拼接,通过 for 循环把每一个字段拼接成 json 字符串。运行以上代码,可以看到如下打印结果:
{"name":"小明","age":"20"}
json 字符串的转换只是 struct tag 的一个应用场景,完全可以把 struct tag 当成结构体中字段的元数据配置,使用它来做想做的任何事情,比如 orm 映射、xml 转换、生成 swagger 文档等。
3. 反射定律
反射是计算机语言中程序检视其自身结构的一种方法,它属于元编程的一种形式。反射灵活、强大,但也存在不安全。它可以绕过编译器的很多静态检查,如果过多使用便会造成混乱。为了帮助开发者更好地理解反射,Go 语言的作者在博客上总结了反射的三大定律。
- 任何接口值 interface{} 都可以反射出反射对象,也就是 reflect.Value 和 reflect.Type,通过函数 reflect.ValueOf 和 reflect.TypeOf 获得。
- 反射对象也可以还原为 interface{} 变量,也就是第 1 条定律的可逆性,通过 reflect.Value 结构体的 Interface 方法获得。
- 要修改反射的对象,该值必须可设置,也就是可寻址。
任何类型的变量都可以转换为空接口 intferface{},所以第 1 条定律中函数 reflect.ValueOf 和 reflect.TypeOf 的参数就是 interface{},表示可以把任何类型的变量转换为反射对象。在第 2 条定律中,reflect.Value 结构体的 Interface 方法返回的值也是 interface{},表示可以把反射对象还原为对应的类型变量。
五、非类型安全
顾名思义,unsafe 是不安全的。Go 将其定义为这个包名,也是为了尽可能地不使用它。不过虽然不安全,它也有优势,那就是可以绕过 Go 的内存安全机制,直接对内存进行读写。所以有时候出于性能需要,还是会冒险使用它来对内存进行操作。
unsafe 包里最常用的就是 Pointer 指针,通过它可以在 *T、uintptr 及 Pointer 三者间转换,从而实现自己的需求,比如零内存拷贝或通过 uintptr 进行指针运算,这些都可以提高程序效率。
unsafe 包里的功能虽然不安全,但很有用,比如指针运算、类型转换等,都可以提高性能。不过还是建议尽可能地不使用,因为它可以绕开 Go 语言编译器的检查,可能会因为操作失误而出现问题。当然如果是需要提高性能的必要操作,还是可以使用,比如 []byte 转 string,就可以通过 unsafe.Pointer 实现零内存拷贝。
1. 指针类型转换
Go 的设计者为了编写方便、提高效率且降低复杂度,将其设计成一门强类型的静态语言。强类型意味着一旦定义了,类型就不能改变;静态意味着类型检查在运行前就做了。同时出于安全考虑,Go 语言是不允许两个指针类型进行转换的。
使用 *T 作为一个指针类型,表示一个指向类型 T 变量的指针。为了安全的考虑,两个不同的指针类型不能相互转换,比如 *int 不能转为 *float64。
func main() {
i:= 10
ip:=&i
var fp *float64 = (*float64)(ip)
fmt.Println(fp)
}
这个代码在编译的时候,会提示 cannot convert ip (type * int) to type * float64,也就是不能进行强制转型。如果还是需要转换,就需要使用 unsafe 包里的 Pointer 了。
2. unsafe.Pointer(指针类型转换)
unsafe.Pointer 是一种特殊意义的指针,可以表示任意类型的地址,类似 C 语言里的 void* 指针,是全能型的。
正常情况下,*int 无法转换为 *float64,但是通过 unsafe.Pointer 做中转就可以了。
下面示例通过 unsafe.Pointer 把 *int 转换为 *float64,并且对新的 *float64 进行 3 倍的乘法操作,此时原来变量 i 的值也被改变了,变为 30。
func main() {
i:= 10
ip:=&i
var fp *float64 = (*float64)(unsafe.Pointer(ip))
*fp = *fp * 3
fmt.Println(i)
}
该例说明了通过 unsafe.Pointer 这个万能的指针,可以在 *T 之间做任何转换。
unsafe.Pointer 的源代码定义如下所示:
// ArbitraryType is here for the purposes of documentation
// only and is not actually part of the unsafe package.
// It represents the type of an arbitrary Go expression.
type ArbitraryType int
type Pointer *ArbitraryType
按 Go 语言官方的注释,ArbitraryType 可以表示任何类型(这里的 ArbitraryType 仅仅是文档需要,不用太关注它本身,只要记住可以表示任何类型即可)。 而 unsafe.Pointer 又是 *ArbitraryType,也就是说 unsafe.Pointer 是任何类型的指针,也就是一个通用型的指针,足以表示任何内存地址。
3. uintptr 指针类型(指针运算)
uintptr 也是一种指针类型,它足够大,可以表示任何指针。它的类型定义如下所示:
// uintptr is an integer type that is large enough
// to hold the bit pattern of any pointer.
type uintptr uintptr
设计 uintptr 类型是因为 unsafe.Pointer 不能进行运算,比如不支持 +(加号)运算符操作,但是 uintptr 可以。通过它,可以对指针偏移进行计算,这样就可以访问特定的内存,达到对特定内存读写的目的,这是真正内存级别的操作。
下面的代码通过指针偏移修改了 struct 结构体内的字段。
func main() {
p :=new(person)
//Name是person的第一个字段不用偏移,即可通过指针修改
pName:=(*string)(unsafe.Pointer(p))
*pName="小明"
//Age并不是person的第一个字段,所以需要进行偏移,这样才能正确定位到Age字段这块内存,才可以正确的修改
pAge:=(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(p))+unsafe.Offsetof(p.Age)))
*pAge = 20
fmt.Println(*p)
}
type person struct {
Name string
Age int
}
这个示例不是通过直接访问相应字段的方式对 person 结构体字段赋值,而是通过指针偏移找到相应的内存,然后对内存操作进行赋值。
详细操作步骤如下:
- 先使用 new 函数声明一个 *person 类型的指针变量 p。
- 然后把 *person 类型的指针变量 p 通过 unsafe.Pointer,转换为 *string 类型的指针变量 pName。
- 因为 person 这个结构体的第一个字段就是 string 类型的 Name,所以 pName 这个指针就指向 Name 字段(偏移为 0),对 pName 进行修改其实就是修改字段 Name 的值。
- 因为 Age 字段不是 person 的第一个字段,要修改它必须要进行指针偏移运算。所以需要先把指针变量 p 通过 unsafe.Pointer 转换为 uintptr,这样才能进行地址运算。既然要进行指针偏移,那么要偏移多少呢?这个偏移量可以通过函数 unsafe.Offsetof 计算出来,该函数返回的是一个 uintptr 类型的偏移量,有了这个偏移量就可以通过 + 号运算符获得正确的 Age 字段的内存地址了,也就是通过 unsafe.Pointer 转换后的 *int 类型的指针变量 pAge。
- 然后需要注意的是,如果要进行指针运算,要先通过 unsafe.Pointer 转换为 uintptr 类型的指针。指针运算完毕后,还要通过 unsafe.Pointer 转换为真实的指针类型(比如示例中的 *int 类型),这样可以对这块内存进行赋值或取值操作。
- 有了指向字段 Age 的指针变量 pAge,就可以对其进行赋值操作,修改字段 Age 的值了。
上述示例输入如下:
{小明 20}
该示例主要是为了讲解 uintptr 指针运算,如果按照正常的编码,以上示例代码会和下面的代码结果一样。
func main() {
p :=new(person)
p.Name = "小明"
p.Age = 20
fmt.Println(*p)
}
指针运算的核心在于它操作的是一个个内存地址,通过内存地址的增减,就可以指向一块块不同的内存并对其进行操作,而且不必知道这块内存被起了什么名字(变量名)。
4. 指针转换规则
Go 语言中存在三种类型的指针,它们分别是:常用的 *T、unsafe.Pointer 及 uintptr。这三者的转换规则如下:
- 任何类型的 *T 都可以转换为 unsafe.Pointer;
- unsafe.Pointer 也可以转换为任何类型的 *T;
- unsafe.Pointer 可以转换为 uintptr;
- uintptr 也可以转换为 unsafe.Pointer。

可以发现,unsafe.Pointer 主要用于指针类型的转换,而且是各个指针类型转换的桥梁。uintptr 主要用于指针运算,尤其是通过偏移量定位不同的内存。
5. unsafe.Sizeof
Sizeof 函数可以返回一个类型所占用的内存大小,这个大小只与类型有关,和类型对应的变量存储的内容大小无关,比如 bool 型占用一个字节、int8 也占用一个字节。
通过 Sizeof 函数可以查看任何类型(比如字符串、切片、整型)占用的内存大小,示例代码如下:
fmt.Println(unsafe.Sizeof(true))
fmt.Println(unsafe.Sizeof(int8(0)))
fmt.Println(unsafe.Sizeof(int16(10)))
fmt.Println(unsafe.Sizeof(int32(10000000)))
fmt.Println(unsafe.Sizeof(int64(10000000000000)))
fmt.Println(unsafe.Sizeof(int(10000000000000000)))
fmt.Println(unsafe.Sizeof(string("小明")))
fmt.Println(unsafe.Sizeof([]string{"李四","张三"}))
对于整型来说,占用的字节数意味着这个类型存储数字范围的大小,比如 int8 占用一个字节,也就是 8bit,所以它可以存储的大小范围是 -128~~127,也就是 −2^(n-1) 到 2^(n-1)−1。其中 n 表示 bit,int8 表示 8bit,int16 表示 16bit,以此类推。
对于和平台有关的 int 类型,要看平台是 32 位还是 64 位,会取最大的。
一个 struct 结构体的内存占用大小,等于它包含的字段类型内存占用大小之和。
6. unsafe.Alignof
6.1 内存对齐
内存对齐是指计算机中数据类型在内存中的存储方式,也称为内存对齐规则。在计算机中,每个数据类型在内存中占用的字节数是固定的,例如int类型占用4个字节,float类型占用4个字节,double类型占用8个字节等等。在将这些数据类型存储到内存中时,系统需要确定每个数据类型在内存中的起始地址,以及后续数据的存储方式。
内存对齐的原则是:每个数据类型在内存中的起始地址必须是该数据类型字节数的整数倍。例如,int类型占用4个字节,那么它的起始地址必须是4的整数倍,double类型占用8个字节,那么它的起始地址必须是8的整数倍。如果不满足内存对齐原则,可能会导致程序出现未定义的行为,例如访问非法内存地址、内存泄漏等问题。
内存对齐的优点是可以提高数据读取的效率。当数据类型按照内存对齐规则存储时,可以保证每个数据类型的起始地址与它所占用的字节数是对齐的,这样可以有效地减少内存读写操作的次数,提高程序的运行效率。
需要注意的是,不同的编译器和处理器对内存对齐的处理方式可能会不同,因此在进行跨平台开发时,应该谨慎处理内存对齐问题。
6.2 unsafe.Alignof 函数
Go语言的规范并没有要求一个字段的声明顺序和内存中的顺序是一致的,所以理论上一个编译器可以随意地重新排列每个字段的内存位置。下面的三个结构体虽然有着相同的字段,但是第一种写法比另外的两个需要多50%的内存。
// 64-bit 32-bit
struct{ bool; float64; int16 } // 3 words 4words
struct{ float64; int16; bool } // 2 words 3words
struct{ bool; int16; float64 } // 2 words 3words
unsafe.Alignof 函数返回对应参数的类型需要对齐的倍数. 和 Sizeof 类似, Alignof 也是返回一个常量表达式, 对应一个常量. 通常情况下布尔和数字类型需要对齐到它们本身的大小(最多8个字节), 其它的类型对齐到机器字大小.
unsafe.Offsetof 函数的参数必须是一个字段 x.f, 然后返回 f 字段相对于 x 起始地址的偏移量, 包括可能的空洞。
示例:
var x struct {
a bool
b int16
c []int
}
下图显示了上面结构体变量 x在32位和64位机器上的典型的内存,灰色区域是空洞。
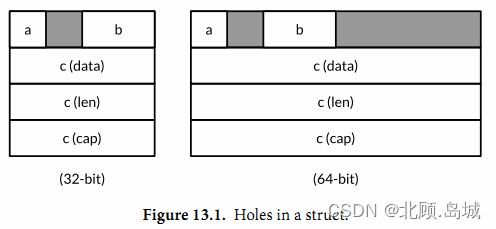
下面显示了对x和它的三个字段调用unsafe包相关函数的计算结果:
32位系统:
Sizeof(x) = 16 Alignof(x) = 4
Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0
Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2
Sizeof(x.c) = 12 Alignof(x.c) = 4 Offsetof(x.c) = 4
64位系统:
Sizeof(x) = 32 Alignof(x) = 8
Sizeof(x.a) = 1 Alignof(x.a) = 1 Offsetof(x.a) = 0
Sizeof(x.b) = 2 Alignof(x.b) = 2 Offsetof(x.b) = 2
Sizeof(x.c) = 24 Alignof(x.c) = 8 Offsetof(x.c) = 8
编译器已经对变量做了内存对齐,程序员可以通过调整成员变量顺序减少结构体占用大小,节省内存,对性能要求很高的场景还是有必要做的,如果对性能要求不那么高,记住一个大原则:将大的变量放在前面。
六、SliceHeader
1. 数组
数组的局限性:
- 一旦一个数组被声明,它的大小和内部元素的类型就不能改变,不能随意地向数组添加任意多个元素;
- 函数间的传参是值传递的,数组作为参数在各个函数之间被传递的时候,同样的内容就会被一遍遍地复制,这就会造成大量的内存浪费。
2. 切片
切片是对数组的抽象和封装,它的底层是一个数组存储所有的元素,但是它可以动态地添加元素,容量不足时还可以自动扩容,完全可以把切片理解为动态数组。在 Go 语言中,除了明确需要指定长度大小的类型需要数组来完成,大多数情况下都是使用切片的。
2.1 动态扩容
通过内置的 append 方法可以向一个切片中追加任意多个元素。
当通过 append 追加元素时,如果切片的容量不够,append 函数会自动扩容。比如上面的例子,打印出使用 append 前后的切片长度和容量,代码如下:
func main() {
ss:=[]string{"小明","张三"}
fmt.Println("切片ss长度为",len(ss),",容量为",cap(ss))
ss=append(ss,"李四","王五")
fmt.Println("切片ss长度为",len(ss),",容量为",cap(ss))
fmt.Println(ss)
}
运行这段代码,可以看到打印结果如下:
切片ss长度为 2 ,容量为 2
切片ss长度为 4 ,容量为 4
[小明 张三 李四 王五]
append 自动扩容的原理是新创建一个底层数组,把原来切片内的元素拷贝到新数组中,然后再返回一个指向新数组的切片。
2.2 数据结构
在 Go 语言中,切片是一个结构体,它的定义如下所示:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
SliceHeader 是切片在运行时的表现形式,它有三个字段 Data、Len 和 Cap。
- Data 用来指向存储切片元素的数组。
- Len 代表切片的长度。
- Cap 代表切片的容量。
通过这三个字段,就可以把一个数组抽象成一个切片,便于更好的操作,所以不同切片对应的底层 Data 指向的可能是同一个数组。
func main() {
a1:=[2]string{"小明","张三"}
s1:=a1[0:1]
s2:=a1[:]
//打印出s1和s2的Data值,是一样的
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&s2)).Data)
}
用 unsafe.Pointer 把它们转换为 *reflect.SliceHeader 指针,就可以打印出 Data 的值。
824634150744
824634150744
可以看到这两个切片共用一个数组,所以在切片赋值、重新进行切片操作时,使用的还是同一个数组,没有复制原来的元素。这样可以减少内存的占用,提高效率。
多个切片共用一个底层数组虽然可以减少内存占用,但是如果有一个切片修改内部的元素,其他切片也会受影响。所以在切片作为参数在函数间传递的时候要小心,尽可能不要修改原切片内的元素。
切片的本质是 SliceHeader,又因为函数的参数是值传递,所以传递的是 SliceHeader 的副本,而不是底层数组的副本。这时候切片的优势就体现出来了,因为 SliceHeader 的副本内存占用非常少,即使是一个非常大的切片(底层数组有很多元素),也顶多占用 24 个字节的内存,这就解决了大数组在传参时内存浪费的问题。
SliceHeader 三个字段的类型分别是 uintptr、int 和 int,在 64 位的机器上,这三个字段最多也就是 int64 类型,一个 int64 占 8 个字节,三个 int64 占 24 个字节内存。
要获取切片数据结构的三个字段的值,也可以不使用 SliceHeader,而是完全自定义一个结构体,只要字段和 SliceHeader 一样就可以了。
在下面的示例中,通过 unsfe.Pointer 转换成自定义的 *slice 指针,同样可以获取三个字段对应的值,甚至可以把字段的名称改为 d、l 和 c,也可以达到目的。
sh1:=(*slice)(unsafe.Pointer(&s1))
fmt.Println(sh1.Data,sh1.Len,sh1.Cap)
type slice struct {
Data uintptr
Len int
Cap int
}
还是尽可能地用 SliceHeader,因为这是 Go 语言提供的标准,可以保持统一,便于理解。
2.3 高效的原因
从集合类型的角度考虑,数组、切片和 map 都是集合类型,因为它们都可以存放元素,但是数组和切片的取值和赋值操作要更高效,因为它们是连续的内存操作,通过索引就可以快速地找到元素存储的地址。
map 的价值也非常大,因为它的 Key 可以是很多类型,比如 int、int64、string 等,但是数组和切片的索引只能是整数。
在数组和切片中,切片又是高效的,因为它在赋值、函数传参的时候,并不会把所有的元素都复制一遍,而只是复制 SliceHeader 的三个字段就可以了,共用的还是同一个底层数组。
示例:
func main() {
a1:=[2]string{"小明","张三"}
fmt.Printf("函数main数组指针:%p\n",&a1)
arrayF(a1)
s1:=a1[0:1]
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
sliceF(s1)
}
func arrayF(a [2]string){
fmt.Printf("函数arrayF数组指针:%p\n",&a)
}
func sliceF(s []string){
fmt.Printf("函数sliceF Data:%d\n",(*reflect.SliceHeader)(unsafe.Pointer(&s)).Data)
}
运行程序会打印如下结果:
函数main数组指针:0xc0000a6020
函数arrayF数组指针:0xc0000a6040
824634400800
函数sliceF Data:824634400800
同一个数组在 main 函数中的指针和在 arrayF 函数中的指针是不一样的,这说明数组在传参的时候被复制了,又产生了一个新数组。而 slice 切片的底层 Data 是一样的,这说明不管是在 main 函数还是 sliceF 函数中,这两个切片共用的还是同一个底层数组,底层数组并没有被复制。
切片的高效还体现在 for range 循环中,因为循环得到的临时变量也是个值拷贝,所以在遍历大的数组时,切片的效率更高。
具体来说,for range 遍历数组时会创建一个临时迭代器,它会按顺序访问数组中的所有元素。每次迭代时,该迭代器会将当前元素的值复制到新的内存空间中,然后将其传递给 for 循环体中的变量。
使用切片进行 for range 遍历时,不需要将所有元素拷贝到新的内存空间中是因为切片的底层结构是一个指向底层数组的指针、长度和容量三个属性的结构体。在 for range 遍历切片时,其实是遍历切片底层数组中的元素,而不是遍历切片本身。因此,不需要将所有元素拷贝到新的内存空间中,也不会创建新的临时迭代器。遍历过程中只需要将指向数组元素的指针不断向后移动,并访问指针所指向的元素即可。
因此,使用切片进行遍历可以提高代码的效率和性能。
切片基于指针的封装是它效率高的根本原因,因为可以减少内存的占用,以及减少内存复制时的时间消耗。
3. string 和 []byte 互转
Go 语言通过先分配一个内存再复制内容的方式,实现 string 和 []byte 之间的强制转换。现在通过 string 和 []byte 指向的真实内容的内存地址,来验证强制转换是采用重新分配内存的方式。如下面的代码所示:
s:="小明"
fmt.Printf("s的内存地址:%d\n", (*reflect.StringHeader)(unsafe.Pointer(&s)).Data)
b:=[]byte(s)
fmt.Printf("b的内存地址:%d\n",(*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)
s3:=string(b)
fmt.Printf("s3的内存地址:%d\n", (*reflect.StringHeader)(unsafe.Pointer(&s3)).Data)
上例打印出的内存地址都不一样,这说明虽然内容相同,但已经不是同一个字符串了,因为内存地址不同。
可以通过查看 runtime.stringtoslicebyte 和 runtime.slicebytetostring 这两个函数的源代码,了解关于 string 和 []byte 类型互转的具体实现。
其实 StringHeader 和 SliceHeader 一样,代表的是字符串在程序运行时的真实结构,StringHeader 的定义如下所示:
// StringHeader is the runtime representation of a string.
type StringHeader struct {
Data uintptr
Len int
}
也就是说,在程序运行的时候,字符串和切片本质上就是 StringHeader 和 SliceHeader。这两个结构体都有一个 Data 字段,用于存放指向真实内容的指针。所以打印出 Data 这个字段的值,就可以判断 string 和 []byte 强制转换后是不是重新分配了内存。
如果字符串非常大, []byte(s) 和 string(b) 这种强制转换会重新拷贝一份字符串的方式会导致内存开销大。既然是因为内存分配导致内存开销大,那么优化的思路应该是在不重新申请内存的情况下实现类型转换。
StringHeader 和 SliceHeader 这两个结构体的前两个字段一模一样,那么 []byte 转 string,就等于通过 unsafe.Pointer 把 *SliceHeader 转为 *StringHeader,也就是 *[]byte 转 *string,原理和上面讲的把切片转换成一个自定义的 slice 结构体类似。
在下面的示例中, s4 没有申请新内存(零拷贝),它和变量 b 使用的是同一块内存,因为它们的底层 Data 字段值相同,这样就节约了内存,也达到了 []byte 转 string 的目的。
s:="小明"
b:=[]byte(s)
//s3:=string(b)
s4:=*(*string)(unsafe.Pointer(&b))
SliceHeader 有 Data、Len、Cap 三个字段,StringHeader 有 Data、Len 两个字段,所以 *SliceHeader 通过 unsafe.Pointer 转为 *StringHeader 的时候没有问题,因为 *SliceHeader 可以提供 *StringHeader 所需的 Data 和 Len 字段的值。但是反过来却不行了,因为 *StringHeader 缺少 *SliceHeader 所需的 Cap 字段,需要补上一个默认值。
s:="小明"
//b:=[]byte(s)
sh:=(*reflect.SliceHeader)(unsafe.Pointer(&s))
sh.Cap = sh.Len
b1:=*(*[]byte)(unsafe.Pointer(sh))
通过 unsafe.Pointer 把 string 转为 []byte 后,不能对 []byte 修改,比如不可以进行 b1[0]=12 这种操作,会报异常,导致程序崩溃。这是因为在 Go 语言中 string 内存是只读的。
通过 unsafe.Pointer 进行类型转换,避免内存拷贝提升性能的方法在 Go 语言标准库中也有使用,比如 strings.Builder 这个结构体,它内部有 buf 字段存储内容,在通过 String 方法把 []byte 类型的 buf 转为 string 的时候,就使用 unsafe.Pointer 提高了效率,代码如下:
// String returns the accumulated string.
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
string 和 []byte 的互转是一个很好的利用 SliceHeader 结构体的示例,通过它可以实现零拷贝的类型转换,提升了效率,避免了内存浪费。